Python 官方文档:入门教程 => 点击学习
目录方法一方法二方法三补充方法一 import os import pandas as pd path = 'data/train/' img_label_list=[] test
import os
import pandas as pd
path = 'data/train/'
img_label_list=[]
testList = os.listdir(path)
for file in testList:
label='aa'
img_label_list.append([file, label])
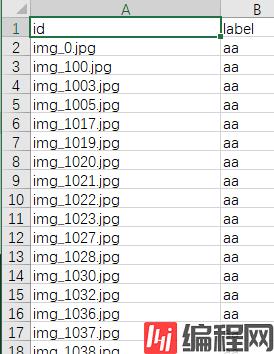
df1 = pd.DataFrame(data=img_label_list,
columns=['id', 'label'])
df1.to_csv('result.csv',index=False)
import os
import pandas as pd
path = 'data/train/'
img_list=[]
lable_list=[]
testList = os.listdir(path)
for file in testList:
img_list.append(file)
label='aa'
lable_list.append(label)
img_label_list2 = list(zip(img_list, lable_list))
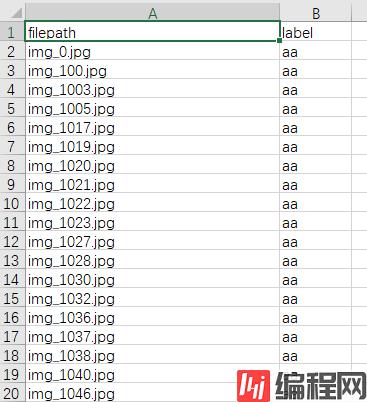
df3 = pd.DataFrame(data=img_label_list2,
columns=['filepath', 'label'])
df3.to_csv('result.csv',index=False)
import os
import pandas as pd
path = 'data/train/'
img_list=[]
lable_list=[]
testList = os.listdir(path)
for file in testList:
img_list.append(file)
label='aa'
lable_list.append(label)
df = pd.DataFrame({"filename": img_list, "label": lable_list})
df.to_csv('result.csv',index=False)

当然Pandas不仅可以实现CSV文件数据的保存,还能读写CSV文件,下面是实现的核心代码
使用pandas读取CSV
import pandas as pd
import csv
if name == '__main__':
# header=0——表示csv文件的第一行默认为dataframe数据的行名称,
# index_col=0——表示使用第0列作为dataframe的行索引,
# squeeze=True——表示如果文件只包含一列,则返回一个序列。
file_dataframe = pd.read_csv('../datasets/data_new_2/csv_file_name.csv', header=0, index_col=0, squeeze=True)
# 结果: 写CSV
stu1 = [lid, k, pre_count_data[k]]
# 打开文件,写模式为追加'a'
out = open('../results/write_file.csv', 'a', newline='')
# 设定写入模式
csv_write = csv.writer(out, dialect='excel')
# 写入具体内容
csv_write.writerow(stu1)到此这篇关于Pandas保存csv数据的三种方式详解的文章就介绍到这了,更多相关Pandas保存csv内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: Pandas保存csv数据的三种方式详解
本文链接: https://lsjlt.com/news/144152.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0