Python 官方文档:入门教程 => 点击学习
目录网页情况python 代码运行效果总结网页情况 爬取数据包含 歌曲排名、歌手、歌曲名、歌曲时长 Python 代码 import requests #请求网页获取网页数据
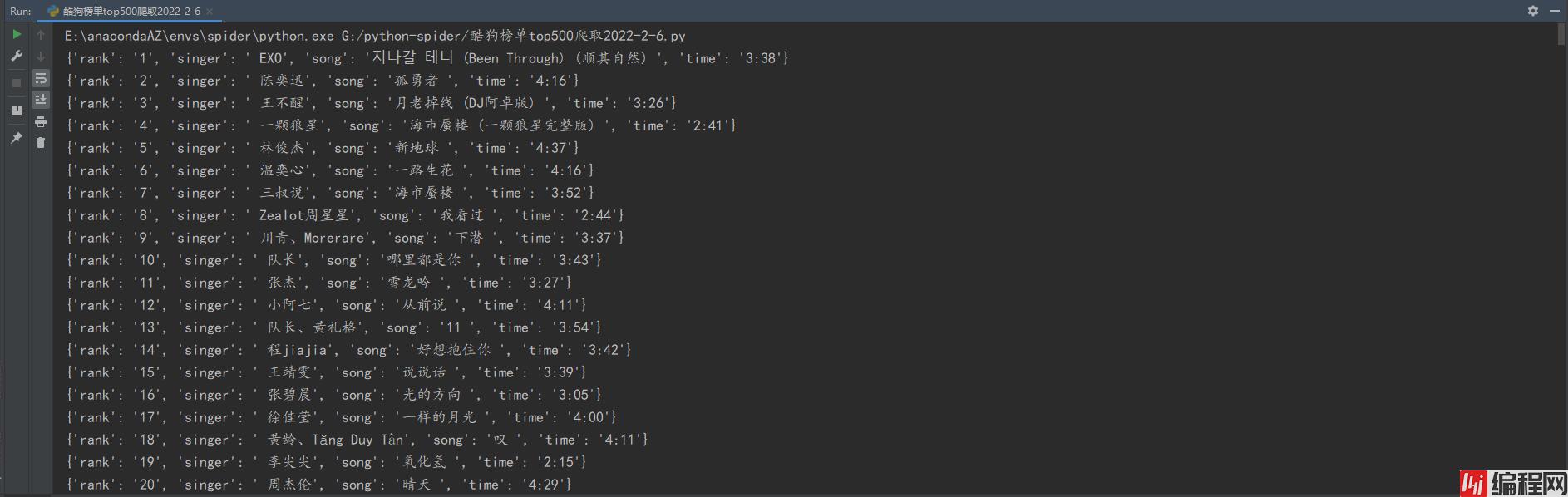
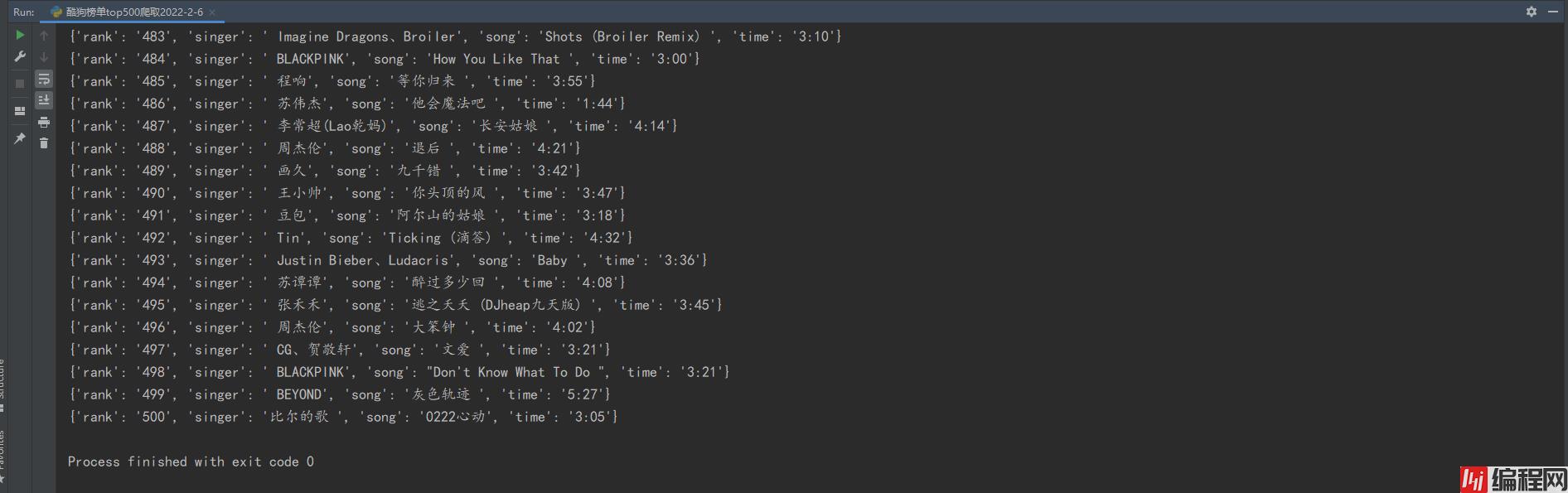
爬取数据包含
歌曲排名、歌手、歌曲名、歌曲时长
import requests #请求网页获取网页数据
from bs4 import BeautifulSoup #解析网页数据
import time #时间库
#user-Agent,伪装成浏览器,便于爬虫的稳定性
headers = {
"User-Agent":
"Mozilla/5.0 (windows NT 10.0; Win64; x64) AppleWEBKit/537.36 (Khtml, like Gecko) Chrome/97.0.4692.71 Safari/537.36"
}
def get_info(url):
web_data = requests.get(url,headers= headers)
soup = BeautifulSoup(web_data.text,'lxml')
ranks = soup.select('span.pc_temp_num')
titles = soup.select('div.pc_temp_songlist > ul > li > a')
times = soup.select('span.pc_temp_tips_r > span')
for rank,title,time in zip(ranks,titles,times):
data = {
"rank":rank.get_text().strip(),
"singer":title.get_text().replace("\n","").replace("\t","").split('-')[1],
"song":title.get_text().replace("\n","").replace("\t","").split('-')[0],
"time":time.get_text().strip()
}
print(data)
if __name__ == '__main__':
urls = ["https://www.kuGou.com/yy/rank/home/{}-8888.html".fORMat(str(i)) for i in range(1,24)]
for url in urls:
get_info(url)
time.sleep(1)
到此这篇关于python爬取酷狗音乐Top500榜单的文章就介绍到这了,更多相关python爬取酷狗音乐榜单内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: python爬取酷狗音乐Top500榜单
本文链接: https://lsjlt.com/news/138192.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0