Python 官方文档:入门教程 => 点击学习
目录1.引言2.获取目标网站3.爬取目标网站4.解析爬取内容4.1. 解析全国今日总况4.2. 解析全国各省份疫情情况4.3. 解析江苏各地级市疫情情况5.结果可视化6. 代码 7.
最近江苏南京、湖南张家界陆续爆发疫情,目前已波及8省22市,全国共有2个高风险地区,52个中风险地区。身在南京,作为兢兢业业的打工人,默默地成为了“苏打绿”。为了关注疫情状况,今天我们用python来爬一爬疫情的实时数据。
为了使用Python来获取疫情数据,我们需要找一个疫情实时追踪数据发布网站,国内比较有名的是腾讯新闻、网易新闻等,这些网站疫情内容都大同小异,主要包括国内疫情、海外疫情,每日新增确诊趋势,疫苗接种情况等,这里我们选用腾讯新闻疫情发布页来进行数据爬取分析。
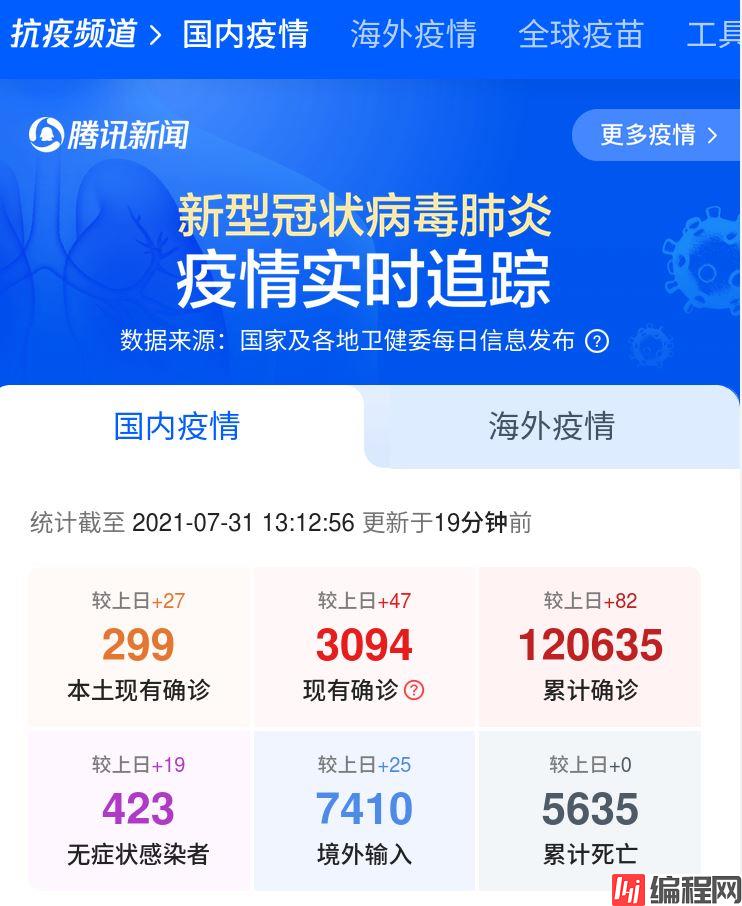
网站分析:
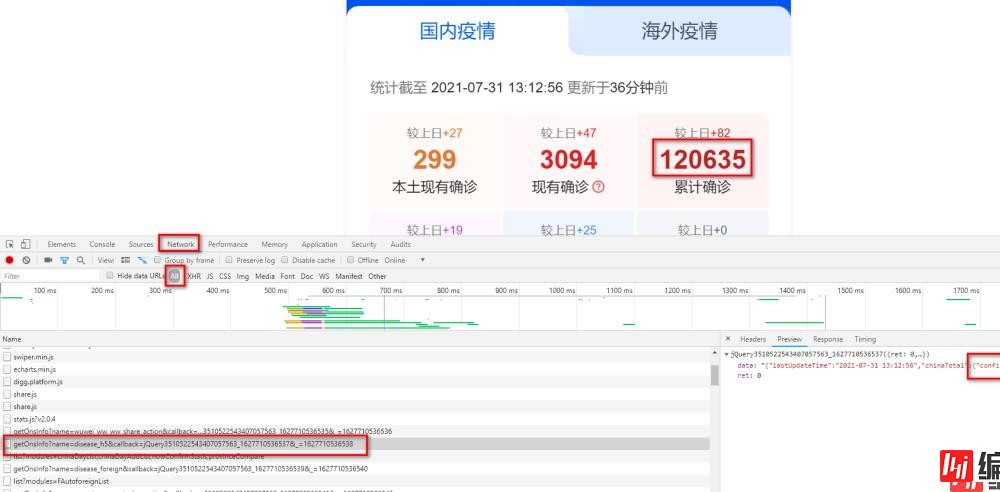
我们写爬虫爬取网站数据,需要安装request库,安装命令如下:
pip3 install requests
只需要三行代码就可以获取该网页内容,代码如下:
url = 'https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5'
req = requests.get(url=url)
content = JSON.loads(req.text)打印爬去结果如下:
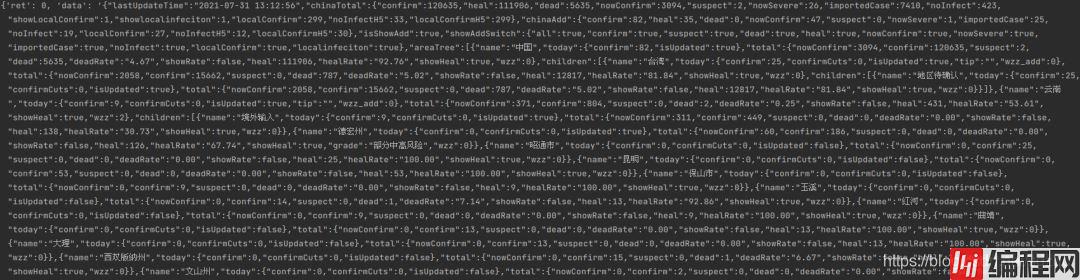
上述网站内容我们虽然爬取成功,接下来我们需要对爬取的结果进行解析,从中找出我们感兴趣的部分。

相应的解析代码如下:
def get_all_china(content):
tmp_data = content["data"]
area_data = json.loads(tmp_data)["areaTree"]
country = area_data[0]
country_list = []
name = country["name"]
today_confirm = country["today"]["confirm"]
now_confirm = country["total"]["nowConfirm"]
total_confirm = country["total"]["confirm"]
