已解决 用grep函数 A=read.table("clipboard",sep="/t",header=T) A[grep(pattern="/resource/activit
用grep函数
A=read.table("clipboard",sep="/t",header=T)
A[grep(pattern="/resource/activity",A[,1]),]补充:R语言 如何截取字符串特定字符前或后的字符串
topic = “#全国累计报告72436例新冠肺炎#/#全国累计报告72436例新冠肺炎#.csv”
需要截取出:“全国累计报告72436例新冠肺炎”
借用R语言的字符串操作:strsplit(),把字符串分割开
topics = strsplit(topic, "/", fixed= T) #用/把字符串分开,fixed为是否使用正则表达式 ```
分割处理后的topics结构:

提取出前半句,然后消去"#"符号:
topic = topics[[1]][1]topic = gsub("#","",topic)
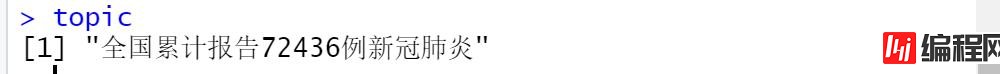
gsub()替换掉字符串中所有查找到的指定字符
sub()函数形参位置与gsub()相似,功能上只替换第一个字符
以上为个人经验,希望能给大家一个参考,也希望大家多多支持编程网。如有错误或未考虑完全的地方,望不吝赐教。
--结束END--
本文标题: R语言-实现提取包含某字符串的行变量
本文链接: https://lsjlt.com/news/124163.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0