Python 官方文档:入门教程 => 点击学习
目录一、浏览器模拟(Headers)如何找到浏览器信息打开浏览器,按F12(或者鼠标右键+检查)点击如下图所示的Network按钮按键盘Ctrl+R(Mac:Command+R)进行
浏览器模拟是最常用的一种反爬方式。设想一下:一个网站不停的被同一个版本的浏览器频率的访问,那大概了就要被认为是机器人了。所以上有政策下有对策,我们每次访问都使用不同的浏览器版本信息不就可以了吗。首先我们来看一下如何找到自己浏览器信息。

操作完上一步之后,随便点击右侧name中的一项,即可出现下面的页面,红框中的内容就是我们要找的浏览器信息了。

备注:有一些网站会带有Referer信息,这里的作用主要是在于告诉浏览器你是从哪个网址跳转过来的,类似于P站这种站点就会进行相应的检查,所以我们可以通过上述同样的方式找到浏览器的Referer信息。如下图红框所示:
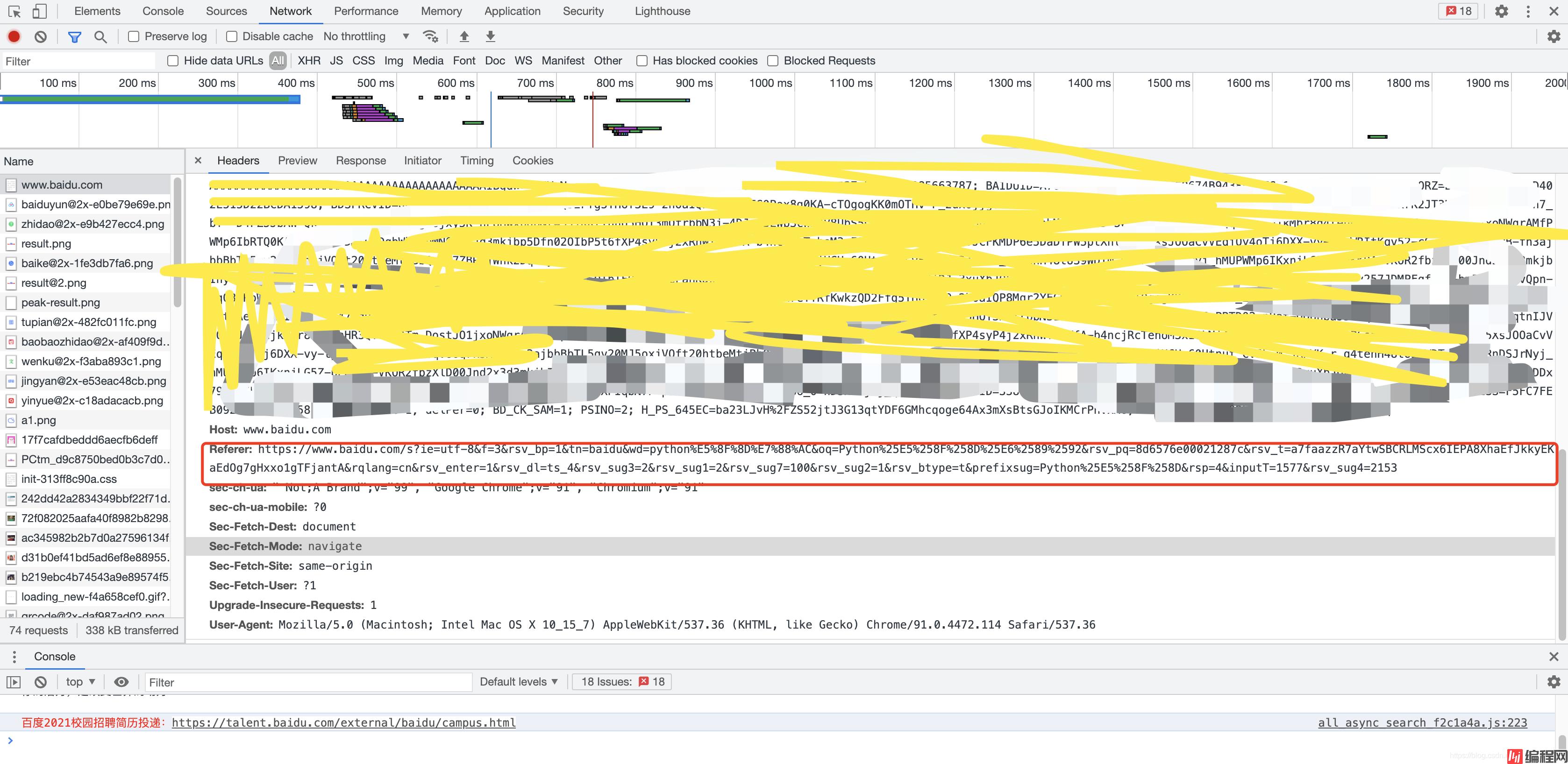
通过上面的步骤,我们就能够成功的得到浏览器的版本信息了,如果能够获得不同的版本信息我们就能够模拟不同的浏览器进行操作了。
headers = {
'Referer': '具体的Referer',
'User-Agent': '具体的user-agent'
}
requests.get(url,headers=headers)
User_Agent = [
"Mozilla/5.0 (iPod; U; CPU iPhone OS 4_3_2 like Mac OS X; zh-cn) AppleWEBKit/533.17.9 (Khtml, like Gecko) Version/5.0.2 Mobile/8H7 Safari/6533.18.5",
"Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_3_2 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8H7 Safari/6533.18.5",
"MQQBrowser/25 (linux; U; 2.3.3; zh-cn; HTC Desire S Build/GRI40;480*800)",
"Mozilla/5.0 (Linux; U; Android 2.3.3; zh-cn; HTC_DesireS_S510e Build/GRI40) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Mozilla/5.0 (SymbianOS/9.3; U; Series60/3.2 NokiaE75-1 /110.48.125 Profile/MIDP-2.1 Configuration/CLDC-1.1 ) AppleWebKit/413 (KHTML, like Gecko) Safari/413",
"Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Mobile/8J2",
"Mozilla/5.0 (windows NT 5.2) AppleWebKit/534.30 (KHTML, like Gecko) Chrome/12.0.742.122 Safari/534.30",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_2) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.202 Safari/535.1",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_2) AppleWebKit/534.51.22 (KHTML, like Gecko) Version/5.1.1 Safari/534.51.22",
