目录1算法讲解1.1何为遗传算法1.2遗传算法流程描述1.3关于为什么要用二进制码表示个体信息1.4目标函数值与适应值区别1.5关于如何将二进制码转化为变量数值1.6关于代码改进2M
这篇文章用了大量篇幅讲解了如何从零开始自己写一个遗传算法函数,主要是为了应对学生作业等情况,或者让大家对遗传算法有更充分的理解,如果要用于学术研究,最好还是使用自带遗传算法,之后可能会推出更多自带遗传算法工具箱的使用。
遗传、突变、自然选择、杂交,遗传算法是一种借鉴了进化生物学各类现象的进化算法。
看到一个很形象的比喻来描述各类进化算法的区别:
我们先随机生成几个个体(数值)。
计算这几个个体是否适合当前环境(带入某个评价函数后结果大不大)
记录一下最好的一个个体(记录一下局部最优解)。
依据适应度选入、淘汰一些个体(结果越好的数值有越大的概率不被扔掉,但是怕局部最优解所以还有有一定概率要被扔)。
交叉互换的方式进行变异(转换为十进制语言来说,例如我有两个数值13和15都还可以,新的两个数值我要在11-17区间内选俩)。
基因突变的方式进行变异(在范围内变异固然好,但是怕陷入局部最优解我还是要偶尔搞点大变异,哪怕是坏的变异) 。
进入下一轮循环,重新计算对当前环境适应程度继续前面的一系列步骤。
好多好多代后(迭代次数大于我们的设定)后,输出记录的每一轮最优解里面最好的一个。
这部分其实是借鉴了等位基因的概念,我们认为不同二进制码相同位置的数值为等位基因。两个二进制码链条相同位置交换我们可以看作交叉互换。
同时用二进制码还有可控变异的特点:假如我们有个二进制序列1111,转换为十进制就是15
若是我们将其变为1110,十进制变为14
若是我们将其变为1101,十进制变为13
变为1011,十进制变为11
变为0111,十进制变为7
也就是说,我们可以在大部分位置数据信息不变的情况下,各种幅度的改变我们的二进制序列代表的十进制信息。
适应值=目标函数值-f(x)下限 为了方便求概率才多了个这么个操作, 举几个例子:
综上我们看出Fmin的设置也需要有一定讲究,不能使适应值出现负数,也最好能使数据具有区分度,当然如果有更加合适的映射来代替线性映射也是极好(例如机器学习就常用sigmod函数来映射)。
假设我们有一个长度为4的二进制码,则其取值范围为0000至1111即[0,15];同时我们知道最优解范围是[2,3],我们只需要将二进制码转化为十进制,并且映射到最优解取值范围就好啦, 例如1011转换为十进制为11,从区间[0,15]映射到[2,3]即为, (11-0)/(15-0)*(3-2)+2=2.7333, 从这个转换方式我们可以看出:
二进制码越长,其可取值也就越多也就能把最优解区间划分的越细,也就能使结果越精确,(当然我们可以依据我们想要的精确度大体设置二进制码长度)
最优解区间范围一定要有!!而且一个好的最优解区间能够让我们在取较短的二进制码时依旧可以得到较为精确的结果。
虽然肯定比不上MATLAB自带的函数,但是对于各种自行构造的遗传算法代码,很多很多老版代码各种循环,这里能用向量运算就用向量运算,增加量程序的整洁度和速度。
这里先讲解一个简单的问题,之后可能会讲解遗传算法更详细应用。
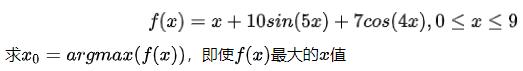
这里ga求的是最小值,因此我们取个相反数。
tic
f=@(x)-(x+10*sin(5*x)+7*cos(4*x));
x=ga(f,1,[],[],[],[],0,9)
-f(x)
toc
x = 7.8568
ans = 24.8554
历时 0.072996 秒。
使用代码:
tic
[Count,Result,BestMember]=Genetic1(24,6,@(x)x+10*sin(5*x)+7*cos(4*x),0,9,15,0.9,200)
toc参数:
关于各个参数更详细的说明往后看。
计算结果:

Count =200
Result =
7.8401,7.8048,7.8443,7.8403,7.8574,8.9649
24.8050,24.3683 ,24.8271,24.8066,11.1532,14.5649
BestMember =
7.8574
24.8553
历时 0.117459 秒。
即时取最大值,和自带函数算的也差不多。虽然结果不如自带函数稳定。画个图看看:

注:遗传算法毕竟是智能算法,算出的值并不一定是最优解,因而可以调整迭代次数的大小,变异概率,二进制串长度,个体数量等一系列数据来调整,正因为各个变量比较难以说明为何这样设置,所以各种建模比赛还是尽量少用这样的智能算法。
function [Count,Result,BestMember]=Genetic1(MumberLength,MemberNumber,FunctionFitness,MinX,MaxX,Fmin,MutationProbability,Gen)
% 参数解释:
% 参数名 参数类型 参数含义
% =========================================================================
% MumberLength | 数值 | 表示一个染色体位串的二进制长度
% MemberNumber | 数值 | 表示群体中染色体个数
% FunctionFitness | 字符串| 表示目标函数
% MinX | 数值 | 变量区间的下限
% MaxX | 数值 | 变量区间的上限
% Fmin | 数值 | 适应函数过程中给出目标函数可能最小值
% MutationProbability| 数值 | 变异概率
% Gen | 数值 | 遗传代数
% -------------------------------------------------------------------------
% Count | 数值 | 遗传代数
% Result | 数值 | 计算结果
% BestMember | 数值 | 最优个体及其适应值
