Python 官方文档:入门教程 => 点击学习
听歌识曲,顾名思义,用设备“听”歌曲,然后它要告诉你这是首什么歌。而且十之八九它还得把这首歌给你播放出来。这样的功能在QQ音乐等应用上早就出现了。我们今天来自己动手做一个自己的听歌识曲 我们设计的总体流程
听歌识曲,顾名思义,用设备“听”歌曲,然后它要告诉你这是首什么歌。而且十之八九它还得把这首歌给你播放出来。这样的功能在QQ音乐等应用上早就出现了。我们今天来自己动手做一个自己的听歌识曲
我们设计的总体流程图很简单:
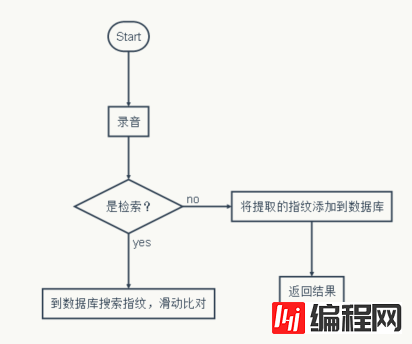
-----
录音部分
-----
我们要想“听”,就必须先有录音的过程。在我们的实验中,我们的曲库也要用我们的录音代码来进行录音,然后提取特征存进数据库。我们用下面这样的思路来录音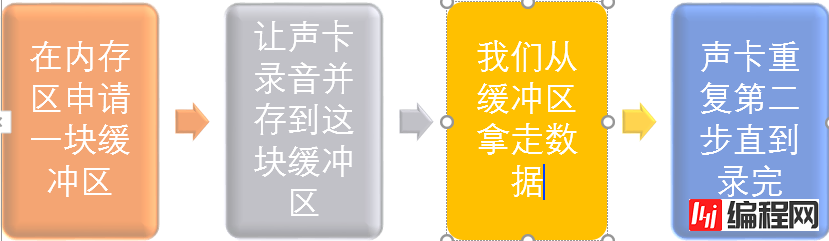
# coding=utf8
import wave
import pyaudio
class recode():
def recode(self, CHUNK=44100, FORMAT=pyaudio.paint16, CHANNELS=2, RATE=44100, RECORD_SECONDS=200,
WAVE_OUTPUT_FILENAME="record.wav"):
'''
:param CHUNK: 缓冲区大小
:param FORMAT: 采样大小
:param CHANNELS:通道数
:param RATE:采样率
:param RECORD_SECONDS:录的时间
:param WAVE_OUTPUT_FILENAME:输出文件路径
:return:
'''
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
frames = []
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
frames.append(data)
stream.stop_stream()
stream.close()
p.terminate()
wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(''.join(frames))
wf.close()
if __name__ == '__main__':
a = recode()
a.recode(RECORD_SECONDS=30, WAVE_OUTPUT_FILENAME='record_pianai.wav')
我们录完的歌曲是个什么形式?
如果只看一个声道的话,他是一个一维数组,大概长成这个样子

我们把他按照索引值为横轴画出来,就是我们常常看见的音频的形式。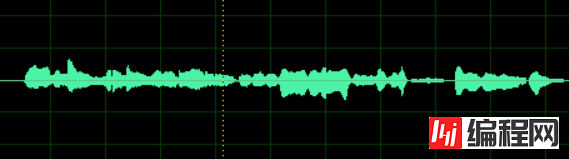
音频处理部分
我们在这里要写我们的核心代码。关键的“如何识别歌曲”。想想我们人类如何区分歌曲? 是靠想上面那样的一维数组吗?是靠歌曲的响度吗?都不是。
我们是通过耳朵所听到的特有的频率组成的序列来记忆歌曲的,所以我们想要写听歌识曲的话,就得在音频的频率序列上做文章。
复习一下什么是傅里叶变换。博主的《信号与系统》的课上的挺水,不过在课上虽然没有记下来具体的变换形式,但是感性的理解还是有的。
傅里叶变换的实质就是把时域信号变换成了频域信号。也就是原本X,Y轴分别是我们的数组下标和数组元素,现在变成了频率(这么说不准确,但在这里这样理解没错)和在这个频率上的分量大小。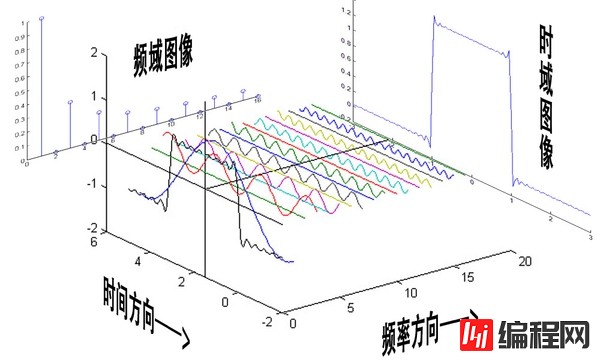
怎么理解频域这个事情呢?对于我们信号处理不是很懂的人来说,最重要的就是改变对音频的构成的理解。我们原来认为音频就是如我们开始给出的波形那样,在每一个时间有一个幅值,不同的幅值序列构成了我们特定的声音。而现在,我们认为声音是不同的频率信号混合而成的,他们每一个信号都自始至终存在着。并且他们按照他们的投影分量做贡献。
