目录背景问题拆解目标方案调研EventBus基于k-v的监听、通知全局共享数据Model实例基于注解的对象映射方案VM-Mapping特点思考突破View层级的限制突破类型的限制详细
西瓜在feed、详情页、个人主页有一块功能区,包括了点赞、收藏、关注等功能。这些功能长久以来都是孤立的:多个场景下点赞、收藏、关注等状态或数量不一致。在以往的业务迭代中,都是业务A有了需求,就加个点赞的请求,把自己业务模块的UI更新下就完事了,业务B也自己搞一下。当西瓜开始从切面发力互动业务的时候,这些问题就凸显出来了。线上出现了很多在页面A点赞/收藏完一个视频到页面B点赞/收藏状态或者点赞/收藏数不对的case。
例如:
在分析这块业务时,梳理出几种问题:
其中3、4点问题更像是逻辑bug。
多个端的数据同步可以通过跨端事件,每个端收到事件后更新自己就行。所以最复杂最难搞的问题就是端内多场景下的数据状态同步问题。

端内问题聚焦在几个case:
这个方案的本质是:监听者收到事件->更新UI/更新数据Model
以对象id为key,某个属性值如点赞数为value。事件发生时,将修改值写入k-v列表,监听者全部监听这个变化。当新进入一个场景时,查询k-v列表作为最新值。这个方案和Eventbus粘性事件很像。
同一个数据Model对象,比如一个卡片Model,每次更新都是全局可见的。但是很明显,
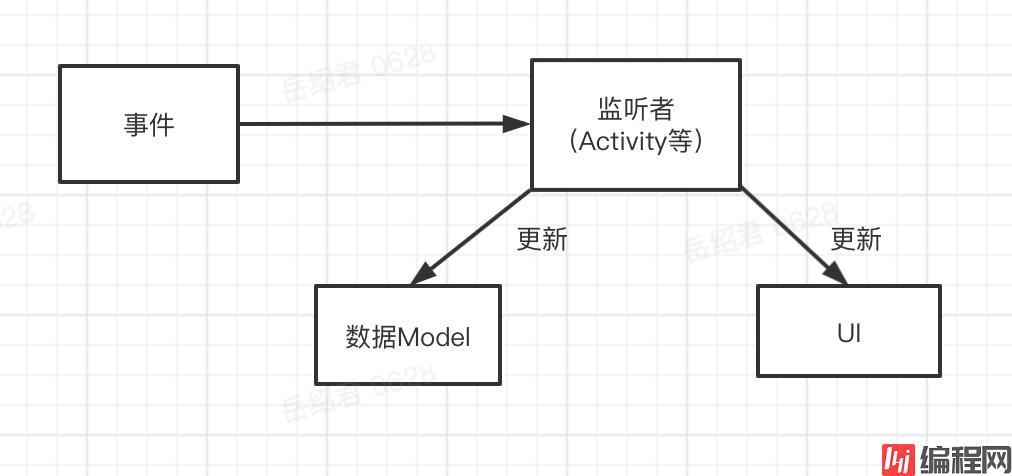
这个过程中有四个角色,三个操作。
从MVVM说起。
MVVM是一种软件设计典范,用一种业务逻辑、数据、界面显示分离的方法组织代码。

MVVM本质上是一种数据驱动UI的理念。从这个理念看,数据状态同步,同步的是数据Model,UI的变更是由数据的变更引起的,真正关注的点应该在数据本身上。
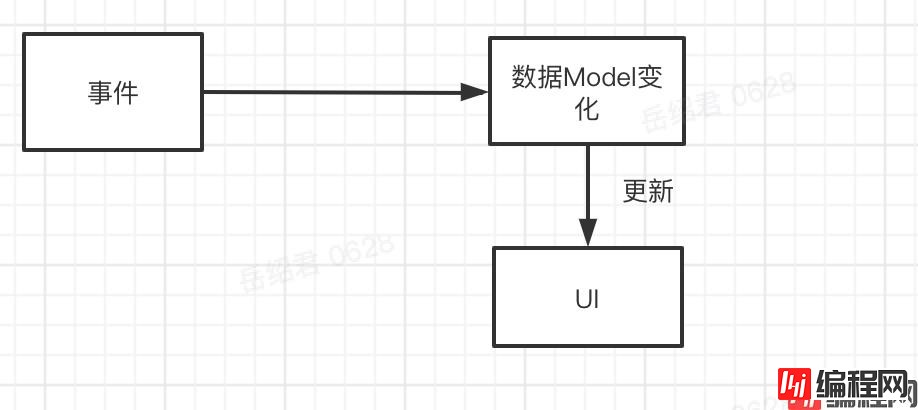
这样,就不再需要额外一个接受事件的“容器”,来控制数据和UI了。到现在,只有三个角色,两个操作了。
再回过头看,为什么跨页面、跨多View层级很难找到一个通用方案,是因为总在找一个“容器”来承载事件的接受,然后再做双份(数据和View)的同步。而且这个“容器”通常本身就是一个页面,或者其它不同层级上的view,本身就存在很多样化,为这种多样化适配,就会让事情变得复杂。
