Python 官方文档:入门教程 => 点击学习
前言 说到二手房信息,不知道你们心里最先跳出来的公司(网站)是什么,反正我心里第一个跳出来的是网站是 58 同城。哎呦,我这暴脾气,想到就赶紧去干。 但很显然,我失败了。说显然,而不
说到二手房信息,不知道你们心里最先跳出来的公司(网站)是什么,反正我心里第一个跳出来的是网站是 58 同城。哎呦,我这暴脾气,想到就赶紧去干。
但很显然,我失败了。说显然,而不是不幸,这是因为 58 同城是大公司,我这点本事爬不了数据是再正常不过的了。下面来看看 58 同城的反爬手段了。这是我爬取下来的网页源码。

我们看到爬取下来的源码有很多英文大写字母和数字是网页源码中没有的,后来我了解到 58 同城对自己的网站的源码进行了文本加密,所以就出现了我爬取到的情况。
我打开 58 同城的 robots 协议。
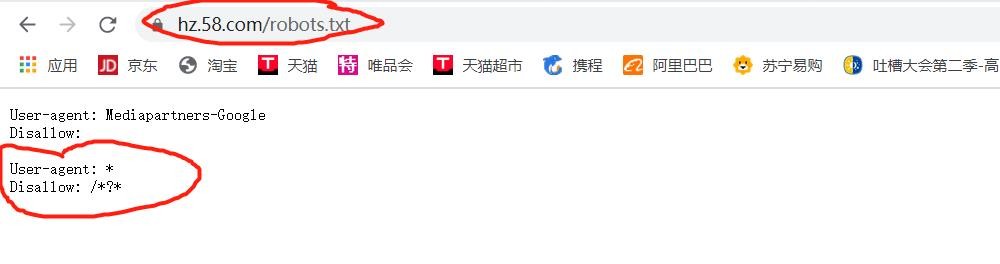
好家伙,不愧是大公司,所有的动态网址都不让爬取,打扰了。我只好转头离开,去寻找可以让我这种小白爬取的二手房网站。于是我找到了c21网站,不知道是我的原因,还是别的原因,反正我是没有找到这个网站的 robots 协议。不管了,既然没找到,就默认没有吧,直接开始爬取。
我本来打算通过二手房的目录跳到一个具体信息,然后爬取二手房的一些基本信息和属性。
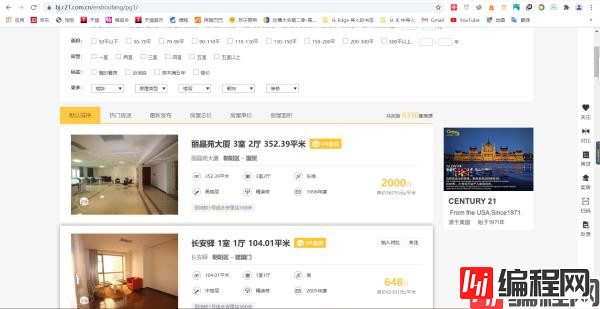
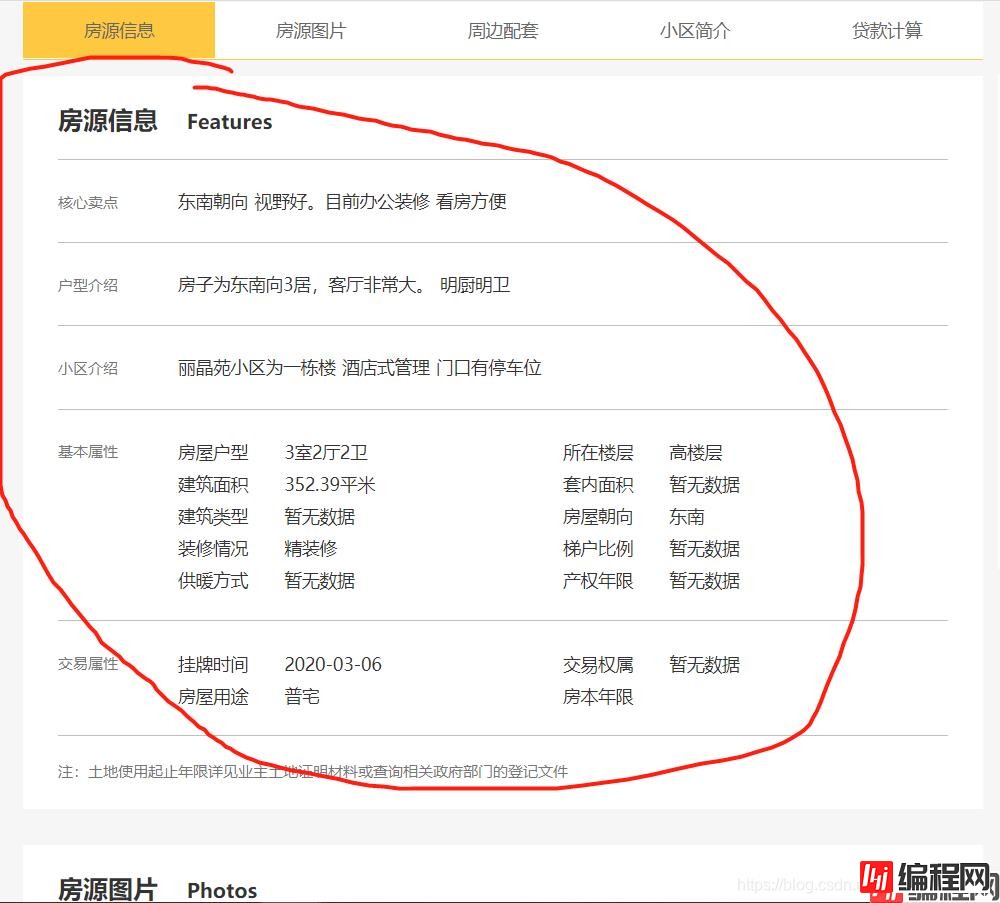
像我红笔圈起来的部分。但很可惜我失败了,后来我看了看红笔圈起来的部分的爬取到的源码。

