目录数据结构与算法什么是数据结构?什么是算法?分析维度大O的渐进表示法常数阶线性阶对数阶其他时间复杂度指标空间复杂度数据结构与算法 终于开始搞这块难啃的骨头了,走上这条漫漫长路之前要
终于开始搞这块难啃的骨头了,走上这条漫漫长路之前要明白:
是数据之间存在一种或多种特定关系的数据元素集合,为编写出一个“好”的程序,必须分析待处理对象的特性及各处理对象之间存在的关系,这也就是研究数据结构的意义所在为编写出一个“好”的程序,必须分析待处理对象的特性及各处理对象之间存在的关系这也就是研究数据结构的意义所在
算法是解决特定问题求解步骤的描述,在计算机中表现为指令的有限序列 ,并且每条指令表示一个或多个操作
抛开上面的学术性口水话,简单来说就是:
1.数据结构是计算机存储,组织数据的方式
2.算法是一系列规定的计算步骤,为了实现的特定的计算目的而应用
给个更直观的视图就是:算法+数据结构就等于程序,数据结构可以理解为实现一个程序的基本单位,算法可以看作一个加工过程。
比如我去从一个很大的数组里面提取某个特定的对象,我们既可以老老实实从头到尾遍历查找,也就是所谓的暴力搜索,工程量随着数组的容量增大而增大;我们也可以巧夺智取,用二分查找让我们工作事半功倍。
在知道基本概念后,我们说在拿到一个算法后,我们怎么去看他的好坏?或者给你多个算法,他们都实现同一个功能,我们怎么去判断他的优缺点去取舍呢?正常情况下,我们会选择把这个代码放在某个环境下运行比较时间,但这个做法有一个致命的缺点,在我们不同机器上,会有不同的结果,在好的机器上,运行时间会很短,但是在比较差一点的主机上,就稍有逊色,这样一来就有失公平。
不要直接计算时间,,我们需要去计算一个渐进的时间复杂度,也就是所谓的Big O (大O表示法),他其实本质上实在求一个量级(时间)在增加时的一个变化趋势
时间复杂度公式:T(n)=O(f(n))
T(n):时间频度(执行次数)n :问题规模;f(n):T(n)的同数量级函数;O :代表正比例关系;O(f(n)):即算法的渐进时间复杂度
我们的算加法的完整过程:
int main()
{
int a = 1;
int b = 1;
int sum = a+b;
printf("%d",sum);
}
我们每走一步就会执行一次,上面的代码我就执行了四次;那么如果我把他的sum部分重复执行数十次数百次数千次,但他本质上和执行四次没有区别,执行时间是恒定的,这个层面上,他的时间复杂度就是O(1)(常数阶)。
不管这个常数是多少,4或∞,都不能写成O(4)、O(∞),都要写成O(1)
我们给出一个 for loop
for(int a = 1;a<=n;a++)
{
a++;
}
分析线性阶时会比常数阶更复杂因为要分析他的循环结构,上面的代码限制再++,总共执行3次,包括常数阶的赋值就是O(3n+1),在我的n足够大时他会无限接近于无穷,这时的+1就会没有意义。
这时就顺理成章,嵌套循环我们也就可以理解了,两层 for 就是O(n2),三层就是O(n2)for 下面加一个双层for循环就是O(n+n2)……这里面就包含了**平方阶**;此时我O(n)的效率就比O(n2)高。
我们再给出一个while loop
int n = 0;
while(n<100000)
{
n*=2;
}
我们要看执行次数就要看多少步才能走出循环,就意味着要乘 x 个2能>=10000,则表示为 2^x =100000,假设为随机数 a,则 x= log 2 ^a,
复杂度为O(logn)
除了上面三种之外还有其他的复杂度
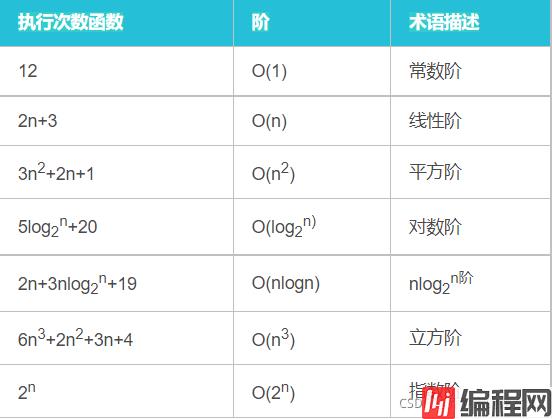
从常数阶到阶乘是越来越复杂,我们看一下直观数据:
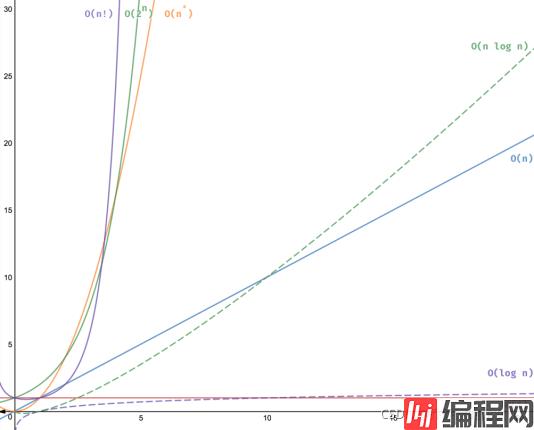
这里横轴是输入(input)量级,纵轴是消耗时间也就是时间复杂度,也就是有个很直观的信息:算法复杂度越高,需要的时间越长,到后面就直接指数级增长。
虽然有下面这些种吧,但我们主要会把重心放在 O 上,毕竟它是最常用的指标。

空间复杂度是指内存空间增长的趋势,相对就容易理解一些,O(1)就是相当于单次赋值,而 O(n)相当于赋值n次,可以把他想成一个大小为 n 的数组,复杂度越高需要分配的空间就越多;同理,O(n^2)就可以想成一个n行n列的二维数组。
--结束END--
本文标题: C语言数据结构与算法之时间空间复杂度入门
本文链接: https://lsjlt.com/news/139254.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0