total_heal = country["total"]["heal"]
country_list.append([name, today_confirm, now_confirm, total_confirm, total_heal])
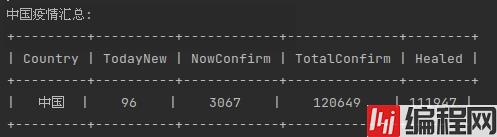
return country_list打印结果如下:

输出太丑了,这里使用PrettyTable库对输出进行美化,代码如下:
def fORMat_list_prettytable(title,province_list):
table = PrettyTable(title)
for province in province_list:
table.add_row(province)
table.border = True
return table结果如下:
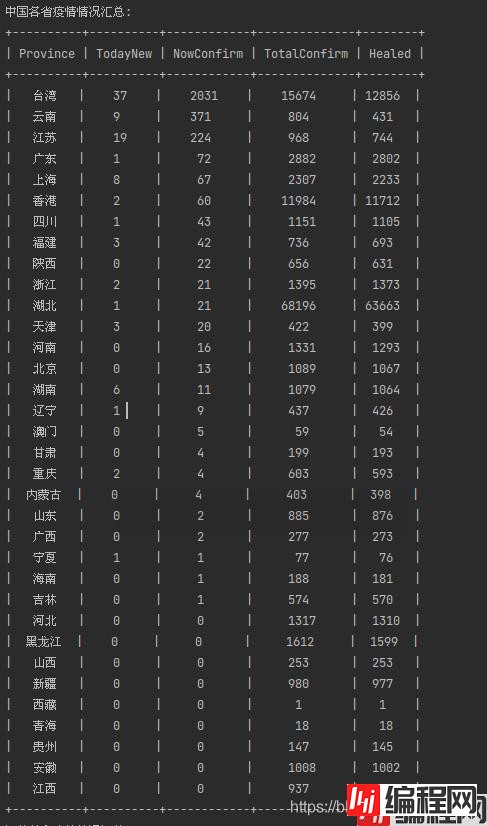
依次类推,可解析全国各省市疫情情况,代码如下:
def get_all_province(content):
tmp_data = content["data"]
area_data = json.loads(tmp_data)["areaTree"]
data = area_data[0]['children']
province_list = []
for province in data:
name = province["name"]
today_confirm = province["today"]["confirm"]
now_confirm = province["total"]["nowConfirm"]
total_confirm = province["total"]["confirm"]
total_heal = province["total"]["heal"]
province_list.append([name, today_confirm, now_confirm, total_confirm, total_heal])
return province_list结果如下:
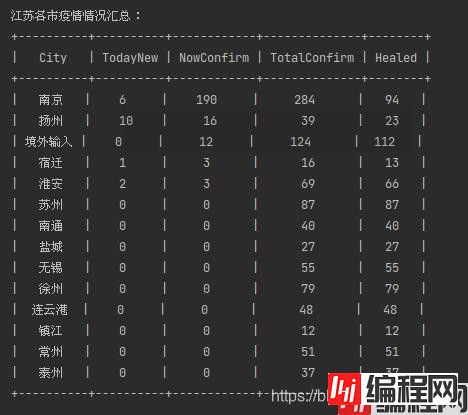
最后,我们获取江苏省各地级市的疫情数据,代码如下:
