Python 官方文档:入门教程 => 点击学习
目录kafka消息堆积及分区不均匀的解决1、先在kafka消息中创建2、添加配置文件application.properties3、创建kafka工厂4、展示kafka消费者kafk
我在环境中发现代码里面的kafka有所延迟,查看kafka消息发现堆积严重,经过检查发现是kafka消息分区不均匀造成的,消费速度过慢。这里由自己在虚拟机上演示相关问题,给大家提供相应问题的参考思路。
这篇文章有点遗憾并没重现分区不均衡的样例和Warning: Consumer group ‘testGroup1' is rebalancing. 这里仅将正确的方式展示,等后续重现了在进行补充。
主要有两个要点:
对应分区数目的topic(testTopic2,testTopic3)testTopic1由代码创建
./kafka-topics.sh --create --ZooKeeper 192.168.25.128:2181 --replication-factor 1 --partitions 2 --topic testTopic2
kafka.test.topic1=testTopic1
kafka.test.topic2=testTopic2
kafka.test.topic3=testTopic3
kafka.broker=192.168.25.128:9092
auto.commit.interval.time=60000
#kafka.test.group=customer-test
kafka.test.group1=testGroup1
kafka.test.group2=testGroup2
kafka.test.group3=testGroup3
kafka.offset=earliest
kafka.auto.commit=false
session.timeout.time=10000
kafka.concurrency=2
package com.yin.customer.config;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.config.KafkaListenerContainerFactory;
import org.springframework.kafka.core.ConsumerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
import org.springframework.kafka.listener.AbstractMessageListenerContainer;
import org.springframework.kafka.listener.ConcurrentMessageListenerContainer;
import org.springframework.kafka.listener.ContainerProperties;
import org.springframework.stereotype.Component;
import java.util.HashMap;
import java.util.Map;
@Configuration
@Component
public class KafkaConfig {
@Value("${kafka.broker}")
private String broker;
@Value("${kafka.auto.commit}")
private String autoCommit;
// @Value("${kafka.test.group}")
//private String testGroup;
@Value("${session.timeout.time}")
private String sessionOutTime;
@Value("${auto.commit.interval.time}")
private String autoCommitTime;
@Value("${kafka.offset}")
private String offset;
@Value("${kafka.concurrency}")
private Integer concurrency;
@Bean
KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<String, String>> kafkaListenerContainerFactory(){
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
//监听设置两个个分区
factory.setConcurrency(concurrency);
//打开批量拉取数据
factory.setBatchListener(true);
//这里设置的是心跳时间也是拉的时间,也就说每间隔max.poll.interval.ms我们就调用一次poll,kafka默认是300s,心跳只能在poll的时候发出,如果连续两次poll的时候超过
//max.poll.interval.ms 值就会导致rebalance
//心跳导致GroupCoordinator以为本地consumer节点挂掉了,引发了partition在consumerGroup里的rebalance。
// 当rebalance后,之前该consumer拥有的分区和offset信息就失效了,同时导致不断的报auto offset commit failed。
factory.getContainerProperties().setPollTimeout(3000);
factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL_IMMEDIATE);
return factory;