假如不再找额外的“容器”,直接把监听绑定在数据上,那么View层级的限制也就不存在了。因为不管在什么场景,什么层级,真正的逻辑中心都是数据,View也是通过数据渲染出来的,View不关心自己在什么层级,只关心数据的变化。
这里有几个类型的限制:
虽然类型不同,但是对A、B来说,都是要更新diggStatus的;
这个问题的本质是,类型约束是语言特性,但是和业务属性无关,只要他们能确认是一个业务含义,不管他们怎么换“马甲”,他们总是能匹配上的。
这样就演变成了:
第一个好说,主要能有唯一的业务标识,就能确定是一个业务含义;怎么确定属性的对应关系呢?
现有的技术体系里就有可以借鉴的思想:数据库的使用。像jetpack 的Room组件:
可以看到,我们只要要在应用层这么定义一个数据Model叫User,为它加上注解,就可以把数据库中的字段和我们的数据对应上。那么方案呼之欲出,注解是可以完成属性匹配的。
于是乎整个流程就简化成了:

这个流程可以看到,只剩下了两个角色,和两个操作了。
所谓数据更新UI,就是View-Model;数据映射数据,就是Data-Mapping,于是这个方案的名称就是VM-Mapping。
需要对上述抽象流程做实现。
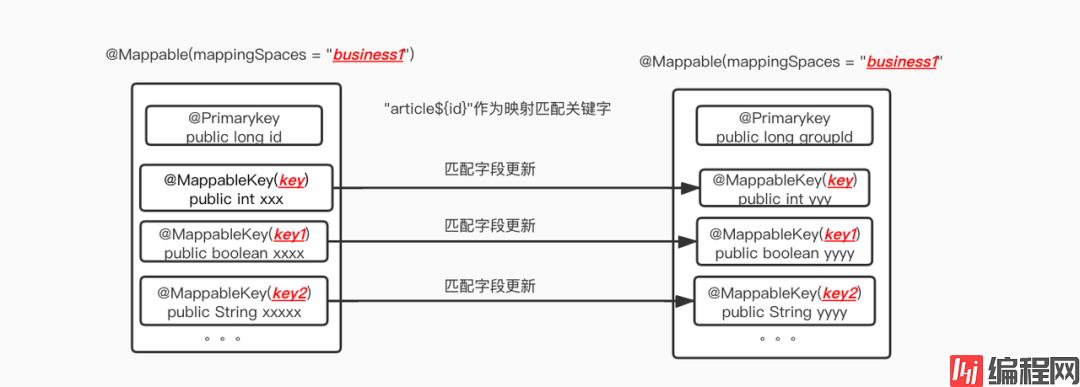
前面说到,映射关系由注解维护,一个有三个注解:
标注在class上,用来识别这个类是不是可以被处理。
其中mappingSpace是命名空间,表示是“一类”数据,可以和数据库表名对比理解,mappingSpace就是tableName。
标记在字段上,被标记的字段作为Model对象的唯一标识。
mappingSpace+PrimaryKey的值,就是在映射关系中的唯一业务标识。
标注在字段上,需要被映射对应的字段
映射关系说明:
Android里有很多类似理念的东西,比如LiveData,就是数据更新通知到UI上。本质上数据驱动UI,就是在数据Data<->UI 之间建一个“桥梁”。
这个不过LiveData并不适合用在这里,理由是:
VM-Mapping做了个简单方案。用了两级HashMap,一级HashMap使用业务唯一标识(mappingSpace+PrimaryKey的值)为KEY,二级使用WeakHashMap,以数据Model实例为KEY,XGViewModel为VALUE。维护数据Data 和 UI回调之间的关系:

XGViewModel维护了通知给UI的弱引用回调合集。一个数据Model实例对应了一个XGViewModel。