global Count;Count=1;% 在之后的版本中可能会不支持函数输出作为全局变量(建议在改进工作中修改)
global CurrentBest; % 声明全局变量Count(代数)和CurrentBest(当前代数下的最优染色体)
% 随机地产生一个初始群体。
Population=PopulationInitialize(MumberLength,MemberNumber); PopulationCode=Population;
% 计算群体中每一个染色体的目标函数值,适应函数值,入选概率
PopulationFitness=Fitness(PopulationCode,FunctionFitness,MinX,MaxX,MumberLength);
PopulationFitnessF=FitnessF(PopulationFitness,Fmin);
PopulationProbability=Probability(PopulationFitnessF);
% 依据入选概率保留个体并记录最优个体
[Population,CurrentBest,EachGenMaxFitness]=Elitist(PopulationCode,PopulationFitness,MumberLength);
EachMaxFitness(Count)=EachGenMaxFitness;
MaxFitness(Count)=CurrentBest(MumberLength+1);
while Count<Gen
% 通过入选概率将入选概率大的个体选入种群,淘汰概率小的个体形成新群体
NewPopulation=Select(Population,PopulationProbability,MemberNumber);
Population=NewPopulation;
% 通过交叉互换形成新群体;
NewPopulation=Crossing(Population);
Population=NewPopulation;
% 通过变异形成新群体
NewPopulation=Mutation(Population,MutationProbability);
Population=NewPopulation;
% 计算新群体中每一染色体的目标函数值并借此计算出适应值与入选概率
PopulationFitness=Fitness(Population,FunctionFitness,MinX,MaxX,MumberLength);
PopulationFitnessF=FitnessF(PopulationFitness,Fmin);
PopulationProbability=Probability(PopulationFitnessF);
Count=Count+1;
% 替换当前最优个体并将最劣个体用最优个体替换
[NewPopulation,CurrentBest,EachGenMaxFitness]=Elitist(Population,PopulationFitness,MumberLength);
% EachMaxFitness,记录了第Count代中最优个体所对应的目标函数值;
% MaxFitness,前Count代中最优个体所对应的目标函数值;
EachMaxFitness(Count)=EachGenMaxFitness;
MaxFitness(Count)=CurrentBest(MumberLength+1);
Population=NewPopulation;
end
% 数据整理
Dim=size(Population);
Result=ones(2,Dim(1));
for ii=1:Dim(1)
Result(1,ii)=Translate(Population(ii,:),MinX,MaxX,MumberLength);
end
Result(2,:)=Fitness(Population,FunctionFitness,MinX,MaxX,MumberLength);
BestMember(1,1)=Translate(CurrentBest(1:MumberLength),MinX,MaxX,MumberLength);
BestMember(2,1)=CurrentBest(MumberLength+1);
% 绘图
close all
subplot(2,1,1)
plot(EachMaxFitness);
subplot(2,1,2)
plot(MaxFitness);
end
功能: 随机地产生一个初始群体。
输入变量:
输出变量: Poplation表示第一代群体。
原理: 生成MemberNumber个长度为MumberLength的0-1向量。
function Population=PopulationInitialize(MumberLength,MemberNumber)
Temporary=rand(MemberNumber,MumberLength);
Population=Temporary>=0.5;
% Population是一个逻辑矩阵(0-1矩阵,这么写为了方便),
% 在此函数中表示第一代群体,Population的每一行表示一个染色体
end
功能: 计算群体中每一个染色体的目标函数值。
输入参数:
输出变量:PopulationFitness表示每一染色体对应的目标函数值
原理:这部分就是把各个二进制码转换为十进制数(区间范围内),然后再带入到目标函数中算出数值。
说明: 由于懒,这里把网上大部分代码中的Translate函数和Transfer函数也合了进去,没必要为了两行运算多开俩函数吧。。。
function PopulationFitness=Fitness(PopulationCode,FunctionFitness,MinX,MaxX,MumberLength)
Dim=size(PopulationCode);
PopulationFitness=zeros(1,Dim(1));
