Python 官方文档:入门教程 => 点击学习
目录flush方法这里最终会调用AbstractUnsafe的flush方法跟进addFlush方法回到addFlush方法回到AbstractUnsafe的flush方法我们重点关
上一小节学习了writeAndFlush的write方法, 这一小节我们剖析flush方法
通过前面的学习我们知道, flush方法通过事件传递, 最终会传递到HeadContext的flush方法:
public void flush(ChannelHandlerContext ctx) throws Exception {
unsafe.flush();
}public final void flush() {
assertEventLoop();
ChannelOutboundBuffer outboundBuffer = this.outboundBuffer;
if (outboundBuffer == null) {
return;
}
outboundBuffer.addFlush();
flush0();
}这里首先也是拿到ChannelOutboundBuffer对象
然后我们看这一步:
outboundBuffer.addFlush();这一步同样也是调整ChannelOutboundBuffer的指针
public void addFlush() {
Entry entry = unflushedEntry;
if (entry != null) {
if (flushedEntry == null) {
flushedEntry = entry;
}
do {
flushed ++;
if (!entry.promise.setUncancellable()) {
int pending = entry.cancel();
decrementPendinGoutboundBytes(pending, false, true);
}
entry = entry.next;
} while (entry != null);
unflushedEntry = null;
}
}首先声明一个entry指向unflushedEntry, 也就是第一个未flush的entry
通常情况下unflushedEntry是不为空的, 所以进入if
再未刷新前flushedEntry通常为空, 所以会执行到flushedEntry = entry
也就是flushedEntry指向entry
经过上述操作, 缓冲区的指针情况如图所示:
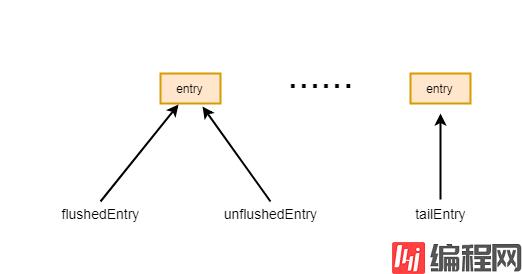
7-4-1
然后通过do-while将, 不断寻找unflushedEntry后面的节点, 直到没有节点为止
flushed自增代表需要刷新多少个节点
循环中我们关注这一步
decrementPendingOutboundBytes(pending, false, true);这一步也是统计缓冲区中的字节数, 但是是和上一小节的incrementPendingOutboundBytes正好是相反, 因为这里是刷新, 所以这里要减掉刷新后的字节数,
我们跟到方法中:
private void decrementPendingOutboundBytes(long size, boolean invokeLater, boolean notifyWritability) {
if (size == 0) {
return;
}
//从总的大小减去
long newWriteBufferSize = TOTAL_PENDING_SIZE_UPDATER.addAndGet(this, -size);
//直到减到小于某一个阈值32个字节
if (notifyWritability && newWriteBufferSize < channel.config().getWriteBufferLowWaterMark()) {
//设置写状态
setWritable(invokeLater);
}
}同样TOTAL_PENDING_SIZE_UPDATER代表缓冲区的字节数, 这里的addAndGet中参数是-size, 也就是减掉size的长度
再看 if (notifyWritability && newWriteBufferSize < channel.config().getWriteBufferLowWaterMark())
getWriteBufferLowWaterMark()代表写buffer的第水位值, 也就是32k, 如果写buffer的长度小于这个数, 就通过setWritable方法设置写状态
也就是通道由原来的不可写改成可写
遍历do-while循环结束之后, 将unflushedEntry指为空, 代表所有的entry都是可写的
经过上述操作, 缓冲区的指针情况如下图所示:

7-4-2
指针调整完之后, 我们跟到flush0()方法中:
protected void flush0() {
if (inFlush0) {
return;
}
final ChannelOutboundBuffer outboundBuffer = this.outboundBuffer;
if (outboundBuffer == null || outboundBuffer.isEmpty()) {
return;
}
inFlush0 = true;
if (!isActive()) {
try {
if (isOpen()) {
outboundBuffer.failFlushed(FLUSH0_NOT_YET_CONNECTED_EXCEPTION, true);
} else {
outboundBuffer.failFlushed(FLUSH0_CLOSED_CHANNEL_EXCEPTION, false);
}
} finally {
inFlush0 = false;
}
return;
}
try {
doWrite(outboundBuffer);
} catch (Throwable t) {
if (t instanceof IOException && config().isAutoClose()) {
close(voidPromise(), t, FLUSH0_CLOSED_CHANNEL_EXCEPTION, false);
} else {
outboundBuffer.failFlushed(t, true);
}
} finally {
inFlush0 = false;
}
}if (inFlush0) 表示判断当前flush是否在进行中, 如果在进行中, 则返回, 避免重复进入
跟到AbstractNIOByteChannel的doWrite方法中去:
protected void doWrite(ChannelOutboundBuffer in) throws Exception {
int writeSpinCount = -1;
boolean setOpWrite = false;
for (;;) {
//每次拿到当前节点
Object msg = in.current();
if (msg == null) {
clearOpWrite();
return;
}
if (msg instanceof ByteBuf) {
//转化成ByteBuf