让我们看看把一首歌曲转化到频域是什么样子?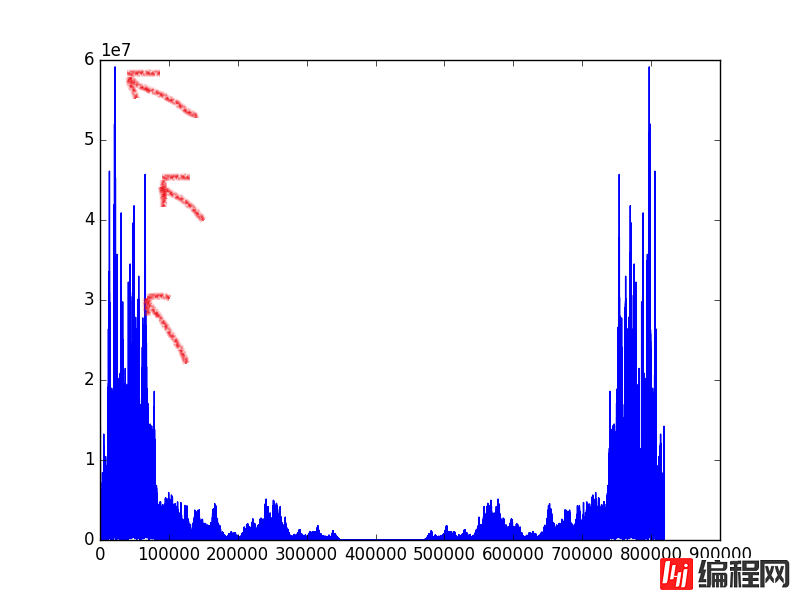
我们可以观察到这些频率的分量并不是平均的,差异是非常大的。我们可以在一定程度上认为在图中明显凸起的峰值是输出能量大的频率信号,代表着在这个音频中,这个信号占有很高的地位。于是我们就选择这样的信号来提取歌曲的特征。
但是别忘了,我们之前说的可是频率序列,傅里叶变换一套上,我们就只能知道整首歌曲的频率信息,那么我们就损失了时间的关系,我们说的“序列”也就无从谈起。所以我们采用的比较折中的方法,将音频按照时间分成一个个小块,在这里我每秒分出了40个块。
在这里留个问题:为什么要采用小块,而不是每秒一块这样的大块?
我们对每一个块进行傅里叶变换,然后对其求模,得到一个个数组。我们在下标值为(0,40),(40,80),(80,120),(120,180)这四个区间分别取其模长最大的下标,合成一个四元组,这就是我们最核心的音频“指纹”。
我们提取出来的“指纹”类似下面这样
(39, 65, 110, 131), (15, 66, 108, 161), (3, 63, 118, 146), (11, 62, 82, 158), (15, 41, 95, 140), (2, 71, 106, 143), (15, 44, 80, 133), (36, 43, 80, 135), (22, 58, 80, 120), (29, 52, 89, 126), (15, 59, 89, 126), (37, 59, 89, 126), (37, 59, 89, 126), (37, 67, 119, 126)
音频处理的类有三个方法:载入数据,傅里叶变换,播放音乐。
如下:
# coding=utf8
import os
import re
import wave
import numpy as np
import pyaudio
class voice():
def loaddata(self, filepath):
'''
:param filepath: 文件路径,为wav文件
:return: 如果无异常则返回True,如果有异常退出并返回False
self.wave_data内储存着多通道的音频数据,其中self.wave_data[0]代表第一通道
具体有几通道,看self.nchannels
'''
if type(filepath) != str:
print 'the type of filepath must be string'
return False
p1 = re.compile('.wav')
if p1.findall(filepath) is None:
print 'the suffix of file must be .wav'
return False
try:
f = wave.open(filepath, 'rb')
params = f.getparams()
self.nchannels, self.sampwidth, self.framerate, self.nframes = params[:4]
str_data = f.readframes(self.nframes)
self.wave_data = np.fromstring(str_data, dtype=np.short)
self.wave_data.shape = -1, self.sampwidth
self.wave_data = self.wave_data.T
f.close()
self.name = os.path.basename(filepath) # 记录下文件名
return True
except:
print 'File Error!'
