Python 官方文档:入门教程 => 点击学习
目录一、起因二、Druid数据库连接池三、Atomikos框架四、分析与总结一、起因 最近查看系统的后台日志,经常发现这样的报错信息:The last package succe
最近查看系统的后台日志,经常发现这样的报错信息:The last package successfully received from the server was 40802382 milliseconds aGo,截图如下所示。


由于我们的系统都是在白天使用,夜里基本上没有用户使用,再加上以上的报错信息都是出现在早晨,结合错误日志初步分析,应该是数据库连接超时自动断开了。百度一番后,得知Mysql的默认连接时间是8小时,超过8小时没有操作后就会自动断开连接,但是已经使用了druid数据库连接池,按理说已经对数据库连接做了保护和检查,不应该出现这样的问题。要想彻底弄明白这个问题,就只能去研究druid数据库连接池框架了。
项目的数据库连接池基本配置信息如下所示
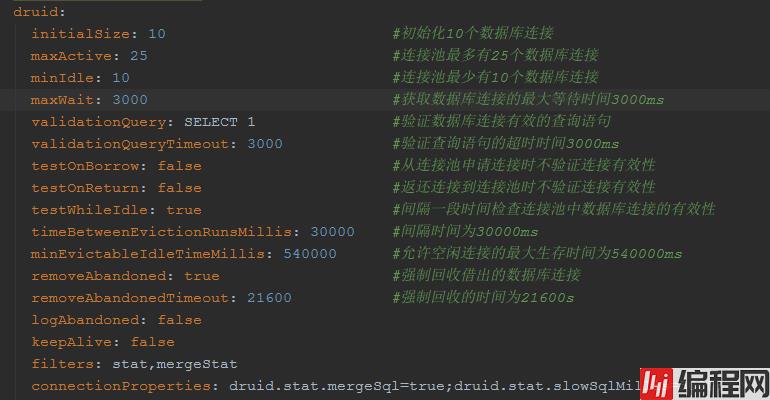
通过以上的配置分析得知,一个数据库连接从连接池中借出后经过21600s即6小时后会被强制回收,不会超过mysql的默认8小时,而且也不存在这么长时间的事务,所以不太可能是因为数据库连接借出超时导致上面的错误,那么就是从数据库连接池中申请的连接已经超时了?似乎也不太可能,因为有检查机制,即每隔30s就会检查一次连接池中的连接是否超时,并且连接池中允许存在的空闲连接最大时间为540s。这就奇怪了,到底是什么原因导致上面的错误呢?这时注意到上述错误堆栈中的com.atomikos.datasource.pool.ConnectionPool.findOrWaitForAnAvailableConnection。是否问题的原因在于使用了Atomikos呢,带着这样的疑惑去阅读了Druid和Atomikos相关的源码。
由于Atomikos连接池是基于Druid连接池之上的,所以Atomikos新建和销毁数据库连接都是从Druid连接池中借出和归还数据库连接,而不是直接与数据库交互,那么我们就来看看Druid是如何维持数据库连接的。
public DruidPooledConnection getConnection(long maxWaitMillis) throws sqlException {
//初始化检查配置和后台线程
init();
if (filters.size() > 0) {
FilterChainImpl filterChain = new FilterChainImpl(this);
return filterChain.dataSource_connect(this, maxWaitMillis);
} else {
return getConnectionDirect(maxWaitMillis);
}
}从Druid连接池中获取数据库连接,先调用init()方法进行初始化工作,然后调用getConnectionDirect()获取连接。
decrementPoolinGCount();
DruidConnectionHolder last = connections[poolingCount];
connections[poolingCount] = null;DruidPooledConnection poolalbeConnection = new DruidPooledConnection(holder);
public DruidPooledConnection(DruidConnectionHolder holder){
super(holder.getConnection());
this.conn = holder.getConnection();
this.holder = holder;
this.lock = holder.lock;
dupCloseLogEnable = holder.getDataSource().isDupCloseLogEnable();
ownerThread = Thread.currentThread();
connectedTimeMillis = System.currentTimeMillis();
}上述是获取连接池中连接的关键代码,即获取connections数组中的最后一个元素,获取到Holder后还需要将其封装为DruidPooledConnection,这时该连接的connectedTimeMillis会被赋值为当前时间,这个时间在后续的分析中会非常重要。
因为配置了testWhileIdle为true,所以需要进行下面的有效性检查,获取该连接的上次活跃时间,得到空闲时间,如果超过30s则做有效性检查。
long idleMillis = currentTimeMillis - lastActiveTimeMillis;
long timeBetweenEvictionRunsMillis = this.timeBetweenEvictionRunsMillis;
if (timeBetweenEvictionRunsMillis <= 0) {
timeBetweenEvictionRunsMillis = DEFAULT_TIME_BETWEEN_EVICTION_RUNS_MILLIS;
}
if (idleMillis >= timeBetweenEvictionRunsMillis