for i=1:Dim(1)
% 转换为10进制
PopulationData=sum(PopulationCode(i,:).*(2.^(MumberLength-1:-1:0)));
% 映射到x取值范围
PopulationData=MinX+PopulationData*(MaxX-MinX)/(2^Dim(2)-1);
% 计算对应f(x)数值
PopulationFitness(i)=FunctionFitness(PopulationData);
end
end
功能: 计算每个染色体的适应函数值。
输入参数:PopulationFitness表示目标函数值;Fmin表示目标函数的可能的最小值;
输出参数: PopulationFitnessF表示每一染色体的适应函数值。
function PopulationFitnessF=FitnessF(PopulationFitness,Fmin)
% 若某一染色体的目标函数值大于Fmin,则置其适应函数值为其目标函数值-Fmin
% 若某一染色体的目标函数值小于Fmin,则置其适应函数值为0
PopulationFitnessF=PopulationFitness-Fmin;
PopulationFitnessF(PopulationFitnessF<0)=0;
end
这部分代码已经包含在Fitness函数内了,再写一遍是专门用来服务于最后的结果输出的。
function PopulationData=Translate(PopulationCode,MinX,MaxX,MumberLength)
Dim=size(PopulationCode);
PopulationData=sum(PopulationCode.*(2.^(MumberLength-1:-1:0)));
PopulationData=MinX+PopulationData*(MaxX-MinX)/(2^Dim(2)-1);
end
就是将适应值转换为概率,其方法就是除以所有适应值的和。
function PopulationProbability=Probability(PopulationFitnessF)
PopulationProbability=PopulationFitnessF./sum(PopulationFitnessF);
end
根据入选概率在群体中按比例选择部分染色体组成种群。
function NewPopulation=Select(Population,PopulationProbability,MemberNumber)
% 概率密度转换为概率分布
CProbability=PopulationProbability(1);
for i=2:MemberNumber
CProbability(i)=CProbability(i-1)+PopulationProbability(i);
end
% 摇随机数并依据随机数和概率选择个体
pmat=rand([MemberNumber,1]);
index=sum((pmat>=CProbability),2)+1;
NewPopulation=Population(index,:);
end
群体中的交叉并产生新群体,原理描述如下:

我们每次都是两个相邻的进行交叉,这样如果个体数为奇数,则最后一个个体则一直无法参与互换,因此我们每次都将倒数第一和倒数第二个体换位置,这样倒数第一位和倒数第二位就能够轮流参与交叉互换。(当然其实直接整体全部交换顺序也可以)。
function NewPopulation=Crossing(Population)
Dim=size(Population);
if Dim(1)>=3
Population([Dim(1),Dim(1)-1],:)=Population([Dim(1)-1,Dim(1)],:);
% 若群体中个体数大于等于3,则将最后一个个体与倒数第二个个体基因型互换;
% 目的是防止有个体从始至终未参与交叉。
end
for i=1:2:Dim(1)-1
% 相邻的俩个体交叉互换
Site=randi(Dim(2));
Population([i,i+1],1:Site)=Population([i+1,i],1:Site);
end
NewPopulation=Population;
end
想改成全部互换则可写做:
function NewPopulation=Crossing(Population)
Dim=size(Population);
Population(1:Dim,:)=Population(randperm(Dim(1)),:);
for i=1:2:Dim(1)-1
Site=randi(Dim(2));
Population([i,i+1],1:Site)=Population([i+1,i],1:Site);
end
NewPopulation=Population;
end
为每个个体摇个随机数,如果随机数符合变异概率,就随机将该个体其中一个0变为1或将1变为0。
function NewPopulation=Mutation(Population,MutationProbability)
Dim=size(Population);
for i=1:Dim(1)
Probability=rand(1);
Site=randi(Dim(2));
if Probability<MutationProbability
Population(i,Site)=mod(Population(i,Site)+1,2);
end
end
NewPopulation=Population;
end
功能: 如果当前序列中有个体优于历史最优则更新历史最优,同时将当前个体组中最差个体用历史最优代替。
输入变量:
输出变量:
function [NewPopulationIncludeMax,NewCurrentBest,EachGenMaxFitness]=...
