Python 官方文档:入门教程 => 点击学习
目录CNN的PyTorch实现(LeNet)1. 任务目标2. 库的导入3. 模型定义4. 数据加载、处理5.模型训练整个代码CNN的Pytorch实现(LeNet)
上次写了一篇CNN的详解,可是累坏了老僧我。写完后拿给朋友看,朋友说你这Pytorch的实现方式对于新人来讲会很不友好,然后反问我说里面所有的细节你都明白了吗。我想想,的确如此。那个源码是我当时《动手学pytorch》的时候整理的,里面有很多包装过的函数,对于新入门的人来讲,的确是个大问题。于是,痛定思痛的我决定重新写Pytorch实现这一部分,理论部分我就不多讲了,咱们直接分析代码,此代码是来自Pytorch官方给出的LeNet Model。你可以使用Jupyter Notebook一行一行的学习,也可以使用PyCharm进行断点训练和Debug来学习。
没有看过理论部分的同学可以看我上篇文章:一文带你了解CNN(卷积神经网络)。
在整个讲解的过程中,其中的一些比较重要的代码我会引入一些例子来进行解释它的功能,如果你想先直接跑通代码,可以直接跳到代码汇总部分,Here we Go~
这是一个对于彩色图的10分类的问题,具体种类有:'plane', 'car', 'bird', 'cat','deer', 'dog', 'frog', 'horse', 'ship', 'truck',训练一个能够对其进行分类的分类器。
这一部分咱们就不说太多了吧,直接上code:
import torch # 张量的有关运算,如创建、索引、连接、转置....和numpy的操作很像
import torch.nn as nn # 八廓搭建神经网络层的模块、loss等等
import torch.nn.functional as F # 常用的激活函数都在这里面
import torchvision # 专门处理图像的库
import torch.optim as optim # 各种参数优化方法,SGD、Adam...
import torchvision.transfORMs as transforms # 提供了一般的图像转换操作的类,也可以用于图像增强
import matplotlib.pyplot as plt
import numpy as np 我们在定义自己网络的时候,需要继承nn.Module类,并重新实现构造函数__init__和forward两个方法。forward方法是必须要重写的,它是实现模型的功能,实现各个层之间的连接关系的核心。如果你是用我下面的这个方法来定义的模型,在forward中要去连接它们之间的关系;如果你是用Sequential的方法来定义的模型,一般来讲可以直接在构造函数定义好后,在foward函数中return就行了(如果模型比较复杂就另当别论)。
class LeNet(nn.Module):
"""
下面这个模型定义没有用Sequential来定义,Sequential的定义方法能够在init中就给出各个层
之间的关系,我这里是根据是否有可学习的参数。我将可学习参数的层(如全连接、卷积)放在构造函数
中(其实你想把不具有参数的层放在里面也可以),把不具有学习参数的层(如dropout,
ReLU等激活函数、BN层)放在forward。
"""
def __init__(self):
super(LeNet,self).__init__()
# 第一个卷积块,这里输入的是3通道,彩色图。
self.conv1 = nn.Conv2d(3,16,5)
self.pool1 = nn.MaxPool2d(2,2)
# 第二个卷积块
self.conv2 = nn.Conv2d(16,32,5)
self.pool2 = nn.MaxPool2d(2,2)
# 稠密块,包含三个全连接层
self.fc1 = nn.Linear(32*5*5,120)
self.fc2 = nn.Linear(120,84)
self.fc3 = nn.Linear(84,10)
pass
def forward(self,x):
# x是输入数据,是一个tensor
# 正向传播
x = F.relu(self.conv1(x)) # input(3, 32, 32) output(16, 28, 28)
x = self.pool1(x) # output(16, 14, 14)
x = F.relu(self.conv2(x)) # output(32, 10, 10)
x = self.pool2(x) # output(32, 5, 5)
x = x.view(-1, 32*5*5) # output(32*5*5)
# 数据通过view展成一维向量,第一个参数-1是batch,自动推理;32x5x5是展平后的个数
x = F.relu(self.fc1(x)) # output(120)
x = F.relu(self.fc2(x)) # output(84)
x = self.fc3(x) # output(10)
# 为什么没有用softmax函数 --- 在网络模型中已经计算交叉熵以及概率
return x我们还可以随便看一下可训练参数:
model = LeNet()