ByteBuf buf = (ByteBuf) msg;
//如果没有可写的值
int readableBytes = buf.readableBytes();
if (readableBytes == 0) {
//移除
in.remove();
continue;
}
boolean done = false;
long flushedAmount = 0;
if (writeSpinCount == -1) {
writeSpinCount = config().getWriteSpinCount();
}
for (int i = writeSpinCount - 1; i >= 0; i --) {
//将buf写入到Socket里面
//localFlushedAmount代表向jdk底层写了多少字节
int localFlushedAmount = doWriteBytes(buf);
//如果一个字节没写, 直接break
if (localFlushedAmount == 0) {
setOpWrite = true;
break;
}
//统计总共写了多少字节
flushedAmount += localFlushedAmount;
//如果buffer全部写到jdk底层
if (!buf.isReadable()) {
//标记全写道
done = true;
break;
}
}
in.progress(flushedAmount);
if (done) {
//移除当前对象
in.remove();
} else {
break;
}
} else if (msg instanceof FileRegion) {
//代码省略
} else {
throw new Error();
}
}
incompleteWrite(setOpWrite);
}首先是一个无限for循环
Object msg = in.current() 这一步是拿到flushedEntry指向的entry中的msg
public Object current() {
Entry entry = flushedEntry;
if (entry == null) {
return null;
}
return entry.msg;
}这里直接拿到flushedEntry指向的entry中关联的msg, 也就是一个ByteBuf
回到doWrite方法:
如果msg为null, 说明没有可以刷新的entry, 则调用clearOpWrite()方法清除写标识
如果msg不为null, 则会判断是否是ByteBuf类型, 如果是ByteBuf, 就进入if块中的逻辑
if块中首先将msg转化为ByteBuf, 然后判断ByteBuf是否可读, 如果不可读, 则通过in.remove()将当前的byteBuf所关联的entry移除, 然后跳过这次循环进入下次循环
remove方法稍后分析, 这里我们先继续往下看
boolean done = false 这里设置一个标识, 标识刷新操作是否执行完成, 这里默认值为false代表走到这里没有执行完成
writeSpinCount = config().getWriteSpinCount() 这里是获得一个写操作的循环次数, 默认是16
然后根据这个循环次数, 进行循环的写操作
在循环中, 关注这一步:
int localFlushedAmount = doWriteBytes(buf);这一步就是将buf的内容写到channel中, 并返回写的字节数, 这里会调用NiOSocketChannel的doWriteBytes
protected int doWriteBytes(ByteBuf buf) throws Exception {
final int expectedWrittenBytes = buf.readableBytes();
return buf.readBytes(javaChannel(), expectedWrittenBytes);
}这里首先拿到buf的可读字节数, 然后通过readBytes将可读字节写入到jdk底层的channel中
回到doWrite方法:
将内容写的jdk底层的channel之后, 如果一个字节都没写, 说明现在channel可能不可写, 将setOpWrite设置为true, 用于标识写操作位, 并退出循环
如果已经写出字节, 则通过 flushedAmount += localFlushedAmount 累加写出的字节数
然后根据是buf是否没有可读字节数判断是否buf的数据已经写完, 如果写完, 将done设置为true, 说明写操作完成, 并退出循环
因为有时候不一定一次就能将byteBuf所有的字节写完, 所以这里会继续通过循环进行写出, 直到循环到16次
如果ByteBuf内容完全写完, 会通过in.remove()将当前entry移除掉
我们跟到remove方法中:
public boolean remove() {
//拿到当前第一个flush的entry
Entry e = flushedEntry;
if (e == null) {
clearNioBuffers();
return false;
}
Object msg = e.msg;
ChannelPromise promise = e.promise;
int size = e.pendingSize;
removeEntry(e);
if (!e.cancelled) {
ReferenceCountUtil.safeRelease(msg);
safeSuccess(promise);
decrementPendingOutboundBytes(size, false, true);
}
e.recycle();
return true;
}首先拿到当前的flushedEntry
我们重点关注removeEntry这步, 跟进去:
private void removeEntry(Entry e) {
if (-- flushed == 0) {
//位置为空
flushedEntry = null;
//如果是最后一个节点
if (e == tailEntry) {
//全部设置为空
tailEntry = null;
unflushedEntry = null;
}
} else {
//移动到下一个节点
flushedEntry = e.next;
}
}if (-- flushed == 0) 表示当前节点是否为需要刷新的最后一个节点, 如果是, 则flushedEntry指针设置为空
如果当前节点是tailEntry节点, 说明当前节点是最后一个节点, 将tailEntry和unflushedEntry两个指针全部设置为空
如果当前节点不是需要刷新的最后的一个节点, 则通过 flushedEntry = e.nex t这步将flushedEntry指针移动到下一个节点
以上就是flush操作的相关逻辑,更多关于Netty分布式flush方法刷新buffer队列的资料请关注编程网其它相关文章!
--结束END--
本文标题: Netty分布式flush方法刷新buffer队列源码剖析
本文链接: https://lsjlt.com/news/144296.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0