好家伙,还可以这样。不过这怎么可以难倒机智的我?(其实我真不知道怎么解决它)。没关系,之前的源码里不是有类似的信息吗?我只好将就一下了。
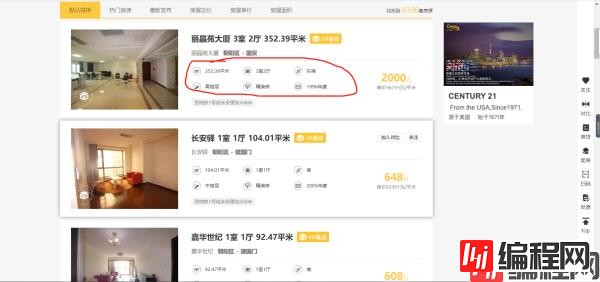
然后是翻页。翻页问题很好解决,我们很快就发现网页都是 https://bj.c21.com.cn/ershoufang/pg2/。其中的页数和 pg 后面的数字有关。
然后就是分析这些数据源码的位置了。
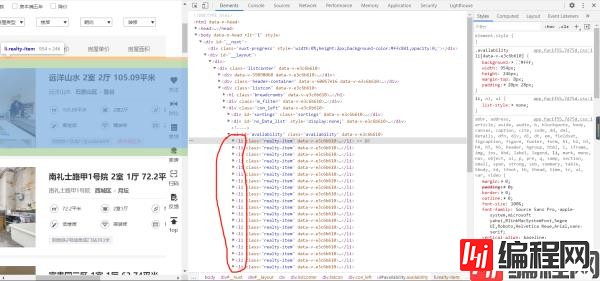
首先,我们发现我们要爬取的数据全在 li 标签里,所以我们可以先获得 li 标签的列表。伪代码就像这样。
这时候我们获得的就是 li 标签的 etree 的类,可以继续使用 etree 类里的函数。然后我们就可以利用 for 循环提出不同房源的 li 标签,根据自己的需要获取文本信息。
欧克,了解了这些(感觉源码前前后后就是四个字 ”我是菜鸡“ )我们就可以开始写代码了。
import requests
from lxml import etree
import re
if __name__ == "__main__":
# UA伪装
header = {
"user-agent": "Mozilla/5.0 (windows NT 10.0; Win64; x64) AppleWEBKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36"
}
for pg in range(1, 3): # 翻两页
# 指定 url
url = "Https://bj.c21.com.cn/ershoufang/pg%s/" % str(pg)
# 获取网页源码
page = requests.get(url = url, headers = header).text
# xpath 解析
tree = etree.HTML(page)
li_list = tree.xpath('//ul[@id="availability"]/li')
for li in li_list:
title = li.xpath('div[2]/div/a/text()')[0] # 房子的名称
# print(title[0]) # 测试
add = li.xpath('div[2]/div/p//a/text()') # 地址
add = add[-2: ] + add[0:1] # 地址范围由大到小
# print(add) # 测试
div_list = li.xpath('div[2]/div[2]/div')
# 具体信息
message_list = ["建筑面积", "房屋户型", "房屋朝向", "所在楼层", "装修情况", "建成时间"]
for i in range(6):
div = div_list[i]
message = div.xpath('span/text()')[0]
message = re.sub("\s", "", str(message)) # 因为发现获取的文本有很多换行符和空格,所以需要去掉
message = re.sub("\\n", "", str(message))
message_list[i] = message_list[i] + ":" + message
# print(message_list) # 测试
# 交通情况
traffic = li.xpath('div[2]/div[4]//text()')
# print(traffic) # 测试
# 价格情况
price = li.xpath('div[2]/div[3]//text()')
price = price[0] + price[1]
# print(price) # 测试
with open("C:\\Users\\ASUS\\Desktop\\CSDN\\数据解析\\xpath\\二手房\\" + "二手房.txt", "a", encoding = "utf-8") as fp:
fp.write(title + "\n")
for message in message_list:
fp.write(message + "\n")
if traffic == []:
fp.write("交通情况:无介绍" + "\n")
else:
fp.write("交通情况:" + traffic[0] + "\n")
fp.write("价格:" + price + "\n\n")
print(title, "下载完成!!!")
print("over!!!")
最后的运行结果就像这样

到此这篇关于python爬虫之爬取二手房信息的文章就介绍到这了,更多相关python爬取二手房信息内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: Python爬虫之爬取二手房信息
本文链接: https://lsjlt.com/news/124747.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0