"Mozilla/5.0 (iPhone; CPU iPhone OS 5_0 like Mac OS X) AppleWebKit/534.46 (KHTML, like Gecko) Version/5.1 Mobile/9A5313e Safari/7534.48.3",
"Mozilla/5.0 (iPhone; CPU iPhone OS 5_0 like Mac OS X) AppleWebKit/534.46 (KHTML, like Gecko) Version/5.1 Mobile/9A5313e Safari/7534.48.3",
"Mozilla/5.0 (iPhone; CPU iPhone OS 5_0 like Mac OS X) AppleWebKit/534.46 (KHTML, like Gecko) Version/5.1 Mobile/9A5313e Safari/7534.48.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.202 Safari/535.1",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows Phone OS 7.5; Trident/5.0; IEMobile/9.0; SAMSUNG; OMNIA7)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0; XBLWP7; ZuneWP7)",
"Mozilla/5.0 (Windows NT 5.2) AppleWebKit/534.30 (KHTML, like Gecko) Chrome/12.0.742.122 Safari/534.30",
"Mozilla/5.0 (Windows NT 5.1; rv:5.0) Gecko/20100101 Firefox/5.0",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.2; Trident/4.0; .net CLR 1.1.4322; .NET CLR 2.0.50727; .NET4.0E; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729; .NET4.0C)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; .NET4.0E; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729; .NET4.0C)",
"Mozilla/4.0 (compatible; MSIE 60; Windows NT 5.1; SV1; .NET CLR 2.0.50727)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Opera/9.80 (Windows NT 5.1; U; zh-cn) Presto/2.9.168 Version/11.50",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 2.0.50727; .NET CLR 3.0.04506.648; .NET CLR 3.5.21022; .NET4.0E; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729; .NET4.0C)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/533.21.1 (KHTML, like Gecko) Version/5.0.5 Safari/533.21.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; ) AppleWebKit/534.12 (KHTML, like Gecko) Maxthon/3.0 Safari/534.12",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727; TheWorld)",
