自从计算机出现以来,我们一直在尝试寻找计算机存储一些信息的方法,存储在计算机上的信息(也称为数据)有多种形式,数据变得如此重要,以至于信息现在已成为触手可及的商品。多年来数据以多种方
自从计算机出现以来,我们一直在尝试寻找计算机存储一些信息的方法,存储在计算机上的信息(也称为数据)有多种形式,数据变得如此重要,以至于信息现在已成为触手可及的商品。多年来数据以多种方式存储在计算机中,包括数据库、blob存储和其他方法,为了进行有效的业务分析,必须对现代应用程序创建的数据进行处理和分析,并且产生的数据量非常巨大!有效地存储数PB数据并拥有必要的工具来查询它以便使用它至关重要,只有这样对该数据的分析才能产生有意义的结果。
大数据是一门处理分析方法、有条不紊地从中提取信息或以其他方式处理对于典型数据处理应用程序软件而言过于庞大或复杂的数据量的方法的学科。为了处理现代应用程序产生的数据,大数据的应用是非常必要的,考虑到这一点,本博客旨在提供一个关于如何创建数据湖的小教程,该数据湖从应用程序的数据库中读取任何更改并将其写入数据湖中的相关位置,我们将为此使用的工具如下:
我们将要构建的数据湖架构如下:
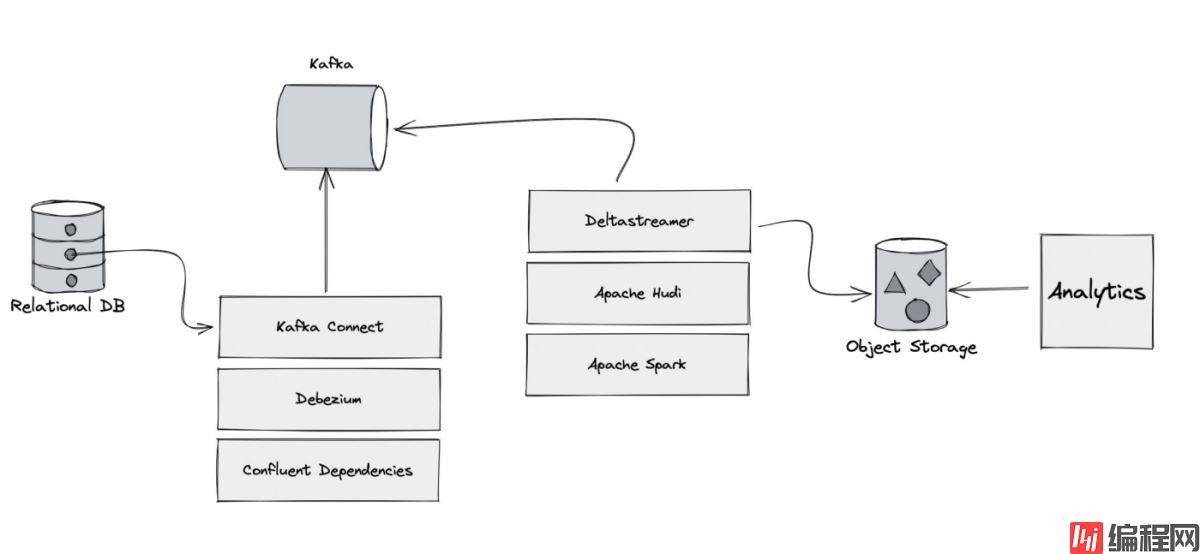
第一步是使用 Debezium 读取关系数据库中发生的所有更改,并将所有更改推送到 Kafka 集群。
Debezium 是一个用于变更数据捕获的开源分布式平台,Debezium 可以指向任何关系数据库,并且它可以开始实时捕获任何数据更改,它非常快速且实用,由红帽维护。
首先,我们将使用 Docker-compose 在我们的机器上设置 Debezium、mysql 和 Kafka,您也可以使用这些的独立安装,我们将使用 Debezium 提供给我们的 mysql 镜像,因为其中已经包含数据,在任何生产环境中都可以使用适当的 Kafka、MySQL 和 Debezium 集群,docker compose 文件如下:
version: '2'
services:
ZooKeeper:
image: debezium/zookeeper:${DEBEZIUM_VERSION}
ports:
- 2181:2181
- 2888:2888
- 3888:3888
kafka:
image: debezium/kafka:${DEBEZIUM_VERSION}
ports:
- 9092:9092
links:
- zookeeper
environment:
- ZOOKEEPER_CONNECT=zookeeper:2181
mysql:
image: debezium/example-mysql:${DEBEZIUM_VERSION}
ports:
- 3307:3306
environment:
- MYSQL_ROOT_PASSWord=${MYSQL_ROOT_PASS}
- MYSQL_USER=${MYSQL_USER}
- MYSQL_PASSWORD=${MYSQL_USER_PASS}
schema-reGIStry:
image: confluentinc/cp-schema-registry
ports:
- 8181:8181
- 8081:8081
environment:
- SCHEMA_REGISTRY_KAFKASTORE_BOOTSTRAP_SERVERS=kafka:9092
- SCHEMA_REGISTRY_KAFKASTORE_CONNECTION_URL=zookeeper:2181
- SCHEMA_REGISTRY_HOST_NAME=schema-registry
- SCHEMA_REGISTRY_LISTENERS=Http://schema-registry:8081
