Python 官方文档:入门教程 => 点击学习
一.做数据 二.搭建神经网络 三.训练 四.对比测试结果 注意:测试过程中,一定要注意模式切换 PyTorch的学习——过拟合 过拟合 过拟合是当数据量较小时或者输出结
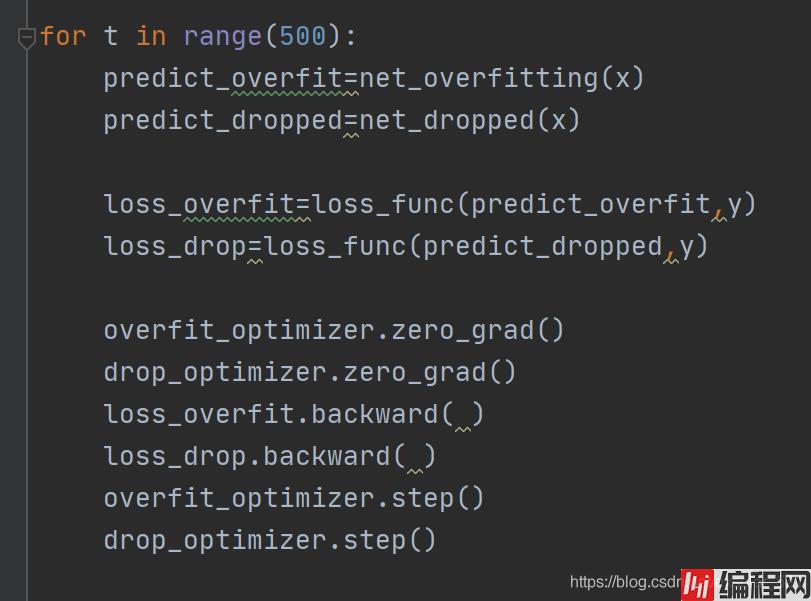
注意:测试过程中,一定要注意模式切换
过拟合是当数据量较小时或者输出结果过于依赖某些特定的神经元,训练神经网络训练会发生一种现象。出现这种现象的神经网络预测的结果并不具有普遍意义,其预测结果极不准确。
1.增加数据量
2.L1,L2,L3…正规化,即在计算误差值的时候加上要学习的参数值,当参数改变过大时,误差也会变大,通过这种惩罚机制来控制过拟合现象
3.dropout正规化,在训练过程中通过随机屏蔽部分神经网络连接,使神经网络不完整,这样就可以使神经网络的预测结果不会过分依赖某些特定的神经元
例子
这里小编通过dropout正规化的列子来更加形象的了解神经网络的过拟合现象
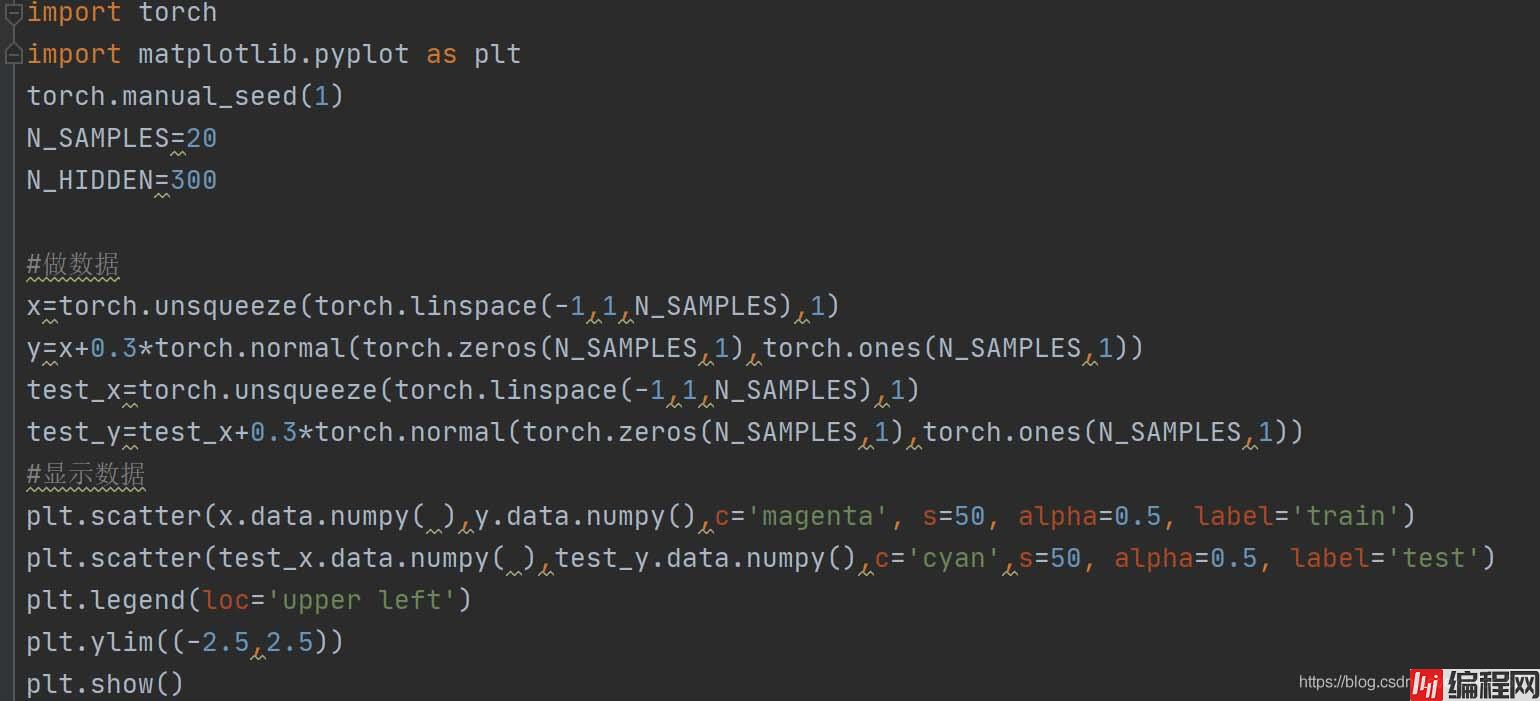
import torch
import matplotlib.pyplot as plt
N_SAMPLES = 20
N_HIDDEN = 300
# train数据
x = torch.unsqueeze(torch.linspace(-1, 1, N_SAMPLES), 1)
y = x + 0.3*torch.nORMal(torch.zeros(N_SAMPLES, 1), torch.ones(N_SAMPLES, 1))
