目录前言 数据结构 常规实现 string转[]byte []byte转string 高效实现 性能测试 总结 前言 当我们使用Go进行数据序列化或反序列化操作时,可能经常涉及到字
当我们使用Go进行数据序列化或反序列化操作时,可能经常涉及到字符串和字节数组的转换。例如:
if str, err := JSON.Marshal(from); err != nil {
panic(err)
} else {
return string(str)
}
json序列化后为[]byte类型,需要将其转换为字符串类型。当数据量小时,类型间转换的开销可以忽略不计,但当数据量增大后,可能成为性能瓶颈,使用高效的转换方法能减少这方面的开销
在了解其如何转换前,需要了解其底层数据结构
本文基于go 1.13.12
string:
type stringStruct struct {
str unsafe.Pointer
len int
}
slice:
type slice struct {
array unsafe.Pointer
len int
cap int
}
与slice的结构相比,string缺少一个表示容量的cap字段,因此不能对string遍历使用内置的cap()函数那为什么string不需要cap字段呢?因为go中string被设计为不可变类型(当然在很多其他语言中也是),由于其不可像slice一样追加元素,也就不需要cap字段判断是否超出底层数组的容量,来决定是否扩容
只有len属性不影响for-range等读取操作,因为for-range操作只根据len决定是否跳出循环
那为什么字符串要设定为不可变呢?因为这样能保证字符串的底层数组不发生改变
举个例子,map中以string为键,如果底层字符数组改变,则计算出的哈希值也会发生变化,这样再从map中定位时就找不到之前的value,因此其不可变特性能避免这种情况发生,string也适合作为map的键。除此之外,不可变特性也能保障数据的线程安全
字符串不可变有很多好处,为了维持其不可变特性,字符串和字节数组互转一般是通过数据拷贝的方式实现:
var a string = "hello world"
var b []byte = []byte(a) // string转[]byte
a = string(b) // []byte转string
这种方式实现简单,但是通过底层数据复制实现的,在编译期间分别转换成对slicebytetostring和stringtoslicebyte的函数调用
func stringtoslicebyte(buf *tmpBuf, s string) []byte {
var b []byte
if buf != nil && len(s) <= len(buf) {
*buf = tmpBuf{}
b = buf[:len(s)]
} else {
// 申请内存
b = rawbyteslice(len(s))
}
// 复制数据
copy(b, s)
return b
}
其根据返回值是否逃逸到堆上,以及buf的长度是否足够,判断选择使用buf还是调用rawbyteslice申请一个slice。但不管是哪种,都会执行一次copy拷贝底层数据
func slicebytetostring(buf *tmpBuf, b []byte) (str string) {
l := len(b)
if l == 0 {
return ""
}
if l == 1 {
stringStructOf(&str).str = unsafe.Pointer(&staticbytes[b[0]])
stringStructOf(&str).len = 1
return
}
var p unsafe.Pointer
if buf != nil && len(b) <= len(buf) {
p = unsafe.Pointer(buf)
} else {
p = mallocGC(uintptr(len(b)), nil, false)
}
// 赋值底层指针
stringStructOf(&str).str = p
// 赋值长度
stringStructOf(&str).len = len(b)
// 拷贝数据
memmove(p, (*(*slice)(unsafe.Pointer(&b))).array, uintptr(len(b)))
return
}
首先处理长度为0或1的情况,再判断使用buf还是通过mallocgc新申请一段内存,但无论哪种方式,最后都要拷贝数据
这里设置了转换后字符串的len属性
如果程序保证不对底层数据进行修改,那么只转换类型,不拷贝数据,是否可以提高性能?
