Python 官方文档:入门教程 => 点击学习
目录元素存储关系继承体系属性构造方法无参有参按插入顺序访问newnodelinkNodeLast链表节点的删除LRU(Least recently used,最近最少使用)栗子元素被
LinkedHashMap维护插入的顺序。
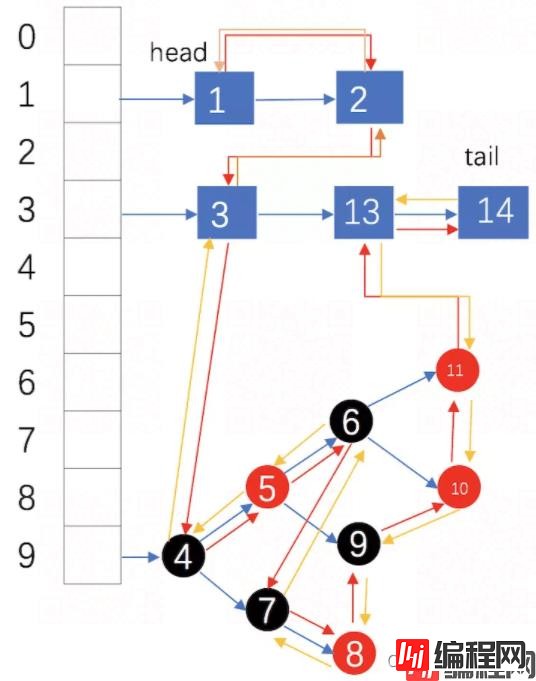
红黄箭头:元素添加顺序
蓝箭头:单链表各个元素的存储顺序
head:链表头部
tail:链表尾部



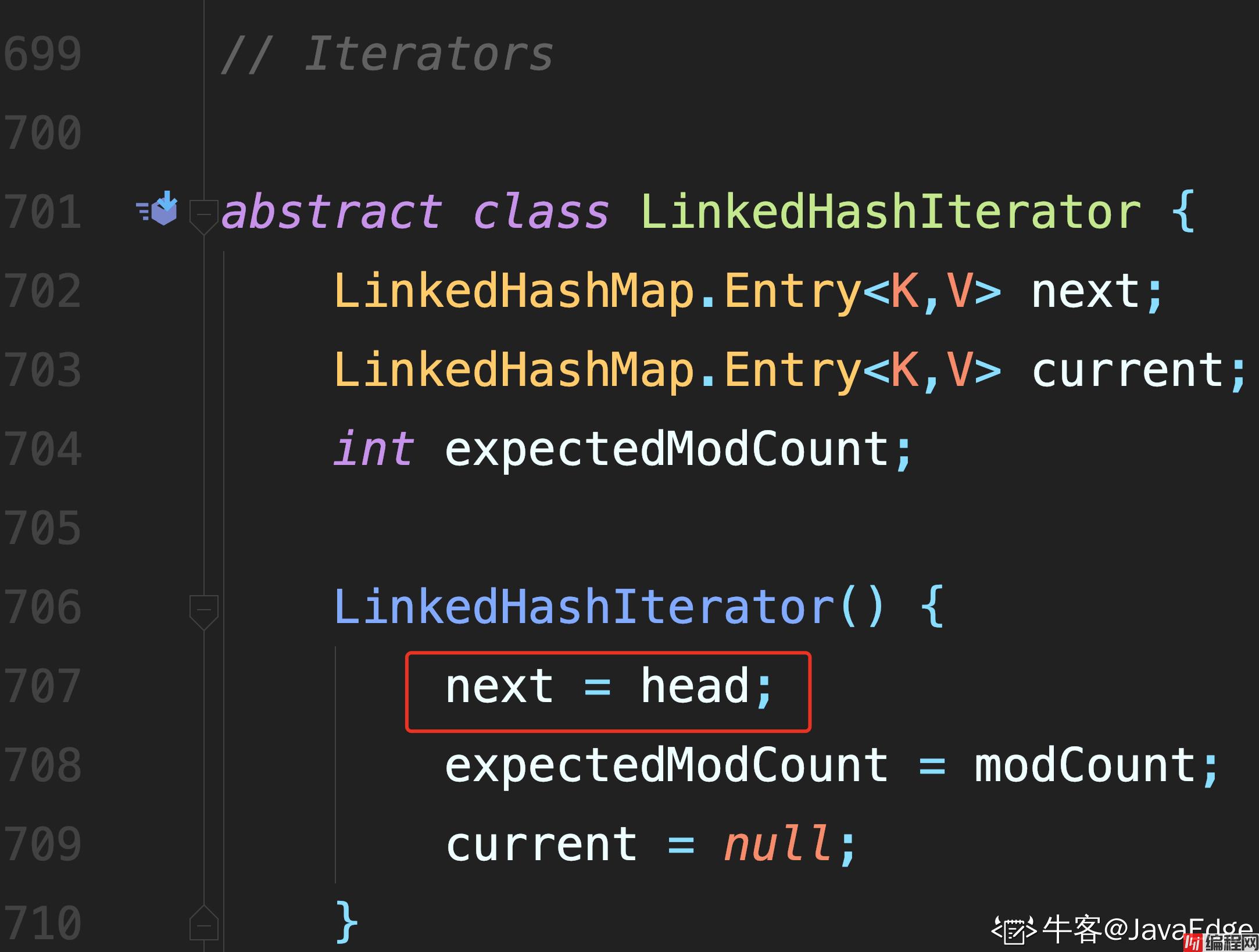
此 LinkedHashMap 的迭代排序方法:

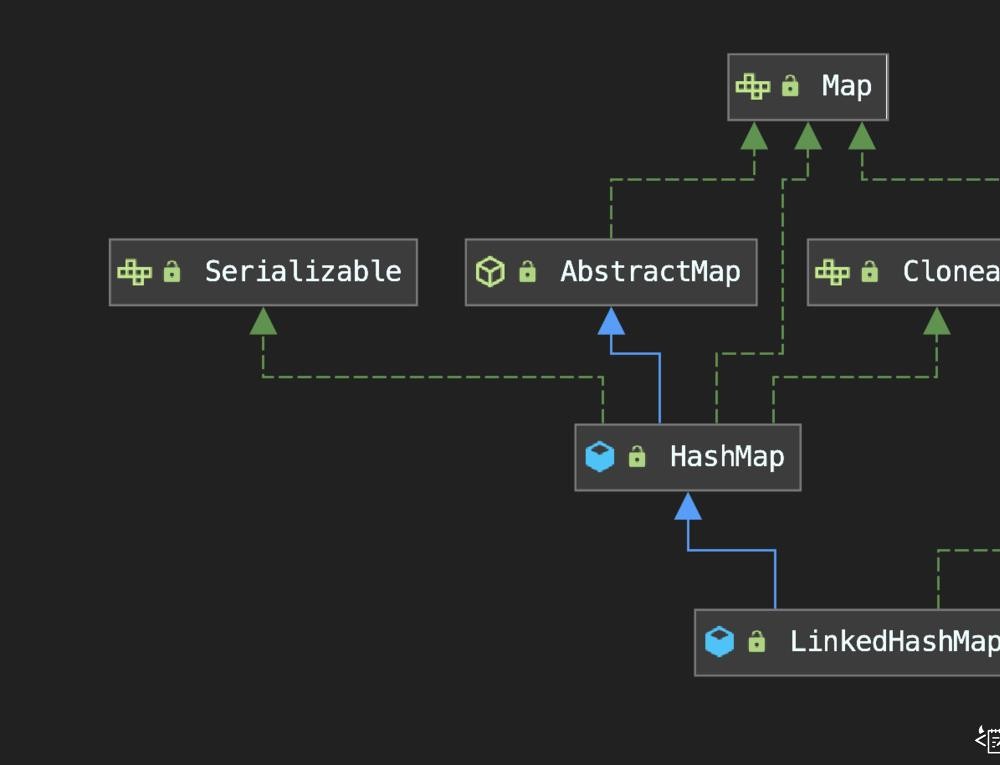
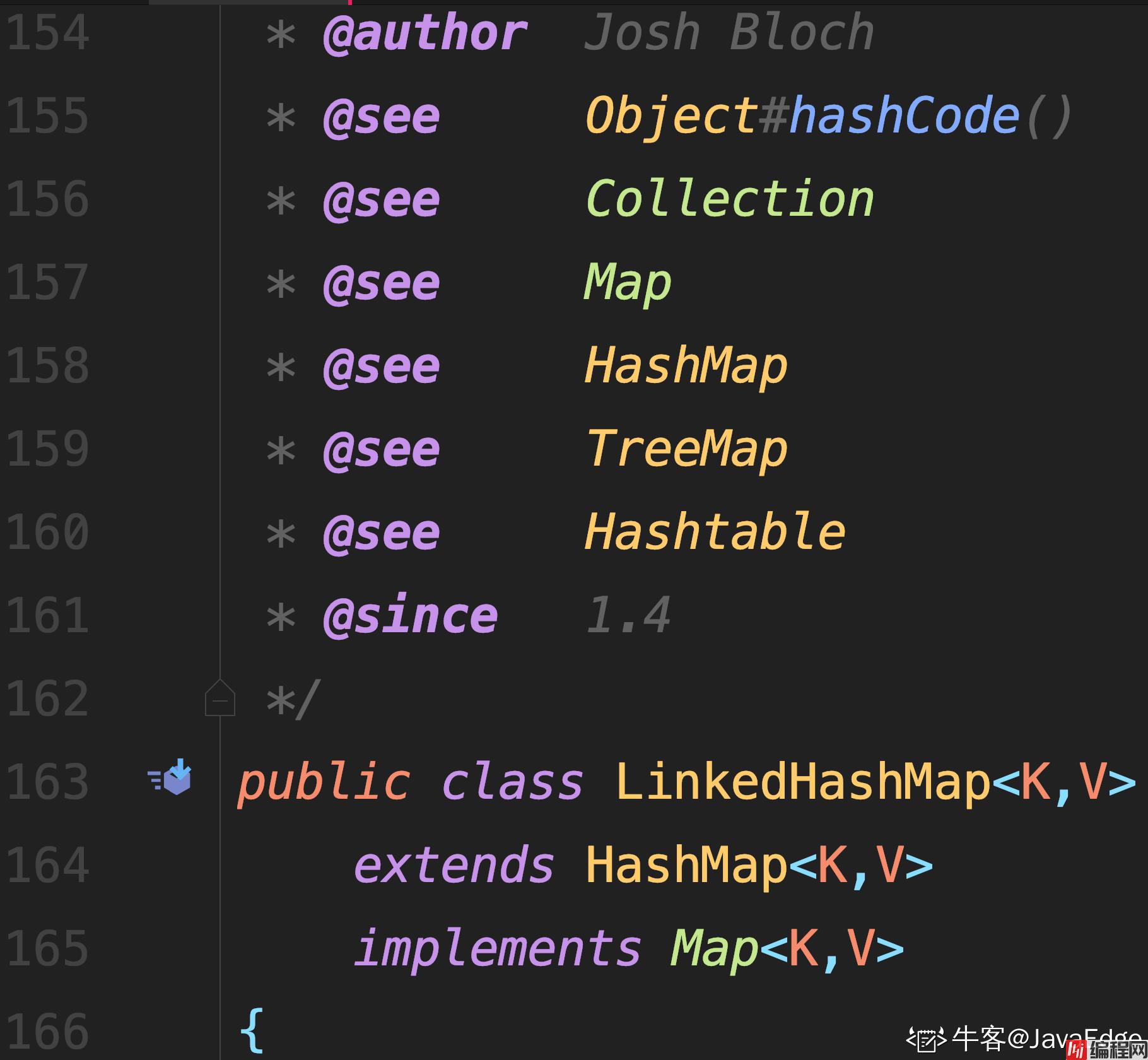