}
private ConsumerFactory<String,String> consumerFactory() {
return new DefaultKafkaConsumerFactory<String, String>(consumerConfigs());
}
@Bean
public Map<String, Object> consumerConfigs() {
Map<String, Object> propsMap = new HashMap<>();
//kafka的地址
propsMap.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, broker);
//是否自动提交 Offset
propsMap.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, autoCommit);
// enable.auto.commit 设置成 false,那么 auto.commit.interval.ms 也就不被再考虑
//默认5秒钟,一个 Consumer 将会提交它的 Offset 给 Kafka
propsMap.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 5000);
//这个值必须设置在broker configuration中的group.min.session.timeout.ms 与 group.max.session.timeout.ms之间。
//zookeeper.session.timeout.ms 默认值:6000
//ZooKeeper的session的超时时间,如果在这段时间内没有收到ZK的心跳,则会被认为该Kafka server挂掉了。
// 如果把这个值设置得过低可能被误认为挂掉,如果设置得过高,如果真的挂了,则需要很长时间才能被server得知。
propsMap.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, sessionOutTime);
propsMap.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
propsMap.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
//组与组间的消费者是没有关系的。
//topic中已有分组消费数据,新建其他分组ID的消费者时,之前分组提交的offset对新建的分组消费不起作用。
//propsMap.put(ConsumerConfig.GROUP_ID_CONFIG, testGroup);
//当创建一个新分组的消费者时,auto.offset.reset值为latest时,
// 表示消费新的数据(从consumer创建开始,后生产的数据),之前产生的数据不消费。
// https://blog.csdn.net/u012129558/article/details/80427016
//earliest 当分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费。
// latest 当分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据。
propsMap.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, offset);
//不是指每次都拉50条数据,而是一次最多拉50条数据()
propsMap.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 5);
return propsMap;
}
}
@Component
public class KafkaConsumer {
private static final Logger logger = LoggerFactory.getLogger(KafkaConsumer.class);
@KafkaListener(topics = "${kafka.test.topic1}",groupId = "${kafka.test.group1}",containerFactory = "kafkaListenerContainerFactory")
public void listenPartition1(List<ConsumerRecord<?, ?>> records,Acknowledgment ack) {
logger.info("testTopic1 recevice a message size :{}" , records.size());
try {
for (ConsumerRecord<?, ?> record : records) {
Optional<?> kafkaMessage = Optional.ofNullable(record.value());
logger.info("received:{} " , record);
if (kafkaMessage.isPresent()) {
Object message = record.value();
String topic = record.topic();
Thread.sleep(300);
logger.info("p1 topic is:{} received message={}",topic, message);
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
ack.acknowledge();
}
}