# test数据
test_x = torch.unsqueeze(torch.linspace(-1, 1, N_SAMPLES), 1)
test_y = test_x + 0.3*torch.normal(torch.zeros(N_SAMPLES, 1), torch.ones(N_SAMPLES, 1))
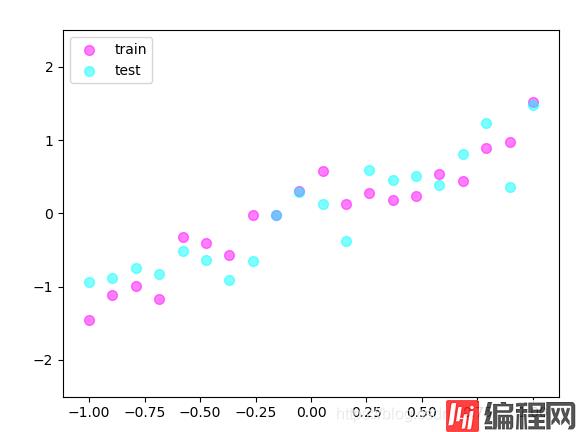
# 可视化
plt.scatter(x.data.numpy(), y.data.numpy(), c='magenta', s=50, alpha=0.5, label='train')
plt.scatter(test_x.data.numpy(), test_y.data.numpy(), c='cyan', s=50, alpha=0.5, label='test')
plt.legend(loc='upper left')
plt.ylim((-2.5, 2.5))
plt.show()
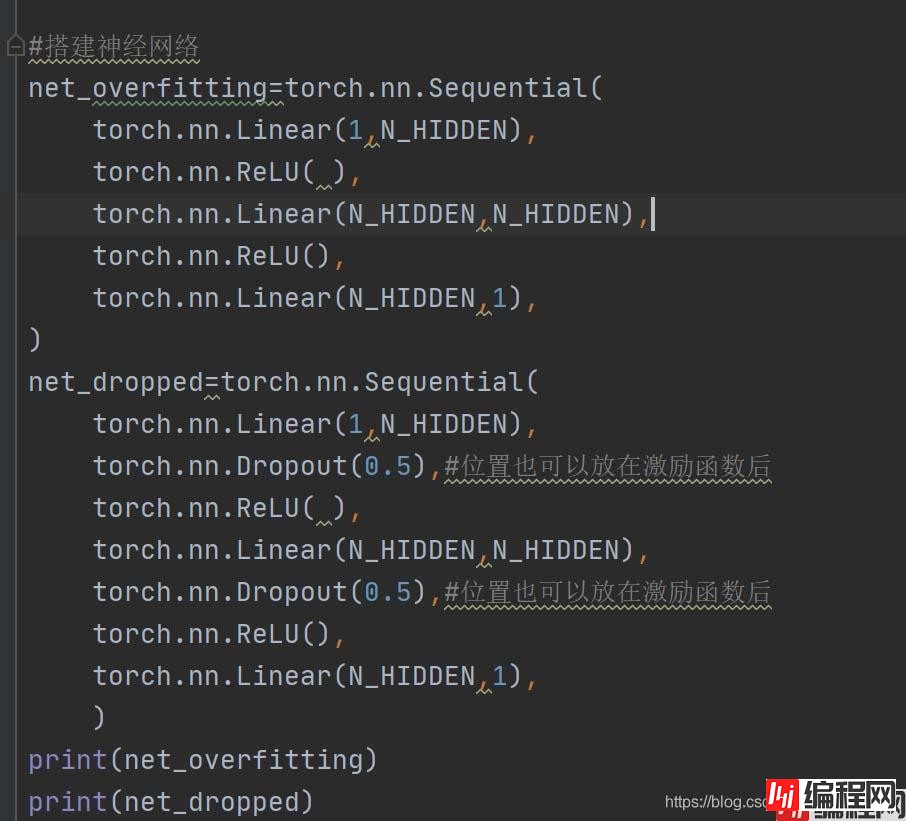
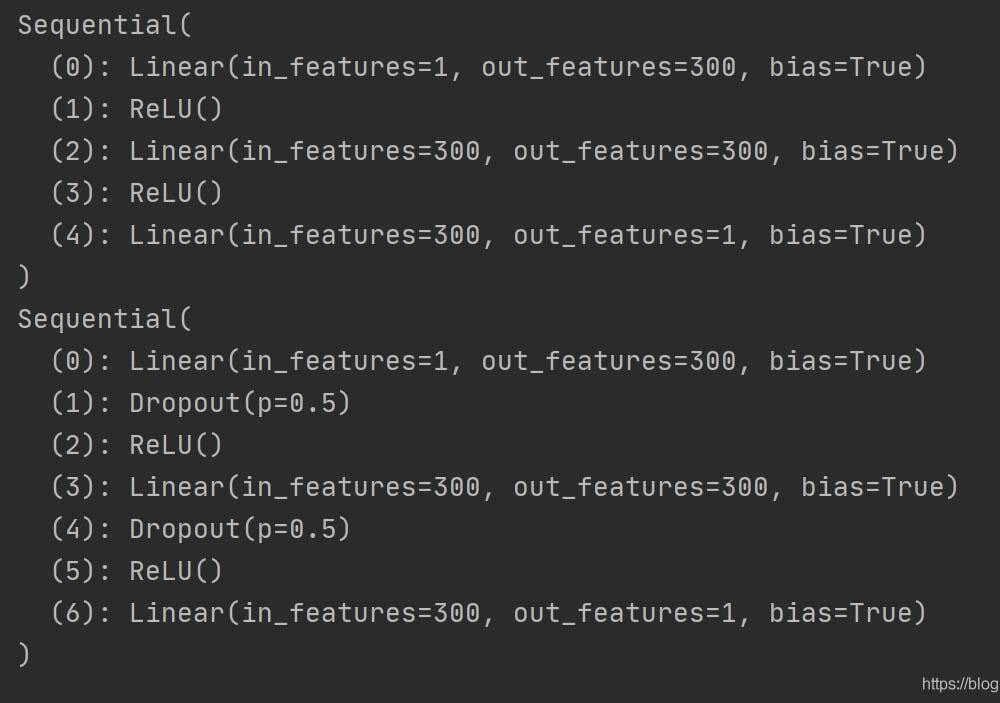
# 网络一,未使用dropout正规化
net_overfitting = torch.nn.Sequential(
torch.nn.Linear(1, N_HIDDEN),
torch.nn.ReLU(),
torch.nn.Linear(N_HIDDEN, N_HIDDEN),
torch.nn.ReLU(),