"Opera/9.80 (X11; Linux i686; ubuntu/14.10) Presto/2.12.388 Version/12.16",
"Opera/9.80 (Windows NT 6.0) Presto/2.12.388 Version/12.14",
"Mozilla/5.0 (Windows NT 6.0; rv:2.0) Gecko/20100101 Firefox/4.0 Opera 12.14",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.0) Opera 12.14",
"Opera/12.80 (Windows NT 5.1; U; en) Presto/2.10.289 Version/12.02",
"Opera/9.80 (Windows NT 6.1; U; es-ES) Presto/2.9.181 Version/12.00",
"Opera/9.80 (Windows NT 5.1; U; zh-sg) Presto/2.9.181 Version/12.00",
"Opera/12.0(Windows NT 5.2;U;en)Presto/22.9.168 Version/12.00",
"Opera/12.0(Windows NT 5.1;U;en)Presto/22.9.168 Version/12.00",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1",
"Mozilla/5.0 (Windows NT 6.3; rv:36.0) Gecko/20100101 Firefox/36.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10; rv:33.0) Gecko/20100101 Firefox/33.0",
"Mozilla/5.0 (X11; Linux i586; rv:31.0) Gecko/20100101 Firefox/31.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:31.0) Gecko/20130401 Firefox/31.0",
"Mozilla/5.0 (Windows NT 5.1; rv:31.0) Gecko/20100101 Firefox/31.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:29.0) Gecko/20120101 Firefox/29.0",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:25.0) Gecko/20100101 Firefox/29.0",
"Mozilla/5.0 (X11; OpenBSD amd64; rv:28.0) Gecko/20100101 Firefox/28.0",
"Mozilla/5.0 (X11; Linux x86_64; rv:28.0) Gecko/20100101 Firefox/28.0",
"Mozilla/5.0 (Windows NT 6.1; rv:27.3) Gecko/20130101 Firefox/27.3",
"Mozilla/5.0 (Windows NT 6.2; Win64; x64; rv:27.0) Gecko/20121011 Firefox/27.0",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:25.0) Gecko/20100101 Firefox/25.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:25.0) Gecko/20100101 Firefox/25.0",