for name,parameters in model.named_parameters():
if param.requires_grad:
print(name,':',parameters.size())
看一下实例化的模型:
import torch
input1 = torch.rand([32,3,32,32])
model = LeNet() # 模式实例化
print(model) # 看一下模型结构
output = model(input1)
这里就不再拓展了,我发4我发4,我会专门再写一篇使用pytorch查看特征矩阵 和卷积核参数的文章。
# 调用设备内的GPU并打印出来
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
# 定义图像数据的数据预处理方式
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 如果是第一次运行代码,没有下载数据集,则将download调制为True进行下载,并加载训练集
# transform是选择数据预处理的方式,我们已经提前定义
train_set = torchvision.datasets.CIFAR10(root='./data', train=True,
download=False,transform=transform)
# 如果你是windows系统,一定要记得把num_workers设置为0,不然会报错。
# 这个是将数据集划为为n个批次,每个批次的数据集有batchSize张图片,shuffle是打乱数据集
train_loader = torch.utils.data.DataLoader(train_set, batch_size=36,
shuffle=True, num_workers=0)
# 上面已经下载过的话,download设置为False
val_set = torchvision.datasets.CIFAR10(root='./data', train=False,
download=False, transform=transform)
# 验证集不用打乱,把batchsize设置为1,每次拿出1张来验证
val_loader = torch.utils.data.DataLoader(val_set, batch_size=1
shuffle=False, num_workers=0)
# 定义classes类别
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
val_data_iter = iter(val_loader) # 转换成可迭代的迭代器
val_image, val_label = val_data_iter.next()
# 定义imshow函数显示图像
def imshow(img):
img = img / 2 + 0.5 # unnormalize -> 反标准化处理
npimg = img.numpy() # numpy和tensor的通道顺序不同 tensor是通道度、宽度,numpy是高、宽、通
# 使用transpose调整维度
plt.imshow(np.transpose(npimg, (1, 2, 0))) #(1,2,0)-> 代表高度、宽度 通道
plt.show()
imshow(torchvision.utils.make_grid(val_image))
# 显示图像结果:
在这个图像加载部分,我做了些其它的尝试,想要去发现train_set和train_loader之间的不同。这里你可以逐行取消我注释的代码,然后去观察,去对比,你就知道有哪些不一样了。
"""
train_set:
总结:经过多次尝试,发现train_set是用一个Dataset包装起来,用索引来提取第n个数据,提出的数据是一个元组。
元组的第一个索引是Tensor的图像数据,(channel,height,width),索引的第二个数据是标签 int类型。
可以选择用enumerate迭代器,也可以直接进行索引,这里因为没有batchsize的维度,所以可以直接调用自己写的
imshow函数来显示图片
"""
for i,data in enumerate(train_set):
if i == 7:
# imshow(data[0])
# print(data[0])
# print(train_set[i][0]) # 查看train-set第七张图元组 的 索引0
print(train_set[i][0].shape)
print(train_set[i][1]) # 查看train-set第七张图元组 的 索引1
# imshow(train_set[i][0])
print(type(train_set[i][1]))
# print(train_set[i].shape)
print(data[0])
print(data[0].shape)
# print(type(data[i]))
"""
train_loader
总结:和Dataset类型不一样,DataLoader不能够直接用索引获取数据。需要用enumerate迭代器来获取 或者 iter.