@KafkaListener(topics = "${kafka.test.topic2}",groupId = "${kafka.test.group2}",containerFactory = "kafkaListenerContainerFactory")
public void listenPartition2(List<ConsumerRecord<?, ?>> records,Acknowledgment ack) {
logger.info("testTopic2 recevice a message size :{}" , records.size());
try {
for (ConsumerRecord<?, ?> record : records) {
Optional<?> kafkaMessage = Optional.ofNullable(record.value());
logger.info("received:{} " , record);
if (kafkaMessage.isPresent()) {
Object message = record.value();
String topic = record.topic();
Thread.sleep(300);
logger.info("p2 topic :{},received message={}",topic, message);
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
ack.acknowledge();
}
}
@KafkaListener(topics = "${kafka.test.topic3}",groupId = "${kafka.test.group3}",containerFactory = "kafkaListenerContainerFactory")
public void listenPartition3(List<ConsumerRecord<?, ?>> records, Acknowledgment ack) {
logger.info("testTopic3 recevice a message size :{}" , records.size());
try {
for (ConsumerRecord<?, ?> record : records) {
Optional<?> kafkaMessage = Optional.ofNullable(record.value());
logger.info("received:{} " , record);
if (kafkaMessage.isPresent()) {
Object message = record.value();
String topic = record.topic();
logger.info("p3 topic :{},received message={}",topic, message);
Thread.sleep(300);
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
ack.acknowledge();
}
}
}
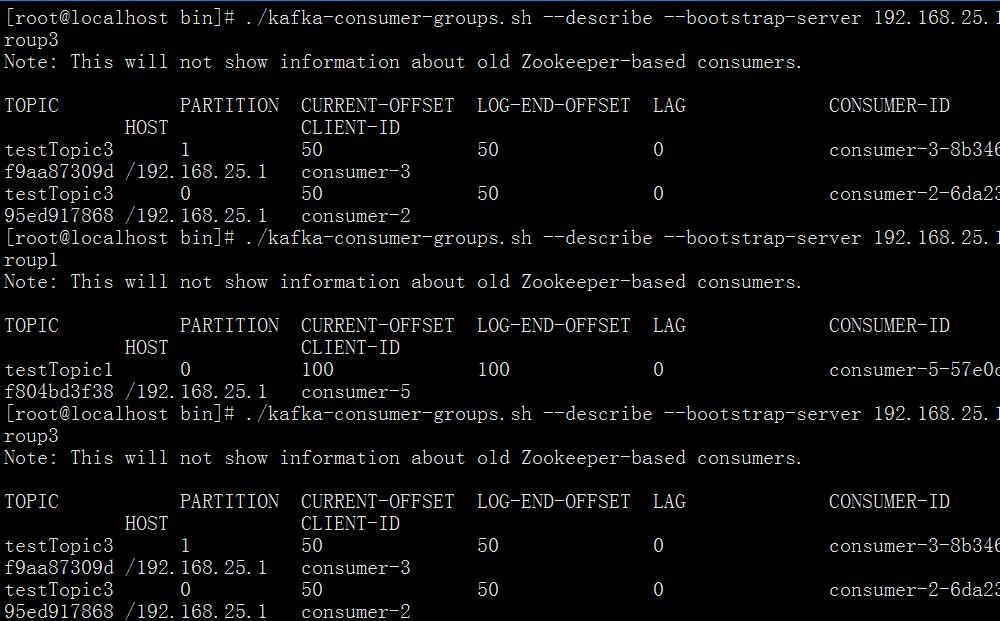
查看分区消费情况:
近日,有用户反馈kafka有topic出现某个消费组消费的时候,有几个分区一直不消费消息,消息一直积压(图1)。除了一直积压外,还有一个现象就是消费组一直在重均衡,大约每5分钟就会重均衡一次。具体表现为消费分区的owner一直在改变(图2)。
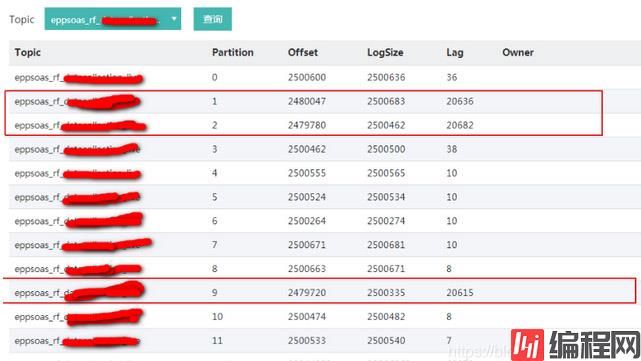
(图1)
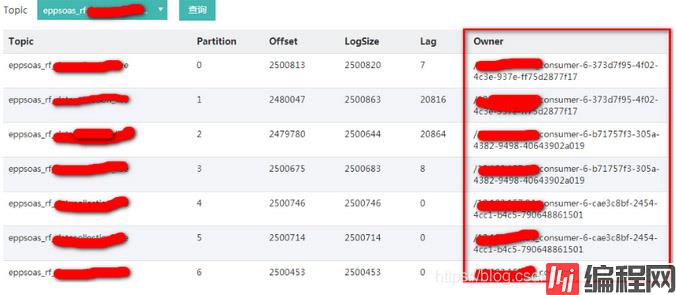
(图2)
业务侧没有报错,同时kafka服务端日志也一切正常,同事先将消费组的机器滚动重启,仍然还是那几个分区没有消费,之后将这几个不消费的分区迁移至别的broker上,依然没有消费。
还有一个奇怪的地方,就是每次重均衡后,不消费的那几个分区的消费owner所在机器的网络都有流量变化。按理说不消费应该就是拉取不到分区不会有流量的。于是让运维去拉了下不消费的consumer的jstack日志。一看果然发现了问题所在。

从堆栈看,consumer已经拉取到消息,然后就一直卡在处理消息的业务逻辑上。这说明kafka是没有问题的,用户的业务逻辑有问题。
consumer在拉取完一批消息后,就一直在处理这批消息,但是这批消息中有若干条消息无法处理,而业务又没有超时操作或者异常处理导致进程一直处于消费中,无法去poll下一批数据。
又由于业务采用的是autocommit的offset提交方式,而根据源码可知,consumer只有在下一次poll中才会自动提交上次poll的offset,所以业务一直在拉取同一批消息而无法更新offset。反映的现象就是该consumer对应的分区的offset一直没有变,所以有积压的现象。
至于为什么会一直在重均衡消费组的原因也很明了了,就是因为有消费者一直卡在处理消息的业务逻辑上,超过了max.poll.interval.ms(默认5min),消费组就会将该消费者踢出消费组,从而发生重均衡。
让业务方去查证业务日志,验证了积压的这几个分区,总是在循环的拉取同一批消息。
临时解决方法就是跳过有问题的消息,将offset重置到有问题的消息之后。本质上还是要业务侧修改业务逻辑,增加超时或者异常处理机制,最好不要采用自动提交offset的方式,可以手动管理。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持编程网。
--结束END--
本文标题: 解决kafka消息堆积及分区不均匀的问题
本文链接: https://lsjlt.com/news/135402.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0