|| idleMillis < 0 // unexcepted branch
) {
boolean validate = testConnectionInternal(poolableConnection.holder, poolableConnection.conn);
if (!validate) {
if (LOG.isDebugEnabled()) {
LOG.debug("skip not validate connection.");
}
discardConnection(poolableConnection.holder);
continue;
}
}long timeMillis = (currrentNanos - pooledConnection.getConnectedTimeNano()) / (1000 * 1000);
if (timeMillis >= removeAbandonedTimeoutMillis) {
iter.remove();
pooledConnection.setTraceEnable(false);
abandonedList.add(pooledConnection);
}同时,由于配置了removeAbandoned为true,所以需要检查活跃连接是否超时,如果超时就断开物理连接。下面看一下连接池的回收方法recycle的关键代码
if (phyTimeoutMillis > 0) {
long phyConnectTimeMillis = currentTimeMillis - holder.connectTimeMillis;
if (phyConnectTimeMillis > phyTimeoutMillis) {
discardConnection(holder);
return;
}
}
lock.lock();
try {
if (holder.active) {
activeCount--;
holder.active = false;
}
closeCount++;
result = putLast(holder, currentTimeMillis);
recycleCount++;
} finally {
lock.unlock();
}在对数据库连接进行回收时,如果连接时间超过了数据库的物理连接时间(默认8小时)则需要断开物理连接,否则就调用putLast方法将该连接回收到连接池。
boolean putLast(DruidConnectionHolder e, long lastActiveTimeMillis) {
if (poolingCount >= maxActive || e.discard) {
return false;
}
e.lastActiveTimeMillis = lastActiveTimeMillis;
connections[poolingCount] = e;
incrementPoolingCount();
if (poolingCount > poolingPeak) {
poolingPeak = poolingCount;
poolingPeakTime = lastActiveTimeMillis;
}
notEmpty.signal();
notEmptySignalCount++;
return true;
}注意上述标红的地方,回收的这个连接的lastActiveTimeMillis被刷新为当前时间,这个时间也是非常重要的,在后续分析中会用到。
项目关于Atomikos的配置信息,如下所示
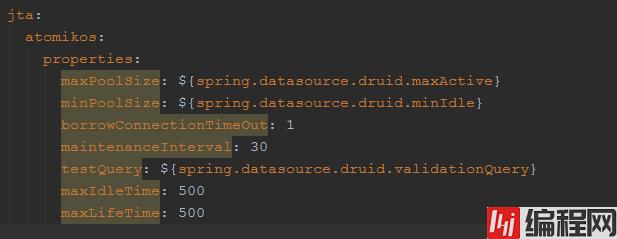
从上面的配置可以看出,atomikos连接池的最大连接数是25个,最小连接数是10个,连接最大的存活时间是500s,下面来看一下atomikos的源码。
private void init() throws ConnectionPoolException
{
if ( LOGGER.isTraceEnabled() ) LOGGER.logTrace ( this + ": initializing..." ); //如果连接池最小连接数没有达到就新增数据库连接
addConnectionsIfMinPoolSizeNotReached(); //开启维持连接池平衡的线程
launchMaintenanceTimer();
}以上是Atomikos初始化的部分,先补充数据库连接池达到最小连接数,然后开启后台线程维持连接池的平衡。
private void launchMaintenanceTimer() {
int maintenanceInterval = properties.getMaintenanceInterval();
if ( maintenanceInterval <= 0 ) {
if ( LOGGER.isTraceEnabled() ) LOGGER.logTrace ( this + ": using default maintenance interval..." );
maintenanceInterval = DEFAULT_MAINTENANCE_INTERVAL;
}
maintenanceTimer = new PooledAlarmTimer ( maintenanceInterval * 1000 );
