Python 官方文档:入门教程 => 点击学习
一般创建了scrapy文件夹后,可能需要写多个爬虫,如果想让它们同时运行而不是顺次运行的话,得怎么做? a、在spiders目录的同级目录下创建一个commands目录,并在该目录
一般创建了scrapy文件夹后,可能需要写多个爬虫,如果想让它们同时运行而不是顺次运行的话,得怎么做?
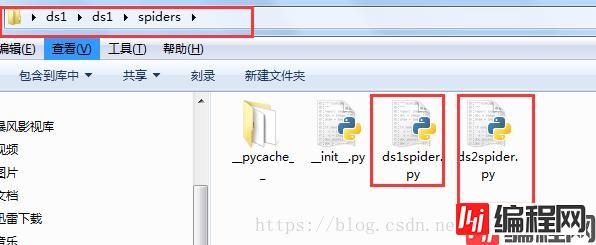
a、在spiders目录的同级目录下创建一个commands目录,并在该目录中创建一个crawlall.py,将scrapy源代码里的commands文件夹里的crawl.py源码复制过来,只修改run()方法即可!
import os
from scrapy.commands import ScrapyCommand
from scrapy.utils.conf import arglist_to_dict
from scrapy.utils.python import without_none_values
from scrapy.exceptions import UsageError
class Command(ScrapyCommand):
requires_project = True
def syntax(self):
return "[options] <spider>"
def short_desc(self):
return "Run all spider"
def add_options(self, parser):
ScrapyCommand.add_options(self, parser)
parser.add_option("-a", dest="spargs", action="append", default=[], metavar="NAME=VALUE",
help="set spider argument (may be repeated)")
parser.add_option("-o", "--output", metavar="FILE",
help="dump scraped items into FILE (use - for stdout)")
parser.add_option("-t", "--output-fORMat", metavar="FORMAT",
help="format to use for dumping items with -o")
def process_options(self, args, opts):
ScrapyCommand.process_options(self, args, opts)
try:
opts.spargs = arglist_to_dict(opts.spargs)
except ValueError:
raise UsageError("Invalid -a value, use -a NAME=VALUE", print_help=False)
if opts.output:
if opts.output == '-':
self.settings.set('FEED_URI', 'stdout:', priority='cmdline')
else:
self.settings.set('FEED_URI', opts.output, priority='cmdline')
feed_exporters = without_none_values(
self.settings.getwitHBase('FEED_EXPORTERS'))
valid_output_formats = feed_exporters.keys()
if not opts.output_format:
opts.output_format = os.path.splitext(opts.output)[1].replace(".", "")
if opts.output_format not in valid_output_formats:
raise UsageError("Unrecognized output format '%s', set one"
" using the '-t' switch or as a file extension"
" from the supported list %s" % (opts.output_format,
tuple(valid_output_formats)))
self.settings.set('FEED_FORMAT', opts.output_format, priority='cmdline')
def run(self, args, opts):
#获取爬虫列表
spd_loader_list=self.crawler_process.spider_loader.list()#获取所有的爬虫文件。
print(spd_loader_list)
#遍历各爬虫
for spname in spd_loader_list or args:
self.crawler_process.crawl(spname, **opts.spargs)
print ('此时启动的爬虫为:'+spname)
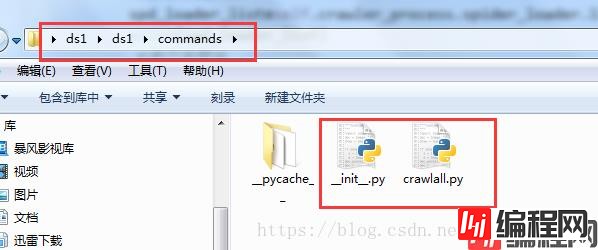
self.crawler_process.start()b、还得在里面加个_init_.py文件
c、到这里还没完,settings.py配置文件还需要加一条。
COMMANDS_MODULE = ‘项目名称.目录名称'
COMMANDS_MODULE = 'ds1.commands'd、最后启动crawlall即可!
当然,安全起见,可以先在命令行中进入该项目所在目录,并输入scrapy -h,可以查看是否有命令crawlall 。如果有,那就成功了,可以启动了
我是写了个启动文件,放在第一级即可
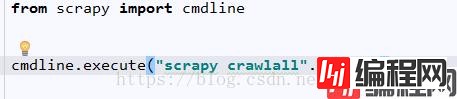
要不直接在命令台cmd里输入 scrapy crawlall 就行了
##注意的是,爬虫好像是2个同时运行,而且运行时是交叉的?
还有settings里的文件,只针对其中一个?
到此这篇关于Python scrapy项目下spiders内多个爬虫同时运行的文章就介绍到这了,更多相关python scrapy项目下spiders内多个爬虫同时运行内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: python scrapy项目下spiders内多个爬虫同时运行的实现
本文链接: https://lsjlt.com/news/124118.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0