Elitist(Population,PopulationFitness,MumberLength)
% 找到当前种群最优和最差个体
[~,MinSite]=min(PopulationFitness);
[MaxFitnesstemp,MaxSite]=max(PopulationFitness);
EachGenMaxFitness=MaxFitnesstemp;
% 更新历史最优
if Count==1
CurrentBest(1:MumberLength)=Population(MaxSite,:);
CurrentBest(MumberLength+1)=PopulationFitness(MaxSite);
else
if CurrentBest(MumberLength+1)<MaxFitnesstemp
CurrentBest(1:MumberLength)=Population(MaxSite,:);
CurrentBest(MumberLength+1)=PopulationFitness(MaxSite);
end
% 当前种群最差用历史最优代替
Population(MinSite,:)=CurrentBest(1:MumberLength);
end
NewPopulationIncludeMax=Population;
NewCurrentBest=CurrentBest;
end
把所有代码合在了一起:
function [Count,Result,BestMember]=Genetic1(MumberLength,MemberNumber,FunctionFitness,MinX,MaxX,Fmin,MutationProbability,Gen)
% 参数解释:
% 参数名 参数类型 参数含义
% =========================================================================
% MumberLength | 数值 | 表示一个染色体位串的二进制长度
% MemberNumber | 数值 | 表示群体中染色体个数
% FunctionFitness | 字符串| 表示目标函数
% MinX | 数值 | 变量区间的下限
% MaxX | 数值 | 变量区间的上限
% Fmin | 数值 | 适应函数过程中给出目标函数可能最小值
% MutationProbability| 数值 | 变异概率
% Gen | 数值 | 遗传代数
% -------------------------------------------------------------------------
% Count | 数值 | 遗传代数
% Result | 数值 | 计算结果
% BestMember | 数值 | 最优个体及其适应值
global Count;Count=1;% 在之后的版本中可能会不支持函数输出作为全局变量(建议在改进工作中修改)
global CurrentBest; % 声明全局变量Count(代数)和CurrentBest(当前代数下的最优染色体)
% 随机地产生一个初始群体。
Population=PopulationInitialize(MumberLength,MemberNumber); PopulationCode=Population;
% 计算群体中每一个染色体的目标函数值,适应函数值,入选概率
PopulationFitness=Fitness(PopulationCode,FunctionFitness,MinX,MaxX,MumberLength);
PopulationFitnessF=FitnessF(PopulationFitness,Fmin);
PopulationProbability=Probability(PopulationFitnessF);
% 依据入选概率保留个体并记录最优个体
[Population,CurrentBest,EachGenMaxFitness]=Elitist(PopulationCode,PopulationFitness,MumberLength);
EachMaxFitness(Count)=EachGenMaxFitness;
MaxFitness(Count)=CurrentBest(MumberLength+1);
while Count<Gen
% 通过入选概率将入选概率大的个体选入种群,淘汰概率小的个体形成新群体
NewPopulation=Select(Population,PopulationProbability,MemberNumber);
Population=NewPopulation;
% 通过交叉互换形成新群体;
NewPopulation=Crossing(Population);
Population=NewPopulation;
% 通过变异形成新群体
NewPopulation=Mutation(Population,MutationProbability);
Population=NewPopulation;
% 计算新群体中每一染色体的目标函数值并借此计算出适应值与入选概率
PopulationFitness=Fitness(Population,FunctionFitness,MinX,MaxX,MumberLength);
PopulationFitnessF=FitnessF(PopulationFitness,Fmin);
PopulationProbability=Probability(PopulationFitnessF);
Count=Count+1;
% 替换当前最优个体并将最劣个体用最优个体替换
[NewPopulation,CurrentBest,EachGenMaxFitness]=Elitist(Population,PopulationFitness,MumberLength);
% EachMaxFitness,记录了第Count代中最优个体所对应的目标函数值;
% MaxFitness,前Count代中最优个体所对应的目标函数值;
EachMaxFitness(Count)=EachGenMaxFitness;
MaxFitness(Count)=CurrentBest(MumberLength+1);
Population=NewPopulation;
end
% 数据整理
tDim=size(Population);
Result=ones(2,tDim(1));
for ii=1:tDim(1)
Result(1,ii)=Translate(Population(ii,:),MinX,MaxX,MumberLength);
end
Result(2,:)=Fitness(Population,FunctionFitness,MinX,MaxX,MumberLength);
BestMember(1,1)=Translate(CurrentBest(1:MumberLength),MinX,MaxX,MumberLength);
BestMember(2,1)=CurrentBest(MumberLength+1);
% 绘图
close all
subplot(2,1,1)
plot(EachMaxFitness);
subplot(2,1,2)
plot(MaxFitness);
%子函数部分