unsafe.Pointer,int,uintpt这三种类型占用的内存大小相同
var v1 unsafe.Pointer
var v2 int
var v3 uintptr
fmt.Println(unsafe.Sizeof(v1)) // 8
fmt.Println(unsafe.Sizeof(v2)) // 8
fmt.Println(unsafe.Sizeof(v3)) // 8
因此从底层结构上来看string可以看做[2]uintptr,[]byte切片类型可以看做 [3]uintptr
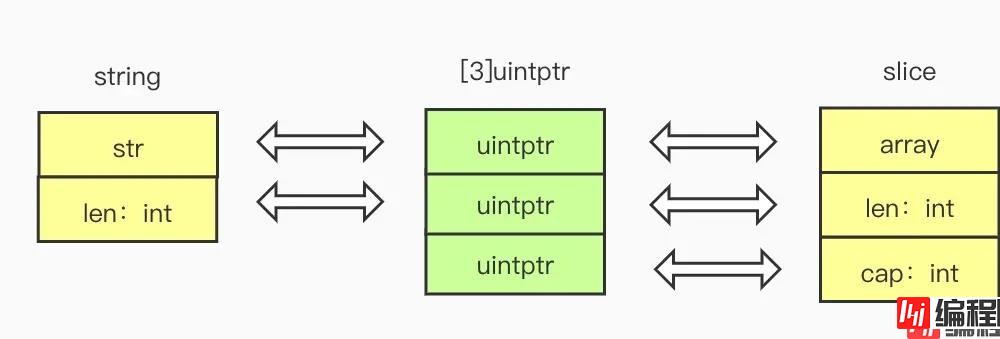
那么从string转[]byte只需构建出 [3]uintptr{ptr,len,len}
这里我们为slice结构生成了cap字段,其实这里不生成cap字段对读取操作没有影响,但如果要往转换后的slice append元素可能有问题,原因如下:
这样做slice的cap属性是随机的,可能是大于len的值,那么append时就不会新开辟一段内存存放元素,而是在原数组后面追加,如果后面的内存不可写就会panic
[]byte转string更简单,直接转换指针类型即可,忽略cap字段
实现如下:
func stringTobyteSlice(s string) []byte {
tmp1 := (*[2]uintptr)(unsafe.Pointer(&s))
tmp2 := [3]uintptr{tmp1[0], tmp1[1], tmp1[1]}
return *(*[]byte)(unsafe.Pointer(&tmp2))
}
func byteSliceToString(bytes []byte) string {
return *(*string)(unsafe.Pointer(&bytes))
}
这里使用unsafe.Pointer来转换不同类型的指针,没有底层数据的拷贝
接下来对高效实现进行性能测试,这里选用长度为100的字符串或字节数组进行转换
分别测试以下4个方法:
func stringTobyteSlice(s string) []byte {
tmp1 := (*[2]uintptr)(unsafe.Pointer(&s))
tmp2 := [3]uintptr{tmp1[0], tmp1[1], tmp1[1]}
return *(*[]byte)(unsafe.Pointer(&tmp2))
}
func stringTobyteSliceOld(s string) []byte {
return []byte(s)
}
func byteSliceToString(bytes []byte) string {
return *(*string)(unsafe.Pointer(&bytes))
}
func byteSliceToStringOld(bytes []byte) string {
return string(bytes)
}
测试结果如下:
BenchmarkStringToByteSliceOld-12 28637332 42.0 ns/op
BenchmarkStringToByteSliceNew-12 1000000000 0.496 ns/op
BenchmarkByteSliceToStringOld-12 32595271 36.0 ns/op
BenchmarkByteSliceToStringNew-12 1000000000 0.256 ns/op
可以看出性能差距比较大,如果需要转换的字符串或字节数组长度更长,性能提升更加明显
本文介绍了字符串和数组的底层数据结构,以及高效的互转方法,需要注意的是,其适用于程序能保证不对底层数据进行修改的场景。若不能保证,且底层数据被修改可能引发异常,则还是使用拷贝的方式
到此这篇关于Go中string与[]byte高效互转的文章就介绍到这了,更多相关Go中string与[]byte互转内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: Go中string与[]byte高效互转的方法实例
本文链接: https://lsjlt.com/news/136245.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-04-05
2024-04-05
2024-04-05
2024-04-04
2024-04-05
2024-04-05
2024-04-05
2024-04-05
2024-04-04
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0