def parse_jiangsu_province(content,key_province):
tmp_data = content["data"]
area_data = json.loads(tmp_data)["areaTree"]
data = area_data[0]['children']
city_list = []
for province in data:
name = province["name"]
if name == key_province:
children_list = province["children"]
for children in children_list:
city = children["name"]
today_new = children["today"]["confirm"]
now_confirm = children["total"]["nowConfirm"]
total_confirm = children["total"]["confirm"]
total_heal = children["total"]["heal"]
city_list.append([city, today_new, now_confirm, total_confirm, total_heal])
return city_list结果如下:
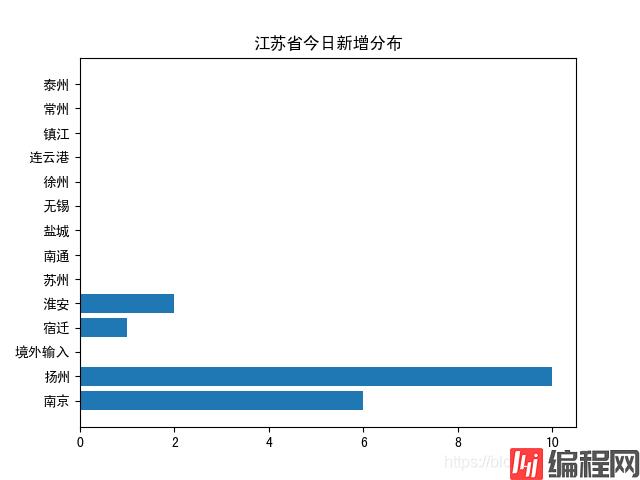
使用matplotlib对上述爬去的江苏各地级市疫情分布可视化,得到结果如下:
今日新增可视化结果如下:
现有确诊可视化结果如下:
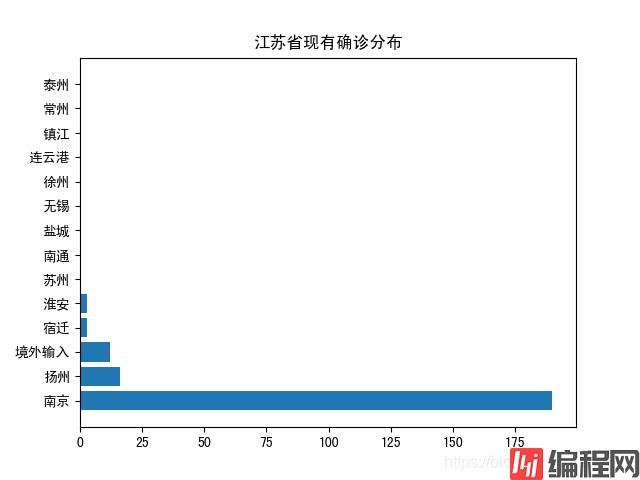
从上述图表可以看出,今日疫情已扩散至扬州,扬州今日新增感染人数最多,需引起重视。
完整代码
Https://GitHub.com/sgzqc/wechat/tree/main/20210731
链接一
到此这篇关于Python获取江苏疫情实时数据及爬虫分析的文章就介绍到这了,更多相关Python江苏疫情内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: Python获取江苏疫情实时数据及爬虫分析
本文链接: https://lsjlt.com/news/131644.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0