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:24.0) Gecko/20100101 Firefox/24.0",
"Mozilla/5.0 (Windows NT 6.0; WOW64; rv:24.0) Gecko/20100101 Firefox/24.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:24.0) Gecko/20100101 Firefox/24.0"
]除了通过同一个浏览器进行访问,还可能出现的情况就是通过同一个IP不断的访问网址,这样很容易造成整个IP被封,个人的IP还好,如果一个公司的IP都不能访问某个网站,那将会是怎样的效果就不用多说了吧。
对于IP来说除了需要控制IP地址的变更之外,还要控制访问速度,毕竟程序快起来是不眨眼的。
import requests
proxies = {"Http": 'IP地址'}
requests.get(url, headers=headers, proxies=proxies)注:关于代理IP去哪找的问题,网上一搜一大把,我们放心大胆的使用就可以了。
import time
time.sleep(5)有很多时候我们访问网址会遇到403错误,一般这种情况表示无权访问请求的资源,通常在没有设置cookie或是没有设置正确的cookie会导致这个错误。cookie的存在就像是一个网址的通行证,你会发现在你登陆和未登陆网页的时候cookie是会发生变化的。
我们可以通过和获取user-agent一样的方式来手动获取cookie:
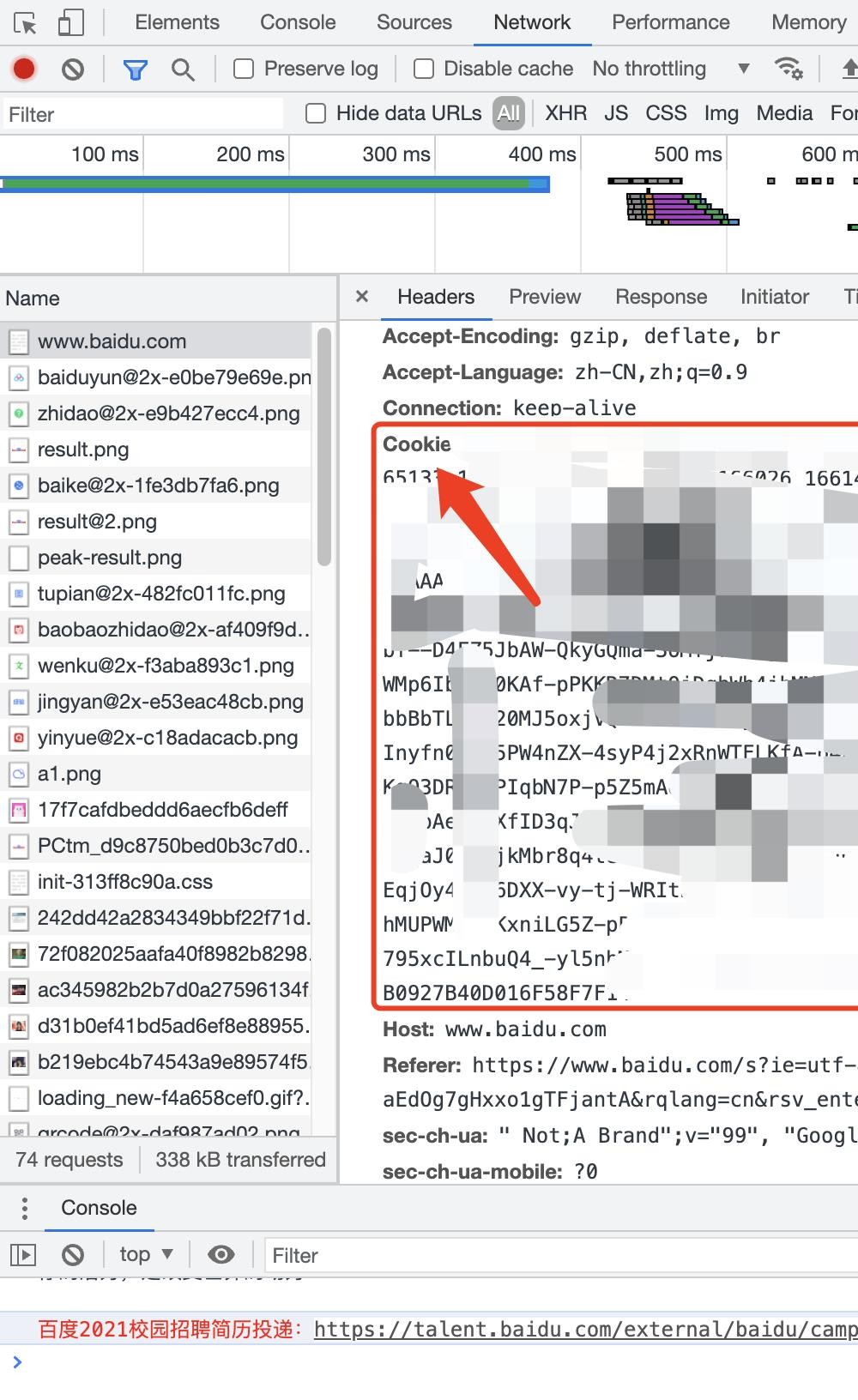
我们使用session方法就能够实现自动获取cookie了
示例代码如下:
import requests
session = requests.session()
session.cookies = LWPCookiejar(filename='Cookies.txt')
def login():
name = input("输入账户:")
passWord = input("输入密码:")
url = "url"
data = {
"ck": "",
"name": name,
"password": password,
"remember": "True",
"ticket": "",
}
response = session.post(url, data=data)
print(response.text)
session.cookies.save() # 保存 cookie这样我们的cookie就能够得以保存了。
使用session加载cookie的方式如下:
session.cookies = LWPCookieJar(filename='Cookies.txt')
session.cookies.load(ignore_discard=True)当我们有了cookies时,使用起来就简单很多了,直接使用和加载user-agent一样的方式即可。
headers = {
'Referer': '具体的Referer',
'User-Agent': '具体的user-agent',
'Cookie': 'cookie'
}
requests.get(url,headers=headers)--结束END--
本文标题: Python爬虫和反爬技术过程详解
本文链接: https://lsjlt.com/news/134279.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0