构造方法都是先执行父类 HashMap 的构造方法.



下面我们开始研究该类的主要特性是如何通过代码实现的.
LinkedHashMap 默认 accessOrder 为 false,提供按照插入顺序的访问,并没有重写父类 HashMap 的 put 方法.但在 HashMap 中,put 的是 HashMap 的 Node 类型节点,LinkedHashMap 的 Entry 与其结构并不同,又是怎样建立起双向链表的呢?下面一起看下 LinkedHashMap 插入相关代码.
忽略未重写的 put=>putValue代码部分,我们直接观察重写的


控制新增节点追加到链表的尾部,这样每次新节点都追加到尾部,即可保证插入顺序了.
继续研究 linkNodeLast
新增节点,并追加到链表的尾部.
`// link at the end of list`
`private` `void` `linkNodeLast(LinkedHashMap.Entry<K,V> p) {`
`LinkedHashMap.Entry<K,V> last = tail;`
`// 新增于尾节点`
`tail = p;`
`// last 为null,说明链表为空`
`if` `(last == ``null``)`
`head = p;`
`// 链表非空,建立新节点和上一个尾节点的前后关系`
`else` `{`
`// 将新节点 p 直接接在链尾`
`p.before = last;`
`last.after = p;`
`}`
`}`
由此得知,通过在 HashMap 基础上新增的头尾节点,节点的 before 和 after 属性,就能实现在每次新增时,把节点直接追加到尾节点,即可达到维护按照插入顺序的链表结构的目的!
