Python 官方文档:入门教程 => 点击学习
目录从ResNet到DenseNet稠密块体过渡层DenseNet模型训练模型从ResNet到DenseNet 上图中,左边是ResNet,右边是DenseNet,它们在跨层上的

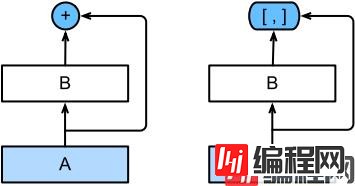
上图中,左边是ResNet,右边是DenseNet,它们在跨层上的主要区别是:使用相加和使用连结。

最后,将这些展开式结合到多层感知机中,再次减少特征的数量。实现起来非常简单:我们不需要添加术语,而是将它们连接起来。DenseNet这个名字由变量之间的“稠密连接”而得来,最后一层与之前的所有层紧密相连。稠密连接如下图所示:
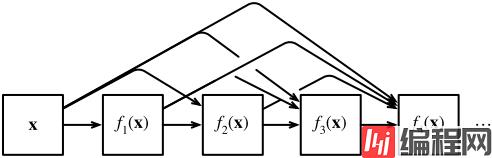
稠密网络主要由2部分构成:稠密块(dense block)和过渡层(trainsition block)。
前者定义如何连接输入和输出,而后者则控制通道数量,使其不会太复杂。
DenseNet使用了ResNet改良版的“批量归一化、激活和卷积”结构。我们首先实现下这个结构。
import torch
from torch import nn
from d2l import torch as d2l
def conv_block(input_channels, num_channels):
return nn.Sequential(
nn.BatchNORM2d(input_channels), nn.ReLU(),
nn.Conv2d(input_channels, num_channels, kernel_size=3, padding=1)
)
一个稠密块由多个卷积块组成,每个卷积块使用相同矢量的输出通道。然而,在前向传播中,我们将每个卷积块的输入和输出在通道维上连结。
class DenseBlock(nn.Module):
def __init__(self, num_convs, input_channels, num_channels):
super(Denseblock, self).__init__()
layer = []
for i in range(num_convs):
layer.append(conv_block(num_channels * i + input_channels, num_channels))
self.net = nn.Sequential(*layer)
def forward(self, X):
for blk in self.net:
Y = blk(X)
# 连结通道维度上的每个块的输入和输出
X = torch.cat((X, Y), dim=1)
return X
在下面的例子中,我们定义一个有2个输出通道数为10的DenseBlock。使用通道数为3的输入时,我们会得到通道数为 3 + 2 × 10 = 23 3+2\times10=23 3+2×10=23的输出。卷积块的通道数控制了输出通道数相对于输入通道数的增长,因此也被称为增长率(growth rate)。
blk = DenseBlock(2, 3, 10)
X = torch.randn(4, 3, 8, 8)
Y = blk(X)
Y.shape
torch.Size([4, 23, 8, 8])
由于每个稠密快都会带来通道数的增加,使用过多则会过于复杂化模型。而过渡层可以用来控制模型复杂度。它通过 1×1卷积层来减小通道数,并使用步幅为2的平均汇聚层减半高和宽,从而进一步降低模型复杂度。
def transition_block(input_channels, num_channels):
return nn.Sequential(
nn.BatchNorm2d(input_channels), nn.ReLU(),
nn.Conv2d(input_channels, num_channels, kernel_size=1)
nn.AvgPool2d(kernel_size=2, stride=2)
)
对上一个例子中稠密块的输出使用通道数为10的过渡层。此时输出的通道数减为10,高和宽均减半。
blk = transition_block(23, 10)
blk(Y).shape
torch.Size([4, 10, 4, 4])
我们来构造DenseNet模型。DenseNet首先使用同ResNet一样的单卷积层和最大聚集层。
b1 = nn.Sequential(
nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
接下来,类似于ResNet使用的4个残差块,DenseNet使用的是4个稠密块。与ResNet类似,我们可以设置每个稠密块使用多少个卷积层。这里我们设成4,从而与之前的ResNet-18保持一致。稠密块里的卷积层通道数(即增长率)设置为32,所以每个稠密块将增加128个通道。
在每个模块之间,ResNet通过步幅为2的残差块减小高和宽,而DenseNet则使用过渡层来减半高和宽,并减半通道数。
# 'num_channels'为当前通道数
num_channels, growth_rate = 64, 32
num_convs_in_dense_blocks = [4, 4, 4, 4]
blks = []
for i, num_convs in enumerate(num_convs_in_dense_blocks):
blks.append(DenseBlock(num_convs, num_channels, growth_rate))
# 上一个稠密块的输出通道数
num_channels += num_convs * growth_rate
# 在稠密块之间添加一个转换层,使通道数量减半
if i != len(num_convs_in_dense_blocks) - 1:
blks.append(transition_block(num_channels, num_channels // 2))
num_channels = num_channels // 2
与ResNet类似,最后接上全局汇聚层和全连接层来输出结果。
net = nn.Sequential(
b1, *blks,
nn.BatchNorm2d(num_channels), nn.ReLU(),
nn.AdaptiveMaxPool2d((1, 1)),
nn.Flatten(),
nn.Linear(num_channels, 10)
)
由于这里使用了比较深的网络,本节里我们将输入高和宽从224降到96来简化计算。
lr, num_epochs, batch_size = 0.1, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
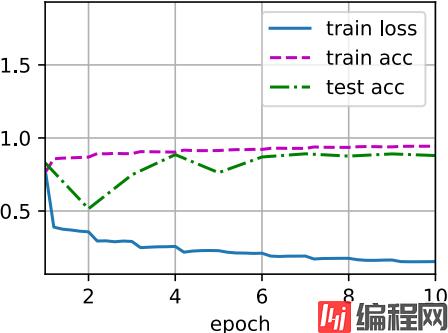
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
loss 0.154, train acc 0.943, test acc 0.880
5506.9 examples/sec on cuda:0
以上就是python机器学习从ResNet到DenseNet示例详解的详细内容,更多关于Python机器学习ResNet到DenseNet的资料请关注编程网其它相关文章!
--结束END--
本文标题: Python机器学习从ResNet到DenseNet示例详解
本文链接: https://lsjlt.com/news/137733.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0