links:
- zookeeper
connect:
image: debezium/connect:${DEBEZIUM_VERSION}
ports:
- 8083:8083
links:
- kafka
- mysql
- schema-registry
environment:
- BOOTSTRAP_SERVERS=kafka:9092
- GROUP_ID=1
- CONFIG_STORAGE_TOPIC=my_connect_configs
- OFFSET_STORAGE_TOPIC=my_connect_offsets
- STATUS_STORAGE_TOPIC=my_connect_statuses
- KEY_CONVERTER=io.confluent.connect.avro.AvroConverter
- VALUE_CONVERTER=io.confluent.connect.avro.AvroConverter
- INTERNAL_KEY_CONVERTER=org.apache.kafka.connect.JSON.jsonConverter
- INTERNAL_VALUE_CONVERTER=org.apache.kafka.connect.json.JsonConverter
- CONNECT_KEY_CONVERTER_SCHEMA_REGISTRY_URL=http://schema-registry:8081
- CONNECT_VALUE_CONVERTER_SCHEMA_REGISTRY_URL=http://schema-registry:8081
DEBEZIUM_VERSION 可以设置为 1.8。 此外请确保设置 MYSQL_ROOT_PASS、MYSQL_USER 和 MYSQL_PASSWORD。
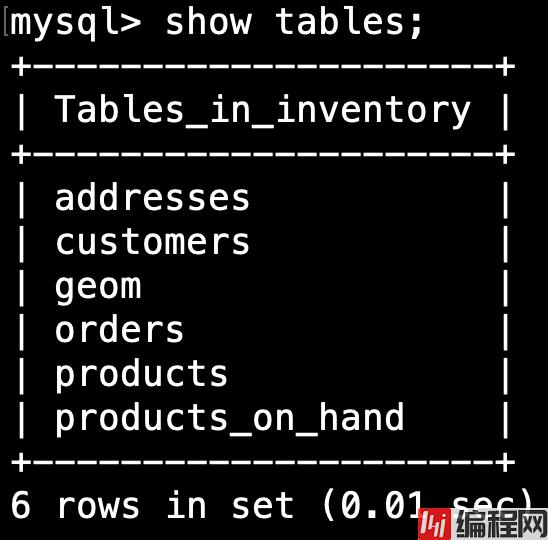
在我们继续之前,我们将查看 debezium 镜像提供给我们的数据库 inventory 的结构,进入数据库的命令行:
docker-compose -f docker-compose-avro-mysql.yaml exec mysql bash -c 'mysql -u $MYSQL_USER -p$MYSQL_PASSWORD inventory'在 shell 内部,我们可以使用 show tables 命令。 输出应该是这样的:
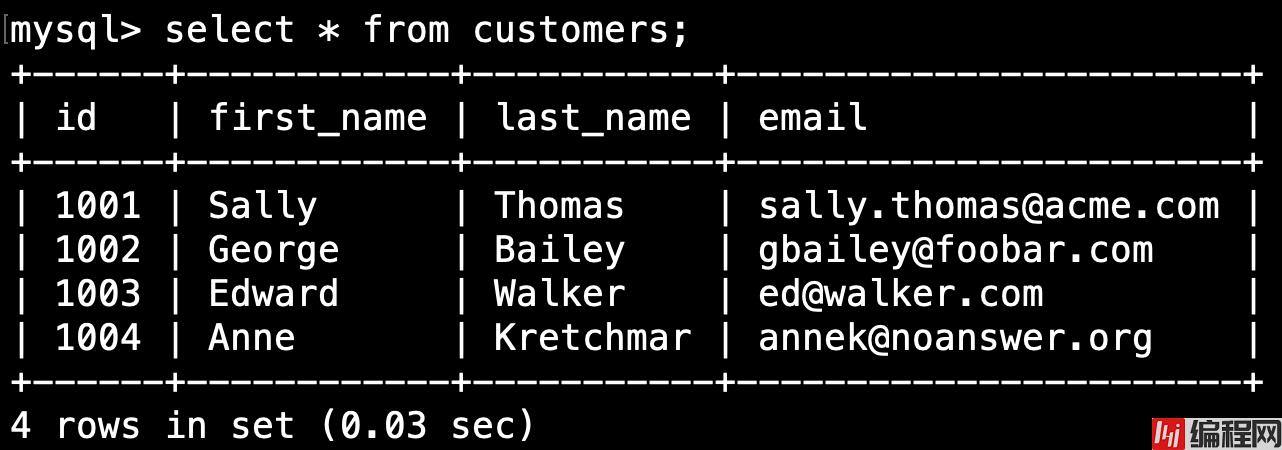
我们可以通过 select * from customers 命令来查看客户表的内容。 输出应该是这样的:
现在在创建容器后,我们将能够为 Kafka Connect 激活 Debezium 源连接器,我们将使用的数据格式是 Avro 数据格式,Avro 是在 Apache 的 hadoop 项目中开发的面向行的远程过程调用和数据序列化框架。它使用 JSON 来定义数据类型和协议,并以紧凑的二进制格式序列化数据。
让我们用我们的 Debezium 连接器的配置创建另一个文件。
{
"name": "inventory-connector",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"tasks.max": "1",
"database.hostname": "mysql",
"database.port": "3306",
"database.user": "MYSQL_USER",
"database.password": "MYSQL_PASSWORD",