torch.nn.Linear(N_HIDDEN, 1),
)
# 网络二,使用dropout正规化
net_dropped = torch.nn.Sequential(
torch.nn.Linear(1, N_HIDDEN),
torch.nn.Dropout(0.5), # 随机屏蔽50%的网络连接
torch.nn.ReLU(),
torch.nn.Linear(N_HIDDEN, N_HIDDEN),
torch.nn.Dropout(0.5), # 随机屏蔽50%的网络连接
torch.nn.ReLU(),
torch.nn.Linear(N_HIDDEN, 1),
)
# 选择优化器
optimizer_ofit = torch.optim.Adam(net_overfitting.parameters(), lr=0.01)
optimizer_drop = torch.optim.Adam(net_dropped.parameters(), lr=0.01)
# 选择计算误差的工具
loss_func = torch.nn.MSELoss()
plt.ion()
for t in range(500):
# 神经网络训练数据的固定过程
pred_ofit = net_overfitting(x)
pred_drop = net_dropped(x)
loss_ofit = loss_func(pred_ofit, y)
loss_drop = loss_func(pred_drop, y)
optimizer_ofit.zero_grad()
optimizer_drop.zero_grad()
loss_ofit.backward()
loss_drop.backward()
optimizer_ofit.step()
optimizer_drop.step()
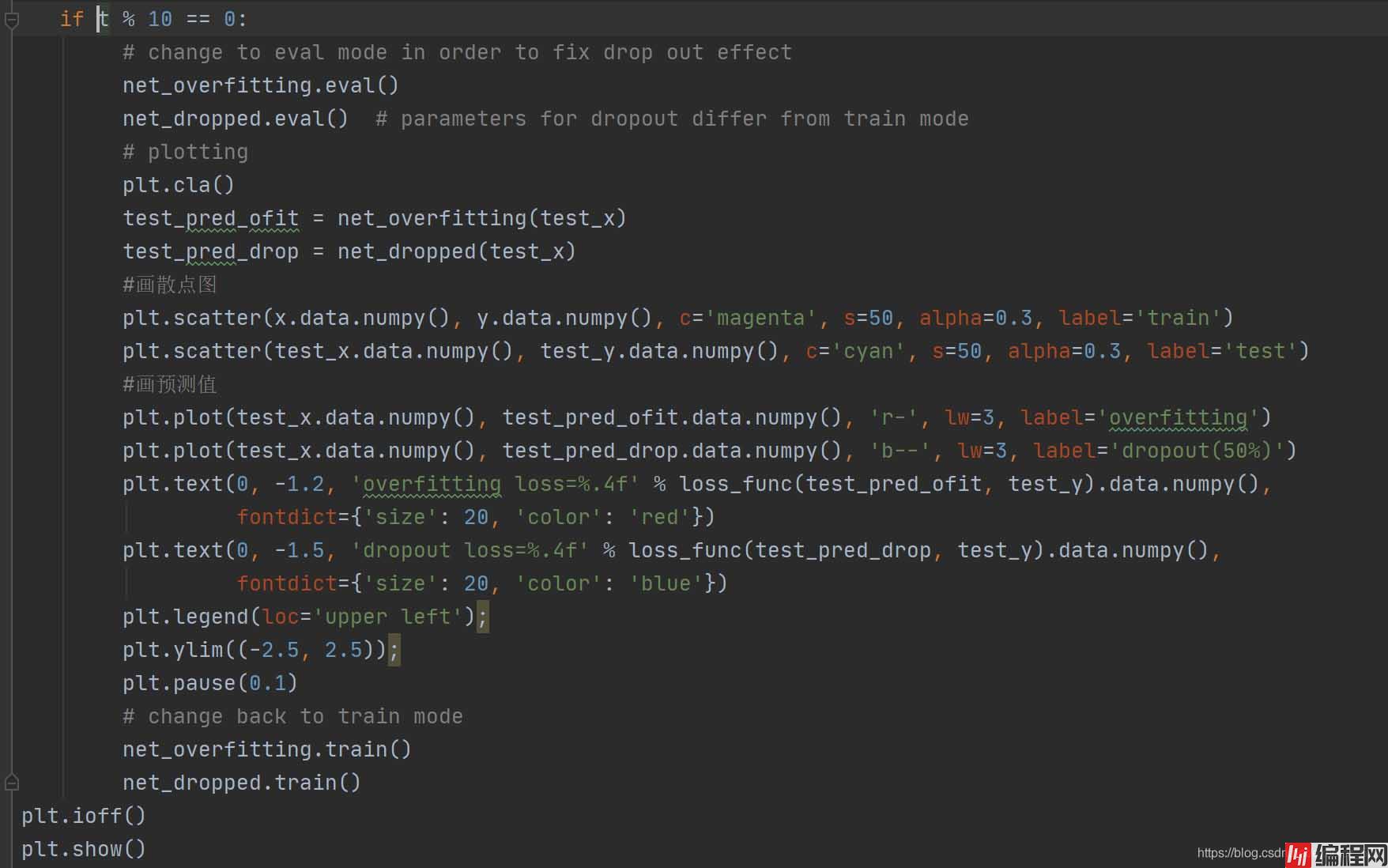
if t % 10 == 0:
# 脱离训练模式,这里便于展示神经网络的变化过程
net_overfitting.eval()
net_dropped.eval()
# 可视化
plt.cla()
test_pred_ofit = net_overfitting(test_x)
test_pred_drop = net_dropped(test_x)
plt.scatter(x.data.numpy(), y.data.numpy(), c='magenta', s=50, alpha=0.3, label='train')
plt.scatter(test_x.data.numpy(), test_y.data.numpy(), c='cyan', s=50, alpha=0.3, label='test')
plt.plot(test_x.data.numpy(), test_pred_ofit.data.numpy(), 'r-', lw=3, label='overfitting')
plt.plot(test_x.data.numpy(), test_pred_drop.data.numpy(), 'b--', lw=3, label='dropout(50%)')
