Python 官方文档:入门教程 => 点击学习
目录前言环境安装下载并安装Anaconda安装JupyterNotebook生成JupyterNotebook项目目录下载训练库单张图片识别导入库加载训练模型初始化载入图片显示图片调
想要使用摄像头实现一个多人姿态识别
官网连接 https://anaconda.cloud/installers

检查Jupyter Notebook是否安装

Tip:这里涉及到一个切换Jupyter Notebook内核的问题,在我这篇文章中有提到
AnacondaNavigator Jupyter Notebook更换python内核Https://www.jb51.net/article/238496.htm
打开Anaconda Prompt切换到项目目录
输入Jupyter notebook在浏览器中打开 Jupyter Notebook

并创建新的记事本
图片以及训练库都在下方链接
https://GitHub.com/quanhua92/human-pose-estimation-OpenCV
将图片和训练好的模型放到项目路径中graph_opt.pb为训练好的模型
import cv2 as cv
import os
import matplotlib.pyplot as pltnet=cv.dnn.readNetFromTensorflow("graph_opt.pb")inWidth=368
inHeight=368
thr=0.2
BODY_PARTS = { "Nose": 0, "Neck": 1, "RShoulder": 2, "RElbow": 3, "RWrist": 4,
"LShoulder": 5, "LElbow": 6, "LWrist": 7, "RHip": 8, "RKnee": 9,
"RAnkle": 10, "LHip": 11, "LKnee": 12, "LAnkle": 13, "REye": 14,
"LEye": 15, "REar": 16, "LEar": 17, "Background": 18 }
POSE_PaiRS = [ ["Neck", "RShoulder"], ["Neck", "LShoulder"], ["RShoulder", "RElbow"],
["RElbow", "RWrist"], ["LShoulder", "LElbow"], ["LElbow", "LWrist"],
["Neck", "RHip"], ["RHip", "RKnee"], ["RKnee", "RAnkle"], ["Neck", "LHip"],
["LHip", "LKnee"], ["LKnee", "LAnkle"], ["Neck", "Nose"], ["Nose", "REye"],
["REye", "REar"], ["Nose", "LEye"], ["LEye", "LEar"] ]
img = cv.imread("image.jpg")plt.imshow(img)
plt.imshow(cv.cvtColor(img,cv.COLOR_BGR2RGB))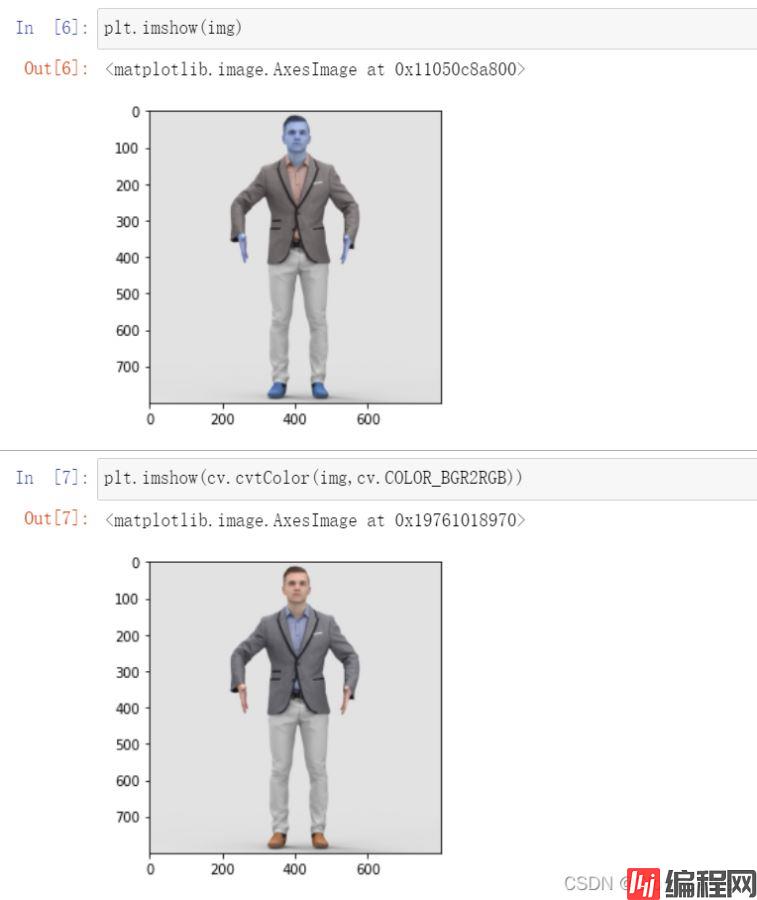
def pose_estimation(frame):
frameWidth=frame.shape[1]
frameHeight=frame.shape[0]
net.setInput(cv.dnn.blobFromImage(frame, 1.0, (inWidth, inHeight), (127.5, 127.5, 127.5), swapRB=True, crop=False))
out = net.forward()
out = out[:, :19, :, :] # MobileNet output [1, 57, -1, -1], we only need the first 19 elements
assert(len(BODY_PARTS) == out.shape[1])
points = []
for i in range(len(BODY_PARTS)):
# Slice heatmap of corresponging body's part.
heatMap = out[0, i, :, :]