"database.server.id": "184054",
"database.server.name": "dbserver1",
"database.include.list": "inventory",
"database.history.kafka.bootstrap.servers": "kafka:9092",
"database.history.kafka.topic": "schema-changes.inventory",
"key.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"key.converter.schema.registry.url": "http://schema-registry:8081",
"value.converter.schema.registry.url": "http://schema-registry:8081"
}
}
正如我们所看到的,我们已经在其中配置了数据库的详细信息以及要从中读取更改的数据库,确保将 MYSQL_USER 和 MYSQL_PASSWORD 的值更改为您之前配置的值,现在我们将运行一个命令在 Kafka Connect 中注册它,命令如下:
curl -i -X POST -H "Accept:application/json" -H "Content-type:application/json" http://localhost:8083/connectors/ -d @register-mysql.json
现在,Debezium 应该能够从 Kafka 读取数据库更改。
下一步涉及使用 Spark 和 Hudi 从 Kafka 读取数据,并将它们以 Hudi 文件格式放入 Google Cloud Storage Bucket。 在我们开始使用它们之前,让我们了解一下 Hudi 和 Spark 是什么。
Apache Hudi 是一个开源数据管理框架,用于简化增量数据处理和数据管道开发。 该框架更有效地管理数据生命周期等业务需求并提高数据质量。 Hudi 使您能够在基于云的数据湖上管理记录级别的数据,以简化更改数据捕获 (CDC) 和流式数据摄取,并帮助处理需要记录级别更新和删除的数据隐私用例。 Hudi 管理的数据集使用开放存储格式存储在云存储桶中,而与 Presto、Apache Hive 和/或 Apache Spark 的集成使用熟悉的工具提供近乎实时的更新数据访问
Apache Spark 是用于大规模数据处理的开源统一分析引擎。 Spark 为具有隐式数据并行性和容错性的集群编程提供了一个接口。 Spark 代码库最初是在加州大学伯克利分校的 AMPLab 开发的,后来被捐赠给了 Apache 软件基金会,该基金会一直在维护它。
现在,由于我们正在 Google Cloud 上构建解决方案,因此最好的方法是使用 Google Cloud Dataproc。 Google Cloud Dataproc 是一种托管服务,用于处理大型数据集,例如大数据计划中使用的数据集。 Dataproc 是 Google 的公共云产品 Google Cloud PlatfORM 的一部分。 Dataproc 帮助用户处理、转换和理解大量数据。
在 Google Dataproc 实例中,预装了 Spark 和所有必需的库。 创建实例后,我们可以在其中运行以下 Spark 作业来完成我们的管道:
spark-submit \
--packages org.apache.hudi:hudi-spark3.1.2-bundle_2.12:0.10.1,org.apache.spark:spark-avro_2.12:3.1.2 \