当映射发生时,会通过业务标识Key,查找所有还没有被回收的数据Model实例,然后通过对应的XGViewModel通知UI自己的变更。
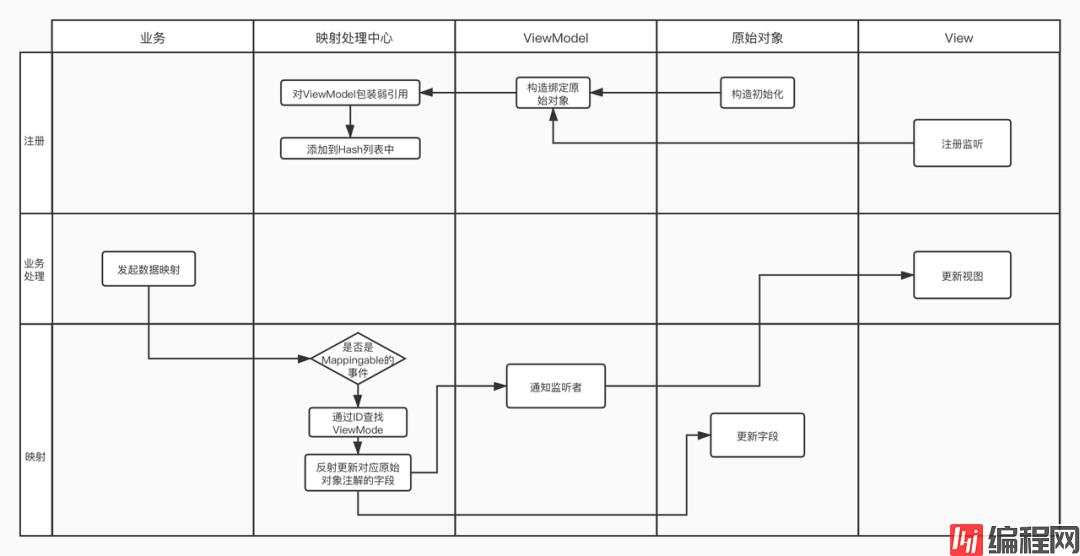
在这个流程中,业务使用只需要关心发起映射数据和更新视图。
因为存在列表,那么会有一个列表的维护者,就是所谓的映射中心。映射中心有两个核心能力:
但是注意,这个移除并不会影响VM-Mapping的能力,因为VM-Mapping关注的是数据本身,当数据被回收的时候,不会有任何场景会用到这个数据,自然也不用关心是不是需要通知到它。
| 方案 | 优势 | 劣势 |
|---|---|---|
| Eventbus | 理解成本低 | 事件、UI、数据Model三个角色都要保持一致,适配各种场景的成本高,不通用。 |
| 全局共享数据Model实例 | 使用简单 | 条件苛刻;占用内存,膨胀不可控制。 |
| 基于k-v的监听、通知 | 各场景通用 | 粒度太细导致内存不可控制,移除策略会导致同步失效。事件需要手动同步数据Model。 |
| VM-Mapping | 使用简单,不需要手动同步回数据Model,在所有场景下通用。 | 用到了反射,有一部分性能损耗。 |
西瓜在之前遗留了大量的类似问题,一直没有好的方案解决,要么存在根本性缺陷,要么实施成本高。VM-Mapping支持了在西瓜中视频相关的核心场景快速接入,实现了线上点赞数异常问题清零。
到此这篇关于Android端内数据状态同步方案VM-Mapping详解的文章就介绍到这了,更多相关Android端内数据状态同步方案VM-Mapping内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: Android端内数据状态同步方案VM-Mapping详解
本文链接: https://lsjlt.com/news/134921.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-01-21
2023-10-28
2023-10-28
2023-10-27
2023-10-27
2023-10-27
2023-10-27
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0