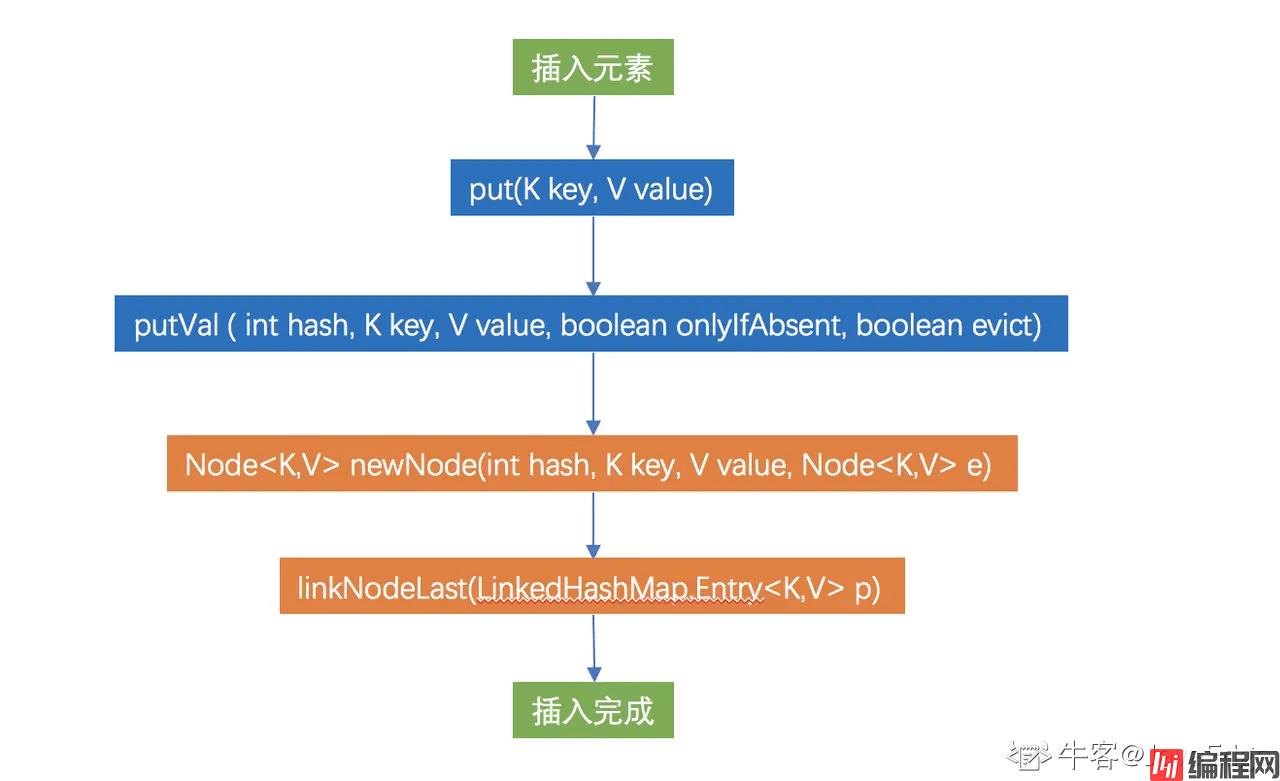
蓝色部分是 HashMap 的方法
橙色部分为 LinkedHashMap 独有方法
注意 LinkedHashMap 虽然也是双向链表,但只提供单向的按插入的顺序从头到尾访问,不及 LinkedList 般可双向无死角访问.
迭代过程中,不断访问 after 节点即可完成遍历.