%==========================================================================
%PopulationInitialize:用于产生一个初始群体,这个初始群体含有MemberNumber
%个染色体,每个染色体含有MumberLength个基因。
function Population=PopulationInitialize(MumberLength,MemberNumber)
Temporary=rand(MemberNumber,MumberLength);
Population=Temporary>=0.5;
end
%Fitness: 用于计算群体中每一个染色体的目标函数值
function PopulationFitness=Fitness(PopulationCode,FunctionFitness,MinX,MaxX,MumberLength)
Dim=size(PopulationCode);
PopulationFitness=zeros(1,Dim(1));
for i=1:Dim(1)
PopulationData=sum(PopulationCode(i,:).*(2.^(MumberLength-1:-1:0)));
PopulationData=MinX+PopulationData*(MaxX-MinX)/(2^Dim(2)-1);
PopulationFitness(i)=FunctionFitness(PopulationData);
end
end
%FitnessF: 用于计算每个染色体适应值
function PopulationFitnessF=FitnessF(PopulationFitness,Fmin)
PopulationFitnessF=PopulationFitness-Fmin;
PopulationFitnessF(PopulationFitnessF<0)=0;
end
%Translate
function PopulationData=Translate(PopulationCode,MinX,MaxX,MumberLength)
Dim=size(PopulationCode);
PopulationData=sum(PopulationCode.*(2.^(MumberLength-1:-1:0)));
PopulationData=MinX+PopulationData*(MaxX-MinX)/(2^Dim(2)-1);
end
%Probability: 用于计算每个染色体入选概率
function PopulationProbability=Probability(PopulationFitnessF)
PopulationProbability=PopulationFitnessF./sum(PopulationFitnessF);
end
%Elitist: 使用最佳个体保存法,输入参数为:
%Population 群体
%PopulationFitness 目标函数值
%MutationProbability 变异概率
function [NewPopulationIncludeMax,NewCurrentBest,EachGenMaxFitness]=...
Elitist(Population,PopulationFitness,MumberLength)
[~,MinSite]=min(PopulationFitness);
[MaxFitnesstemp,MaxSite]=max(PopulationFitness);
EachGenMaxFitness=MaxFitnesstemp;
if Count==1
CurrentBest(1:MumberLength)=Population(MaxSite,:);
CurrentBest(MumberLength+1)=PopulationFitness(MaxSite);
else
if CurrentBest(MumberLength+1)<MaxFitnesstemp
CurrentBest(1:MumberLength)=Population(MaxSite,:);
CurrentBest(MumberLength+1)=PopulationFitness(MaxSite);
end
Population(MinSite,:)=CurrentBest(1:MumberLength);
end
NewPopulationIncludeMax=Population;
NewCurrentBest=CurrentBest;
end
%Select: 根据入选概率,在群体中按比例选择部分染色体组成种群
function NewPopulation=Select(Population,PopulationProbability,MemberNumber)
% 概率密度转换为概率分布
CProbability=PopulationProbability(1);
for i=2:MemberNumber
CProbability(i)=CProbability(i-1)+PopulationProbability(i);
end
% 摇随机数并依据随机数和概率选择个体
pmat=rand([MemberNumber,1]);
index=sum((pmat>=CProbability),2)+1;
NewPopulation=Population(index,:);
end
%Crossing: 用于群体中的交叉并产生新群体
function NewPopulation=Crossing(Population)
Dim=size(Population);
Population(1:Dim,:)=Population(randperm(Dim(1)),:);
% if Dim(1)>=3
% Population([Dim(1),Dim(1)-1],:)=Population([Dim(1)-1,Dim(1)],:);
% end
for i=1:2:Dim(1)-1
Site=randi(Dim(2));
Population([i,i+1],1:Site)=Population([i+1,i],1:Site);
end
NewPopulation=Population;
end
%Mutation: 用于群体中少量个体变量并产生新的群体
function NewPopulation=Mutation(Population,MutationProbability)
Dim=size(Population);
for i=1:Dim(1)
Probability=rand(1);
Site=randi(Dim(2));
if Probability<MutationProbability
Population(i,Site)=mod(Population(i,Site)+1,2);
end
end
NewPopulation=Population;
end
end以上就是Matlab实现遗传算法的示例详解的详细内容,更多关于Matlab遗传算法的资料请关注编程网其它相关文章!
--结束END--
本文标题: Matlab实现遗传算法的示例详解
本文链接: https://lsjlt.com/news/141729.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0