plt.text(0, -1.2, 'overfitting loss=%.4f' % loss_func(test_pred_ofit, test_y).data.numpy(),
fontdict={'size': 20, 'color': 'red'})
plt.text(0, -1.5, 'dropout loss=%.4f' % loss_func(test_pred_drop, test_y).data.numpy(),
fontdict={'size': 20, 'color': 'blue'})
plt.legend(loc='upper left'); plt.ylim((-2.5, 2.5));plt.pause(0.1)
# 重新进入训练模式,并继续上次训练
net_overfitting.train()
net_dropped.train()
plt.ioff()
plt.show()
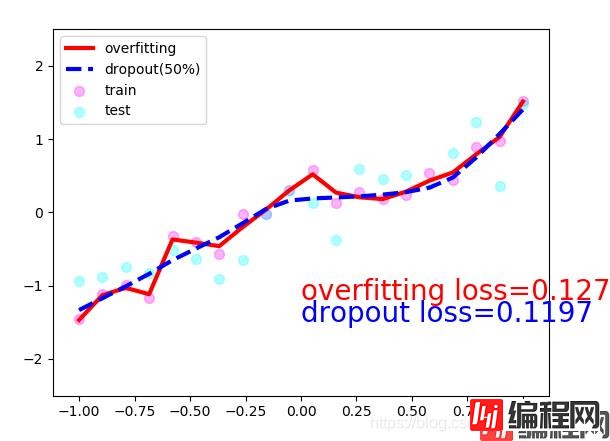
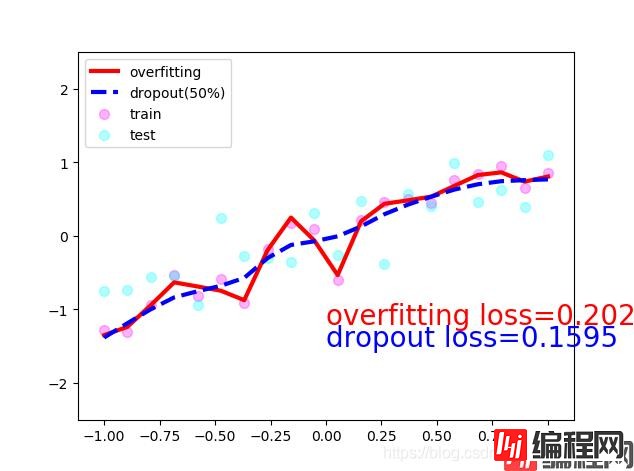
可以看到红色的线虽然更加拟合train数据,但是通过test数据发现它的误差反而比较大
以上为个人经验,希望能给大家一个参考,也希望大家多多支持编程网。
--结束END--
本文标题: Pytorch之如何dropout避免过拟合
本文链接: https://lsjlt.com/news/127481.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0