经过enumerate索引后,得到的data类型是拥有两个变量的列表类型。第一个变量是Tensor类型,用[batchSize,channel,height,width]表示
批图像数据,里面是有batchsize张图的。第二个变量也是Tensor类型,是代表每张图像的标签,是个一维torch
"""
for i,data in enumerate(train_loader):
if i == 7:
print(type(data))
print(len(data))
print(type(data[0]))
print(type(data[1]))
print(data[0].shape)
print(data[1].shape)
print(type(data[1]))
# print(data[0])
print(data[1])
# print(type(data[2]))
# 用GPU训练
import time
torch.cuda.synchronize()
start = time.time()
net = LeNet()
net.to(device) #使用GPU时把网络分配到指定的device中
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(),lr=0.001) # Adam优化器
Loss = []
for epoch in range(5):
# 这里就只训练5个epoch,你可以试试多个
running_loss = 0.0
for step,data in enumerate(train_loader,start=0):
inputs,labels = data # data是一个列表,[数据,标签]
# 清除历史梯度,加快训练
optimizer.zero_grad()
outputs = net(inputs.to(device)) # 将输入的数据分配到指定的GPU中
loss = loss_function(outputs,labels.to(device)) # 将labels分配到指定的device
loss.backward() # loss进行反向传播
optimizer.step() # step进行参数更新
# 打印数据
running_loss += loss.item() # 每次计算完loss后加入到running_loss中
if step % 500 == 499: # 每500个mini-batches 就打印一次
with torch.no_grad():
outputs = net(val_image.to(device))
# outputs的shape = [32,10]
# dim是max函数索引的维度,0是每列最大值,1是每行最大值
predict_y = torch.max(outputs,dim=1)[1] # max函数返回的每个batchSize的最大值 + 索引。获取索引[1]
# == 来比较每个batchSize中的训练结果标签和原标签是否相同,如果预测正确就返回1,否则返回0,并累计正确的数量。
# 得到的是tensor,用item转成数字,CPU时使用
accuracy = (predict_y == val_label.to(device)).sum().item()/val_label.size(0)
# val_label.size是验证集中batchSize的大小
print('[%d %5d] train_loss: %.3f test_accuracy:%.3f' % (epoch+1,step+1,
running_loss/500,accuracy))
Loss.append(running_loss)
running_loss = 0.0
print('Finished Training')
torch.cuda.synchronize()
end = time.time()
print("训练用时:",end-start,'s')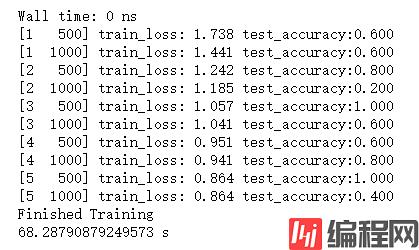
五个epoch在我的GPU上训练了68s。
model.py
import torch.nn as nn
import torch.nn.functional as F
class LeNet(nn.Module):
# 要继承于nn.Moudule父类
def __init__(self):
# 初始化函数
super(LeNet, self).__init__()
# 使用super函数,解决多继承可能遇到的一些问题;调用基类的构造函数
self.conv1 = nn.Conv2d(3, 16, 5) # 调用卷积层 (in_channels,out_channels(也是卷积核个数。输出的通道数),kernel_size(卷积核大小),stride)
self.pool1 = nn.MaxPool2d(2, 2) # 最大池化层,进行下采样
self.conv2 = nn.Conv2d(16, 32, 5) # 输出的通道数为32
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(32*5*5, 120) # 全连接层输入是一维向量,这里是32x5x5,我们要展平,120是节点的个数
# 32是通道数
# Linear(input_features,output_features)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# x是输入数据,是一个tensor
# 正向传播
x = F.relu(self.conv1(x)) # input(3, 32, 32) output(16, 28, 28)
x = self.pool1(x) # output(16, 14, 14)
x = F.relu(self.conv2(x)) # output(32, 10, 10)
x = self.pool2(x) # output(32, 5, 5)
x = x.view(-1, 32*5*5) # output(32*5*5)
# 数据通过view展成一维向量,第一个参数-1是batch,自动推理;32x5x5是展平后的个数
x = F.relu(self.fc1(x)) # output(120)
x = F.relu(self.fc2(x)) # output(84)
x = self.fc3(x) # output(10)
# 为什么没有用softmax函数 --- 在网络模型中已经计算交叉熵以及概率
return x
import torch
input1 = torch.rand([32,3,32,32])
model = LeNet() # 模式实例化
print(model) # 看一下模型结构
output = model(input1)train.py
import torch
import torchvision
import torch.nn as nn
from model import LeNet
import torch.optim as optim