def fft(self, frames=40):
'''
:param frames: frames是指定每秒钟分块数
:return:
'''
block = []
fft_blocks = []
self.high_point = []
blocks_size = self.framerate / frames # block_size为每一块的frame数量
blocks_num = self.nframes / blocks_size # 将音频分块的数量
for i in xrange(0, len(self.wave_data[0]) - blocks_size, blocks_size):
block.append(self.wave_data[0][i:i + blocks_size])
fft_blocks.append(np.abs(np.fft.fft(self.wave_data[0][i:i + blocks_size])))
self.high_point.append((np.argmax(fft_blocks[-1][:40]),
np.argmax(fft_blocks[-1][40:80]) + 40,
np.argmax(fft_blocks[-1][80:120]) + 80,
np.argmax(fft_blocks[-1][120:180]) + 120,
# np.argmax(fft_blocks[-1][180:300]) + 180,
)) # 提取指纹的关键步骤,没有取最后一个,但是保留了这一项,可以想想为什么去掉了?
def play(self, filepath):
'''
用来做音频播放的方法
:param filepath:文件路径
:return:
'''
chunk = 1024
wf = wave.open(filepath, 'rb')
p = pyaudio.PyAudio()
# 打开声音输出流
stream = p.open(format=p.get_format_from_width(wf.getsampwidth()),
channels=wf.getnchannels(),
rate=wf.getframerate(),
output=True)
# 写声音输出流进行播放
while True:
data = wf.readframes(chunk)
if data == "":
break
stream.write(data)
stream.close()
p.terminate()
if __name__ == '__main__':
p = voice()
p.loaddata('record_beiyiwang.wav')
p.fft()
这里面的self.high_point是未来应用的核心数据。列表类型,里面的元素都是上面所解释过的指纹的形式。
数据存储和检索部分
因为我们是事先做好了曲库来等待检索,所以必须要有相应的持久化方法。我采用的是直接用Mysql数据库来存储我们的歌曲对应的指纹,这样有一个好处:省写代码的时间
我们将指纹和歌曲存成这样的形式:
顺便一说:为什么各个歌曲前几个的指纹都一样?(当然,后面肯定是千差万别的)其实是音乐开始之前的时间段中没有什么能量较强的点,而由于我们44100的采样率比较高,就会导致开头会有很多重复,别担心。
我们怎么来进行匹配呢?我们可以直接搜索音频指纹相同的数量,不过这样又损失了我们之前说的序列,我们必须要把时间序列用上。否则一首歌曲越长就越容易被匹配到,这种歌曲像野草一样疯狂的占据了所有搜索音频的结果排行榜中的第一名。而且从理论上说,音频所包含的信息就是在序列中体现,就像一句话是靠各个短语和词汇按照一定顺序才能表达出它自己的意思。单纯的看两个句子里的词汇重叠数是完全不能判定两句话是否相似的。我们采用的是下面的算法,不过我们这只是实验性的代码,算法设计的很简单,效率不高。建议想要做更好的结果的同学可以使用改进的DTW算法。
我们在匹配过程中滑动指纹序列,每次比对模式串和源串的对应子串,如果对应位置的指纹相同,则这次的比对相似值加一,我们把滑动过程中得到的最大相似值作为这两首歌的相似度。
举例:
曲库中的一首曲子的指纹序列:[fp13, fp20, fp10, fp29, fp14, fp25, fp13, fp13, fp20, fp33, fp14]
检索音乐的指纹序列: [fp14, fp25, fp13, fp17]
比对过程:

最终的匹配相似值为3
存储检索部分的实现代码
# coding=utf-8
import os
import mysqldb
import my_audio
class memory():
def __init__(self, host, port, user, passwd, db):
'''
初始化存储类
:param host:主机位置
:param port:端口
:param user:用户名
:param passwd:密码
:param db:数据库名
'''
self.host = host
self.port = port
self.user = user
self.passwd = passwd
self.db = db
def addsong(self, path):
'''
添加歌曲方法,将指定路径的歌曲提取指纹后放到数据库
:param path:路径
:return:
'''
if type(path) != str:
print 'path need string'
return None
basename = os.path.basename(path)
try:
conn = Mysqldb.connect(host=self.host, port=self.port, user=self.user, passwd=self.passwd, db=self.db,
charset='utf8')
# 创建与数据库的连接
except:
print 'DataBase error'
return None
cur = conn.cursor()
namecount = cur.execute("select * from fingerprint.musicdata WHERE song_name = '%s'" % basename)
# 查询新添加的歌曲是否已经在曲库中了
if namecount > 0:
print 'the song has been record!'