maintenanceTimer.addAlarmTimerListener(new AlarmTimerListener() {
public void alarm(AlarmTimer timer) {
reapPool(); //如果达到了最大的存活时间就移除该连接
removeConnectionsThatExceededMaxLifetime(); //如果没有满足最小连接数就新增连接
addConnectionsIfMinPoolSizeNotReached(); //移除超过最小连接数以外的连接
removeIdleConnectionsIfMinPoolSizeExceeded();
}
});
TaskManager.SINGLETON.executeTask ( maintenanceTimer );
}在配置中,maintenanceInterval的值为30,即每个30秒执行一次上述的四个方法,主要看一下removeConnectionsThatExceededMaxLifetime()这个方法。
private synchronized void removeConnectionsThatExceededMaxLifetime()
{
long maxLifetime = properties.getMaxLifetime();
if ( connections == null || maxLifetime <= 0 ) return;
if ( LOGGER.isTraceEnabled() ) LOGGER.logTrace ( this + ": closing connections that exceeded maxLifetime" );
Iterator<XPooledConnection> it = connections.iterator();
while ( it.hasNext() ) {
XPooledConnection xpc = it.next();
long creationTime = xpc.getCreationTime();
long now = System.currentTimeMillis();
if ( xpc.isAvailable() && ( (now - creationTime) >= (maxLifetime * 1000L) ) ) {
if ( LOGGER.isTraceEnabled() ) LOGGER.logTrace ( this + ": connection in use for more than " + maxLifetime + "s, destroying it: " + xpc ); //如果超过最大的存活时间就销毁该连接
destroyPooledConnection(xpc);
it.remove();
}
}
logCurrentPoolSize();
}上述方法遍历数据库连接池中的所有连接,如果存活时间超过maxLifetime即500s就销毁该连接,这时由于连接池中的连接数就小于minPoolSize,所以会立即补充新的连接到连接池中。那么,系统在夜间没有用户使用时,Atomikos连接池的运行状态为:维持最小的连接数10个数据库连接,当这10个连接超过500s时就会销毁,再重新创建10个新的数据库连接,不断重复这样的操作。
下面我们开始分析产生错误日志的原因,当没有用户使用系统时,Druid连接池应该有10个空闲的连接,Atomikos连接池也有10个空闲的连接,这时Atomikos的10个连接达到了最大的生存时间500s,就需要销毁这些连接,对于Druid来说就是回收连接,调用recycle方法。由于这10个连接应该是500s之前从Druid连接池借出的,所以它们的connectTimeMillis也是500s之前的时间,即物理连接时间肯定小于8小时,可以成功回收到Druid连接池中,同时lastActiveTimeMillis也更新为当前时间,放在connections数组的末尾。
与此同时,Atomikos还需要重新生成10个新的连接,即从Druid连接池获取10个连接,调用getConnection方法,这时会进行有效性的检查,又因为lastActiveTimeMillis基本上为当前时间,所以idleMillis肯定比30s小,不需要进行select 1的连接数据库操作,这样即使该连接已经失效了还是会借出给Atomikos。每隔500s不断循环上述操作,并且期间没有用户的操作,一旦超过8个小时的Mysql连接时间,Atomikos在使用数据库连接时就会产生上述日志中的错误了。
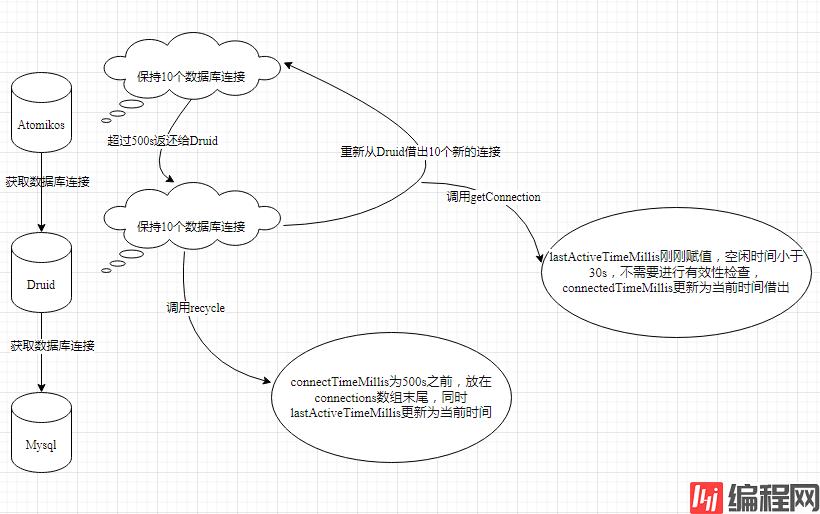
综上所述,导致报错的原因其实是使用了两层数据库连接池,这样Druid连接池借出的数据库连接并没有被实际使用,这才导致这些数据库连接成功躲避了Druid本身的检查机制。
到此这篇关于SpringBoot+atomikos+druid 数据库连接失效分析的文章就介绍到这了,更多相关springboot+atomikos+druid 数据库连接失效分析内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: 详解springboot+atomikos+druid 数据库连接失效分析
本文链接: https://lsjlt.com/news/138345.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0