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 50000张训练图片
# 第一次使用时要将download设置为True才会自动去下载数据集
train_set = torchvision.datasets.CIFAR10(root='./data', train=True,
download=False, transform=transform)
train_loader = torch.utils.data.DataLoader(train_set, batch_size=36,
shuffle=True, num_workers=0)
# 把训练集读取,别分成一个一个批次的,shuffle可用于随机打乱;batch_size是一次处理36张图像
# num_worker在windows下只能设置成0
# 10000张验证图片
# 第一次使用时要将download设置为True才会自动去下载数据集
val_set = torchvision.datasets.CIFAR10(root='./data', train=False,
download=False, transform=transform)
val_loader = torch.utils.data.DataLoader(val_set, batch_size=5000,
shuffle=False, num_workers=0)
# 验证集 一次拿出5000张1出来验证,不用打乱
val_data_iter = iter(val_loader) # 转换成可迭代的迭代器
val_image, val_label = val_data_iter.next()
# 转换成迭代器后,用next方法可以得到测试的图像和图像的标签值
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# 这一部分用来看数据集
# def imshow(img):
# img = img / 2 + 0.5 # unnormalize -> 反标准化处理
# npimg = img.numpy()
# plt.imshow(np.transpose(npimg, (1, 2, 0))) #(1,2,0)-> 代表高度、宽度 通道
# plt.show()
#
# # print labels
# print(' '.join('%5s' % classes[val_label[j]] for j in range(4)))
# imshow(torchvision.utils.make_grid(val_image))
net = LeNet()
net.to(device) # 使用GPU时将网络分配到指定的device中,不使用GPU注释
loss_function = nn.CrossEntropyLoss() # 已经包含了softmax函数
optimizer = optim.Adam(net.parameters(), lr=0.001) #Adam优化器
for epoch in range(5): # loop over the dataset multiple times
running_loss = 0.0
for step, data in enumerate(train_loader, start=0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# 一般batch_size根据硬件设备来设置的,这个清楚历史梯度,不让梯度累计,可以让配置低的用户加快训练
# forward + backward + optimize 、、、、、CPU
# outputs = net(inputs)
# loss = loss_function(outputs, labels)
# GPU使用时添加,不使用时注释
outputs = net(inputs.to(device)) # 将inputs分配到指定的device中
loss = loss_function(outputs, labels.to(device)) # 将labels分配到指定的device中
loss.backward() # loss进行反向传播
optimizer.step() # step进行参数更新
# print statistics
running_loss += loss.item() # m每次计算完后就加入到running_loss中
if step % 500 == 499: # print every 500 mini-batches
with torch.no_grad(): # 在测试、预测过程中,这个函数可以优化内存,防止爆内存
# outputs = net(val_image) # [batch, 10]
outputs = net(val_image.to(device)) # 使用GPU时用这行将test_image分配到指定的device中
predict_y = torch.max(outputs, dim=1)[1] #dim=1,因为dim=0是batch;[1]是索引,最大值在哪个位置
# accuracy = torch.eq(predict_y, val_label).sum().item() / val_label.size(0)
# eq用来比较,如果预测正确返回1,错误返回0 -> 得到的是tensor,要用item转成数值 CPU时使用
accuracy = (predict_y==val_label.to(device)).sum().item() / val_label.size(0)
print('[%d, %5d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, step + 1, running_loss / 500, accuracy))
running_loss = 0.0
print('Finished Training')
save_path = './Lenet.pth'
torch.save(net.state_dict(), save_path)
if __name__ == '__main__':
main()Tips:数据集在当前目录下创建一个data文件夹,然后在train_set导入数据那里的download设置为True就可以下载了。如果你没有GPU的话,你可以使用CPU训练,只需要把代码中标记的GPU部分注释,注释掉的CPU部分取消注释就ok了。有条件还是GPU吧,CPU太慢了。
引用:
pytorch官方model
到此这篇关于CNN的Pytorch实现(LeNet)的文章就介绍到这了,更多相关CNN的Pytorch实现内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: CNN的Pytorch实现(LeNet)
本文链接: https://lsjlt.com/news/134459.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0