--master yarn --deploy-mode client \
--class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer /usr/lib/hadoop/hudi-packages/hudi-utilities-bundle_2.12-0.10.1.jar \
--table-type COPY_ON_WRITE --op UPSERT \
--target-base-path gs://your-data-lake-bucket/hudi/customers \
--target-table hudi_customers --continuous \
--min-sync-interval-seconds 60 \
--source-class org.apache.hudi.utilities.sources.debezium.MysqlDebeziumSource \
--source-ordering-field _event_origin_ts_ms \
--hoodie-conf schema.registry.url=http://localhost:8081 \
--hoodie-conf hoodie.deltastreamer.schemaprovider.registry.url=http://localhost:8081/subjects/dbserver1.inventory.customers-value/versions/latest \
--hoodie-conf hoodie.deltastreamer.source.kafka.topic=dbserver1.inventory.customers \
--hoodie-conf bootstrap.servers=localhost:9092 \
--hoodie-conf auto.offset.reset=earliest \
--hoodie-conf hoodie.datasource.write.recordkey.field=id \
--hoodie-conf hoodie.datasource.write.partitionpath.field=id \
这将运行一个 spark 作业,该作业从我们之前推送到的 Kafka 中获取数据并将其写入 Google Cloud Storage Bucket。 我们必须指定 Kafka 主题、Schema Registry URL 和其他相关配置。
可以通过多种方式构建数据湖。 我试图展示如何使用 Debezium、Kafka、Hudi、Spark 和 Google Cloud 构建数据湖。 使用这样的设置,可以轻松扩展管道以管理大量数据工作负载! 有关每种技术的更多详细信息,可以访问文档。 可以自定义 Spark 作业以获得更细粒度的控制。 这里显示的 Hudi 也可以与 Presto、Hive 或 Trino 集成。 定制的数量是无穷无尽的。 本文提供了有关如何使用上述工具构建基本数据管道的基本介绍!
到此这篇关于基于Apache Hudi在Google云构建数据湖平台的文章就介绍到这了,更多相关Apache Hudi构建数据湖内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: 基于Apache Hudi在Google云构建数据湖平台的思路详解
本文链接: https://lsjlt.com/news/145167.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0