目录故障表现业务背景解决方案总结故障表现 一方面 :在阿里云控制台云数据库PolarDB对应的集群管理页面上,在诊断与优化模块里面的一键诊断会话管理中,发现某条update sql
一方面 :在阿里云控制台云数据库PolarDB对应的集群管理页面上,在诊断与优化模块里面的一键诊断会话管理中,发现某条update sql 执行时间非常久且非常频繁;
另一方面:业务监控系统中开始不断有业务执行时间发出告警信息提示,且告警的业务数据不断上升,部分操作影响客户使用。
由于业务操作涉及到的业务流比较复杂,对纯技术的分享来看,不是重点讨论的话,为了更有利于理解问题发生的原因,使用类比的方式,把复杂的业务类比成如下描述: 有数据库3张表,第一张表t_grandfather (爷表),第二张表为t_father(父表),第三张表t_grandson(子孙表),DDL如下:
CREATE TABLE `t_grandfather ` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`count` int(11) NOT NULL DEFAULT 0 COMMENT '子孙后代数量',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='老爷表';
CREATE TABLE `t_father ` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`grandfather_id` int(11) NOT NULL COMMENT '老爷表id',
PRIMARY KEY (`id`),
KEY `idx_grandfather_id` (`grandfather_id`),
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='老爸表';
CREATE TABLE `t_grandson` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`grandfather_id` int(11) NOT NULL COMMENT '老爷表id',
PRIMARY KEY (`id`),
KEY `idx_grandfather_id` (`grandfather_id`),
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='孙子表';三张表之间的业务逻辑关系为,先生成老爷表,然后这个老爷取很多老婆(业务),会不断的生娃,生一个娃就会生成一张老爸表,同时会更新老爷表的count=count+1,表示新增一个后代了,老爷的老婆(业务)在不断的生娃的时候,之前的生的娃也会有老婆,他们的老婆也会生娃,对老爷来说,就是它有了孙子(产生新的业务数据),那有了孙子之后也需要更新老爷表的count=count+1,表示新增一个后代了,以此类推,子子孙孙无穷尽也(业务数据不断生成) 如下图所示:
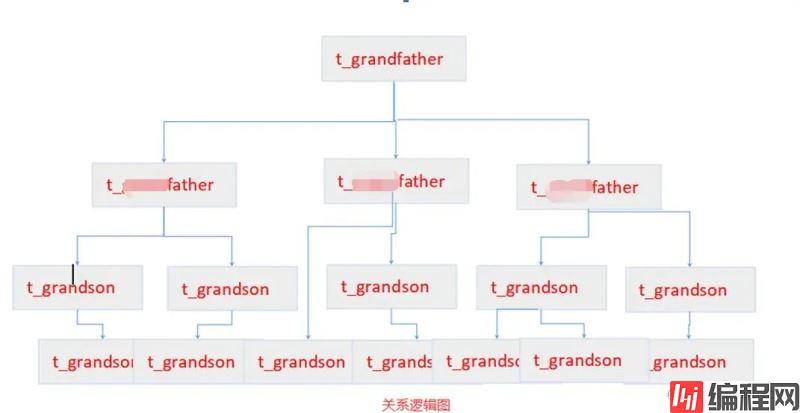
祖传代码的逻辑为,只要是t_father表和t_grandson有新增,就去更新t_grandfather。这个逻辑设计上问题不大,不过考虑到孙子表数据量很猛的时候,这里就会出现一个非常严重的性能问题。以下是业务摘取的一部分伪代码
public void doFatherBusiness (){
//do fatherBusiness baba .... 此处省
// 插入 t_father 表
if (fatherMapper.inster(father)){
//update t_grandfather set count=count+1 where id= #{grandfatherId}
grandfatherMapper.updateCount(father.getGrandfatherId ()) ;
}
}
public void doGrandsonBusiness (){
//do grandson baba .... 此处省略
// 插入 t_grandson 表
if(grandsonMapper.inster(grandson)){
//update t_grandfather set count=count+1 where id= #{grandfatherId}
grandfatherMapper.updateCount(grandson.getGrandfatherId());
}
} 当多个业务(线程)分别调用上面的方法时,都会对t_grandfather表的更新操作造成巨大的压力,特别是更新同一个id的情况下,mySQL Server内部对锁的竞争非常激烈。最后表现出来就如前文背景描述的一致。
1. 临时处理方案:
一方面,在阿里云控制台,对sql进行限流,在正常阻塞的会话,强制kill掉,让数据的线程不阻塞着,释放资源,另外一方面,在把接收请求的服务减少节点数,目的是减少业务数据量进入;
2. 长久方案
一方面更改掉上面的业务逻辑,插入t_grandson表和t_father表时,不在去更新t_grandfather表的count字段;另一方面,需要用到count统计需求时,全部切换成别的方式;
到此这篇关于一次Mysql update sql不当引起的生产故障的文章就介绍到这了,更多相关mysql update sql生产故障内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: 一次Mysql update sql不当引起的生产故障记录
本文链接: https://lsjlt.com/news/144743.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0