# Originally, we try to find all the local maximums. To simplify a sample
# we just find a global one. However only a single pose at the same time
# could be detected this way.
_, conf, _, point = cv.minMaxLoc(heatMap)
x = (frameWidth * point[0]) / out.shape[3]
y = (frameHeight * point[1]) / out.shape[2]
# Add a point if it's confidence is higher than threshold.
points.append((int(x), int(y)) if conf > thr else None)
for pair in POSE_PAIRS:
partFrom = pair[0]
partTo = pair[1]
assert(partFrom in BODY_PARTS)
assert(partTo in BODY_PARTS)
idFrom = BODY_PARTS[partFrom]
idTo = BODY_PARTS[partTo]
# 绘制线条
if points[idFrom] and points[idTo]:
cv.line(frame, points[idFrom], points[idTo], (0, 255, 0), 3)
cv.ellipse(frame, points[idFrom], (3, 3), 0, 0, 360, (0, 0, 255), cv.FILLED)
cv.ellipse(frame, points[idTo], (3, 3), 0, 0, 360, (0, 0, 255), cv.FILLED)
t, _ = net.getPerfProfile()
freq = cv.getTickFrequency() / 1000
cv.putText(frame, '%.2fms' % (t / freq), (10, 20), cv.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0))
return frame
# 处理图片
estimated_image=pose_estimation(img)
# 显示图片
plt.imshow(cv.cvtColor(estimated_image,cv.COLOR_BGR2RGB))
Tip:与上面图片识别代码是衔接的

视频来自互联网,侵删
cap = cv.VideoCapture('testvideo.mp4')
cap.set(3,800)
cap.set(4,800)
if not cap.isOpened():
cap=cv.VideoCapture(0)
raise IOError("Cannot open vide")
while cv.waiTKEy(1) < 0:
hasFrame,frame=cap.read()
if not hasFrame:
cv.waitKey()
break
frameWidth=frame.shape[1]
frameHeight=frame.shape[0]
net.setInput(cv.dnn.blobFromImage(frame, 1.0, (inWidth, inHeight), (127.5, 127.5, 127.5), swapRB=True, crop=False))
out = net.forward()
out = out[:, :19, :, :] # MobileNet output [1, 57, -1, -1], we only need the first 19 elements
assert(len(BODY_PARTS) == out.shape[1])
points = []
for i in range(len(BODY_PARTS)):
# Slice heatmap of corresponging body's part.
heatMap = out[0, i, :, :]
# Originally, we try to find all the local maximums. To simplify a sample
# we just find a global one. However only a single pose at the same time
# could be detected this way.
_, conf, _, point = cv.minMaxLoc(heatMap)
x = (frameWidth * point[0]) / out.shape[3]
y = (frameHeight * point[1]) / out.shape[2]
# Add a point if it's confidence is higher than threshold.
points.append((int(x), int(y)) if conf > thr else None)
for pair in POSE_PAIRS:
partFrom = pair[0]
partTo = pair[1]
assert(partFrom in BODY_PARTS)
assert(partTo in BODY_PARTS)
idFrom = BODY_PARTS[partFrom]
idTo = BODY_PARTS[partTo]
if points[idFrom] and points[idTo]:
cv.line(frame, points[idFrom], points[idTo], (0, 255, 0), 3)