return None
v = my_audio.voice()
v.loaddata(path)
v.fft()
cur.execute("insert into fingerprint.musicdata VALUES('%s','%s')" % (basename, v.high_point.__str__()))
# 将新歌曲的名字和指纹存到数据库中
conn.commit()
cur.close()
conn.close()
def fp_compare(self, search_fp, match_fp):
'''
指纹比对方法。
:param search_fp: 查询指纹
:param match_fp: 库中指纹
:return:最大相似值 float
'''
if len(search_fp) > len(match_fp):
return 0
max_similar = 0
search_fp_len = len(search_fp)
match_fp_len = len(match_fp)
for i in range(match_fp_len - search_fp_len):
temp = 0
for j in range(search_fp_len):
if match_fp[i + j] == search_fp[j]:
temp += 1
if temp > max_similar:
max_similar = temp
return max_similar
def search(self, path):
'''
从数据库检索出
:param path: 需要检索的音频的路径
:return:返回列表,元素是二元组,第一项是匹配的相似值,第二项是歌曲名
'''
v = my_audio.voice()
v.loaddata(path)
v.fft()
try:
conn = MySQLdb.connect(host=self.host, port=self.port, user=self.user, passwd=self.passwd, db=self.db,
charset='utf8')
except:
print 'DataBase error'
return None
cur = conn.cursor()
cur.execute("SELECT * FROM fingerprint.musicdata")
result = cur.fetchall()
compare_res = []
for i in result:
compare_res.append((self.fp_compare(v.high_point[:-1], eval(i[1])), i[0]))
compare_res.sort(reverse=True)
cur.close()
conn.close()
print compare_res
return compare_res
def search_and_play(self, path):
'''
跟上个方法一样,不过增加了将搜索出的最优结果直接播放的功能
:param path: 带检索歌曲路径
:return:
'''
v = my_audio.voice()
v.loaddata(path)
v.fft()
# print v.high_point
try:
conn = MySQLdb.connect(host=self.host, port=self.port, user=self.user, passwd=self.passwd, db=self.db,
charset='utf8')
except:
print 'DataBase error'
return None
cur = conn.cursor()
cur.execute("SELECT * FROM fingerprint.musicdata")
result = cur.fetchall()
compare_res = []
for i in result:
compare_res.append((self.fp_compare(v.high_point[:-1], eval(i[1])), i[0]))
compare_res.sort(reverse=True)
cur.close()
conn.close()
print compare_res
v.play(compare_res[0][1])
return compare_res
if __name__ == '__main__':
sss = memory('localhost', 3306, 'root', 'root', 'fingerprint')
sss.addsong('taiyangzhaochangshengqi.wav')
sss.addsong('beiyiwangdeshiguang.wav')
sss.addsong('xiaozezhenger.wav')
sss.addsong('nverqing.wav')
sss.addsong('the_mess.wav')
sss.addsong('windmill.wav')
sss.addsong('end_of_world.wav')
sss.addsong('pianai.wav')
sss.search_and_play('record_beiyiwang.wav')
总结
我们这个实验很多地方都很粗糙,核心的算法是从shazam公司提出的算法吸取的“指纹”的思想。希望读者可以提出宝贵建议。
--结束END--
本文标题: 听歌识曲--用python实现一个音乐检索器的功能
本文链接: https://lsjlt.com/news/13988.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0