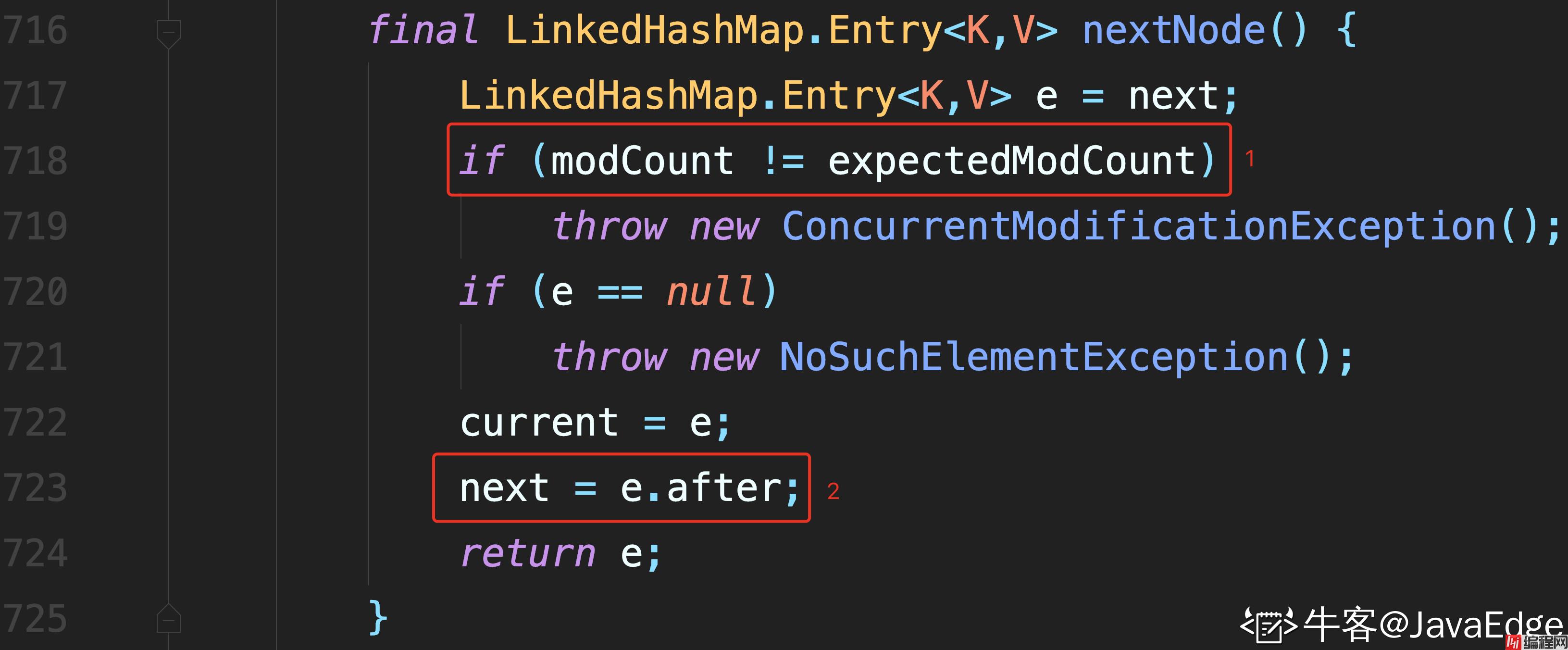
1 处进行校验
2 处通过节点的 after 属性,找到后继节点

与插入操作一样,LinkedHashMap 删除操作相关的代码也是直接用父类的实现. 在删除节点时,父类不会修复 LinkedHashMap 的双向链表。那么删除及节点后,被删除的节点该如何从双链表中安全移除呢?其实在删除节点后,回调方法 afterNodeRemoval 会被调用。LinkedHashMap 重写了该方法.
`// e 为已经删除的节点`
`void` `afterNodeRemoval(Node<K,V> e) { ``// unlink`
`LinkedHashMap.Entry<K,V> p =`
`(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;`
`// 将 p 节点的前驱后后继引用置 null,辅助 GC`
`p.before = p.after = ``null``;`
`// p.before 为 null,表明 p 是头节点`
`if` `(b == ``null``)`
`head = a;`
`else`
`// 否则将 p 的前驱节点连接到 p 的后继节点`
`b.after = a;`
`// a 为 null,表明 p 是尾节点`
`if` `(a == ``null``)`
`tail = b;`
`else`
`// 否则将 a 的前驱节点连接到 b`
`a.before = b;`
`}`
删除元素的主要流程:
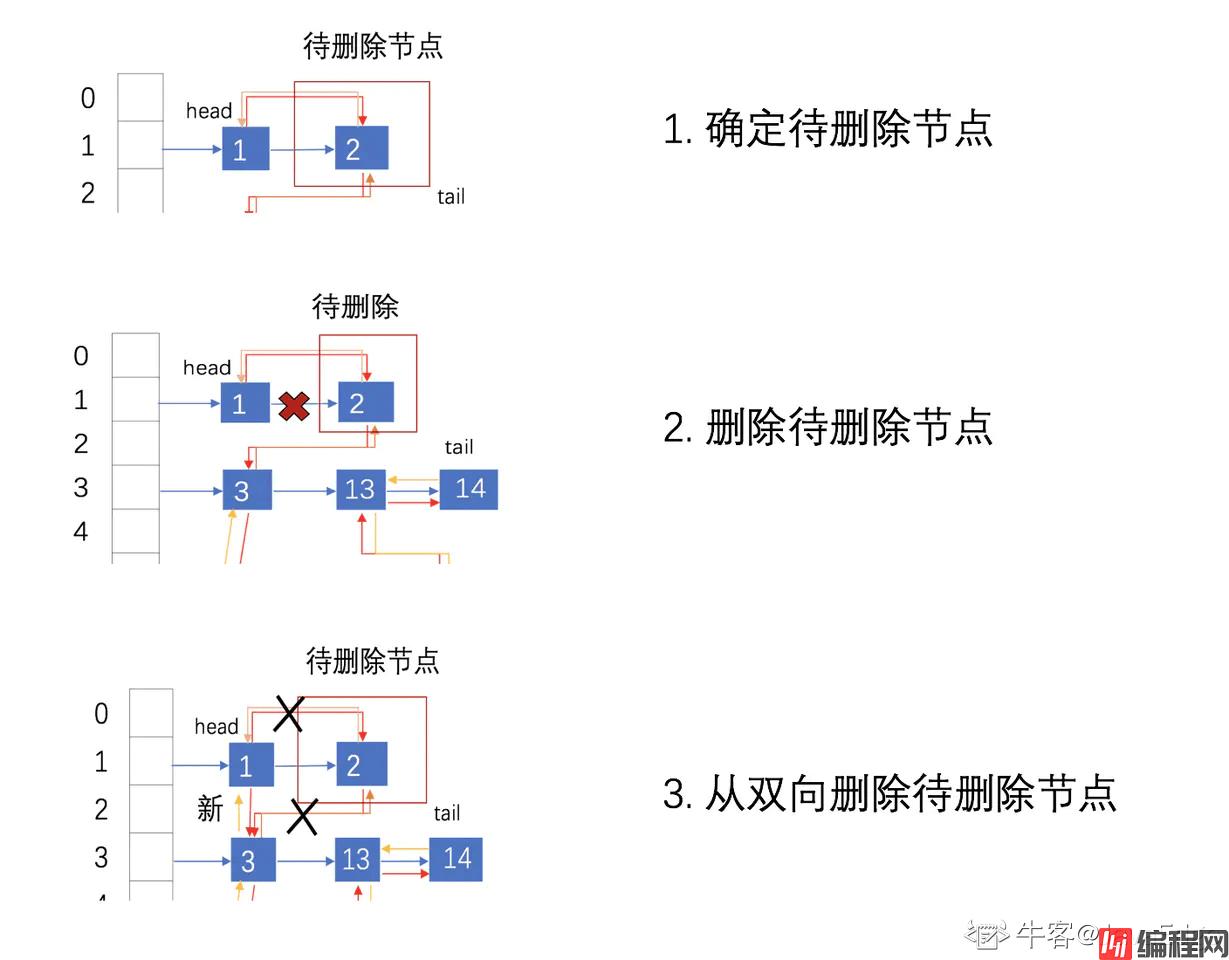
转存失败重新上传取消
经常访问的元素会被追加到队尾,这样不经常访问的数据自然就靠近队头,然后可以通过设置删除策略,比如当 Map 元素个数大于多少时,把头节点删除
get 时,元素会被移动到队尾:

`public` `V get(Object key) {`
`Node<K,V> e;`
`// 调用 HashMap get 方法`
`if` `((e = getNode(hash(key), key)) == ``null``)`
`return` `null``;`
`// 如果设置了 LRU 策略`
`if` `(accessOrder)`
`// 这个方法把当前 key 移动到队尾`
`afterNodeAccess(e);`
`return` `e.value;`
`}`
从上述源码中,可以看到,通过 afterNodeAccess 方法把当前访问节点移动到了队尾,其实不仅仅是 get 方法,执行 getOrDefault、compute、computeIfAbsent、computeIfPresent、merge 方法时,也会这么做,通过不断的把经常访问的节点移动到队尾,那么靠近队头的节点,自然就是很少被访问的元素了。
到此这篇关于源码解析带你了解LinkedHashMap的文章就介绍到这了,更多相关Java LinkedHashMap内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: 源码解析带你了解LinkedHashMap
本文链接: https://lsjlt.com/news/135727.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0