Python 官方文档:入门教程 => 点击学习
windows下spark的安装和运行 建议看到这篇文章(描述非常详细) Spark在Win10下的环境搭建 一、创建项目和.py文件 二、在PyCharm中添加spark环境
windows下spark的安装和运行 建议看到这篇文章(描述非常详细)
Spark在Win10下的环境搭建


若是左侧的python中没有,可点击‘'+‘'号进行添加

配置spark环境:总共3个(SPARK_HOME、hadoop_HOME、PythonPATH)
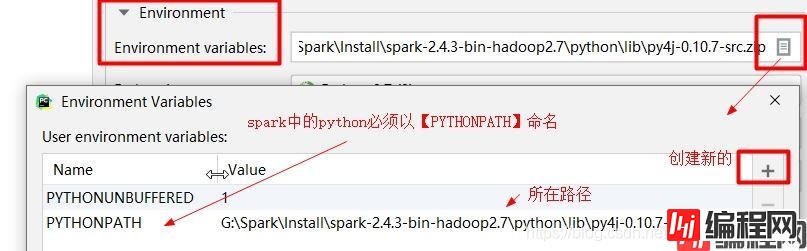


(注:SPARK_HOME和HADOOP_HOME已在系统的环境变量添加,故这里不再添加)
在编写代码时,建议添加如下代码,保证程序能够运行成功:
import os
import sys
import findspark # 一定要在最前面导入
'''初始化spark环境'''
findspark.init()
# Path for spark source folder
os.environ['SPARK_HOME'] = "G:\Spark\Install\spark-2.4.3-bin-hadoop2.7"
# Append pyspark to Python Path
sys.path.append("G:\Spark\Install\spark-2.4.3-bin-hadoop2.7\python")
'''示例'''
from pyspark import SparkContext,SparkConf
from pyspark.sql import SparkSession
from pyspark.sql import Row
# SparkContext是spark功能的主要入口
sc = SparkContext("local", "app")
RawSalesDataRDD = sc.textFile("G:\\Spark\\作业\\taxi.csv")
print(RawSalesDataRDD.take(5))
salesRDD = RawSalesDataRDD.map(lambda line: line.split(","))
print(salesRDD.take(5))
taxi_Rows = salesRDD.map(lambda p:
Row(
id=p[0],
lat=p[1],
lon=p[2],
time=p[3]
))
sqlContext = SparkSession.builder.getOrCreate()
taxi_df = sqlContext.createDataFrame(taxi_Rows)
print(taxi_Rows.take(5))
print('查看dataframe的字段名称和前5行数据:')
taxi_df.printSchema()
taxi_df.show(5)
'''使用SQL语句 操作表数据'''
# #创建临时表taxi_table
taxi_df.reGISterTempTable("taxi_table")
# 查询编号为 5 的出租车的 GPS 数据的前 10 行
taxi_df.filter("id='5'").show(10)
taxi_df.where("id='5'").show(10)
sqlContext.sql("select * from taxi_table where id='5'").show(10)代码运行结果:


到此这篇关于windows下pycharm搭建spark环境并成功运行 附源码的文章就介绍到这了,更多相关pycharm搭建spark环境内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: windows下pycharm搭建spark环境并成功运行 附源码
本文链接: https://lsjlt.com/news/124706.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0