cv.ellipse(frame, points[idFrom], (3, 3), 0, 0, 360, (0, 0, 255), cv.FILLED)
cv.ellipse(frame, points[idTo], (3, 3), 0, 0, 360, (0, 0, 255), cv.FILLED)
t, _ = net.getPerfProfile()
freq = cv.getTickFrequency() / 1000
cv.putText(frame, '%.2fms' % (t / freq), (10, 20), cv.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0))
cv.imshow('Video Tutorial',frame)Tip:与上面图片识别代码是衔接的
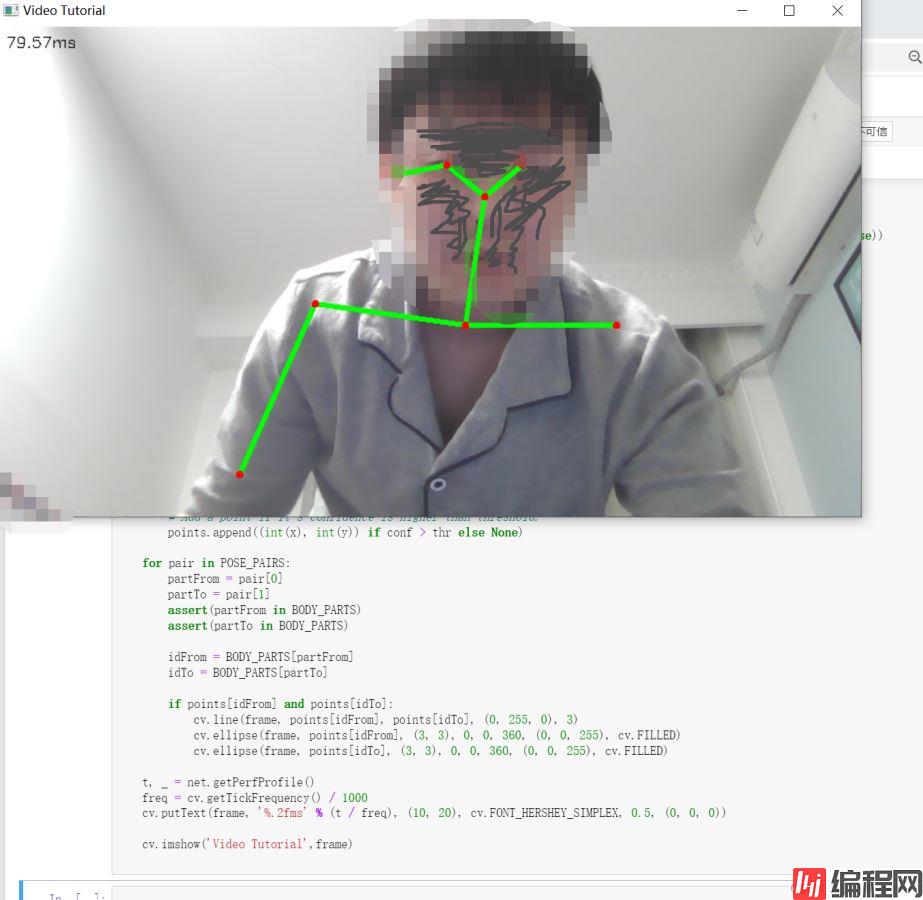
cap = cv.VideoCapture(0)
cap.set(cv.CAP_PROP_FPS,10)
cap.set(3,800)
cap.set(4,800)
if not cap.isOpened():
cap=cv.VideoCapture(0)
raise IOError("Cannot open vide")
while cv.waitKey(1) < 0:
hasFrame,frame=cap.read()
if not hasFrame:
cv.waitKey()
break
frameWidth=frame.shape[1]
frameHeight=frame.shape[0]
net.setInput(cv.dnn.blobFromImage(frame, 1.0, (inWidth, inHeight), (127.5, 127.5, 127.5), swapRB=True, crop=False))
out = net.forward()
out = out[:, :19, :, :] # MobileNet output [1, 57, -1, -1], we only need the first 19 elements
assert(len(BODY_PARTS) == out.shape[1])
points = []
for i in range(len(BODY_PARTS)):
# Slice heatmap of corresponging body's part.
heatMap = out[0, i, :, :]
# Originally, we try to find all the local maximums. To simplify a sample
# we just find a global one. However only a single pose at the same time
# could be detected this way.
_, conf, _, point = cv.minMaxLoc(heatMap)
x = (frameWidth * point[0]) / out.shape[3]
y = (frameHeight * point[1]) / out.shape[2]
# Add a point if it's confidence is higher than threshold.
points.append((int(x), int(y)) if conf > thr else None)
for pair in POSE_PAIRS:
partFrom = pair[0]
partTo = pair[1]
assert(partFrom in BODY_PARTS)
assert(partTo in BODY_PARTS)
idFrom = BODY_PARTS[partFrom]
idTo = BODY_PARTS[partTo]
if points[idFrom] and points[idTo]:
cv.line(frame, points[idFrom], points[idTo], (0, 255, 0), 3)
cv.ellipse(frame, points[idFrom], (3, 3), 0, 0, 360, (0, 0, 255), cv.FILLED)
cv.ellipse(frame, points[idTo], (3, 3), 0, 0, 360, (0, 0, 255), cv.FILLED)
t, _ = net.getPerfProfile()
freq = cv.getTickFrequency() / 1000
cv.putText(frame, '%.2fms' % (t / freq), (10, 20), cv.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0))
cv.imshow('Video Tutorial',frame)DeepLearning_by_PhDScholar
Human Pose Estimation using opencv | Python | OpenPose | stepwise implementation for beginners
https://www.youtube.com/watch?v=9jQGsUidKHs
到此这篇关于Python OpenCV实现姿态识别的文章就介绍到这了,更多相关Python姿态识别内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: Python OpenCV实现姿态识别的详细代码
本文链接: https://lsjlt.com/news/140202.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0