Python 官方文档:入门教程 => 点击学习
目录一、简单文本类型数据二、复杂型表格提取三、图片型表格提取大家好,从pdf中提取信息是办公场景中经常需要用到的操作,也是经常又读者在后台问的一个操作。 内容少的话我们可以手动复制粘
大家好,从pdf中提取信息是办公场景中经常需要用到的操作,也是经常又读者在后台问的一个操作。
内容少的话我们可以手动复制粘贴,但如果需要批量提取就可以考虑使用python,之前我也转载过相关文章,提到主要就是使用pdfplumber库,今天我们再次举例讲解。
通常PDF里的表格分为图片型和文本型。文本型又分简单型和复杂型。本文就针对这三部分举例讲解。

用到的模块主要有
文中出现的PDF材料是在巨潮资讯官网下载的公开PDF文件,主题是关于理财的,相关发布信息等信息如下:

内容总共有6页,后文中的例子会有展示。
简单文本类型表格就是一页PDF中只有一个表格,并且表格内容完整可复制,例如我们选定内容为PDF中的第四页,内容如下:

可以看到,该页只有一个表格,下面我们将这个表写入excel中,先上代码
import pdfplumber as pr
import pandas as pd
pdf = pr.open('关于使用自有资金购买银行理财产品的进展公告.PDF')
ps = pdf.pages
pg = ps[3]
tables = pg.extract_tables()
table = tables[0]
print(table)
df = pd.DataFrame(table[1:],columns = table[0])
for i in range(len(table)):
for j in range(len(table[i])):
table[i][j] = table[i][j].replace('\n','')
df1 = pd.DataFrame(table[1:],columns = table[0])
df1.to_excel('page2.xlsx')得到的结果如下:

通过与PDF上原表格对比,在内容上是完全一致的,唯一不同的是由于主营业务内容较多,导致显示的不全面,现在来说说这段代码。
首先导入要用到的两个库。在pdfplumber中,open()函数是用来打开PDF文件,该代码用的是相对路径。.open().pages则是获取PDF的页数,打印ps值可以得到如下

pg = ps[3]代表的就是我们所选的第三页。
pg.extract_tables():可输出页面中所有表格,并返回一个嵌套列表,其结构层次为table→row→cell。此时,页面上的整个表格被放入一个大列表中,原表格中的各行组成该大列表中的各个子列表。若需输出单个外层列表元素,得到的便是由原表格同一行元素构成的列表。
与其类似的是pg.extract_table( ):返回多个独立列表,其结构层次为row→cell。若页面中存在多个行数相同的表格,则默认输出顶部表格;否则,仅输出行数最多的一个表格。此时,表格的每一行都作为一个单独的列表,列表中每个元素即为原表格的各个单元格内容。
由于该页面中只有一个表格,我们需要tables集合中的第一个元素。打印table值,如下:

可以看到在上述中是存在\n这种没不要的字符,它的作用其实是换行但我们在Excel中是不需要的。所以需要剔除它,用代码中的for循环与replace函数将控制替换成空格(即删除\n)。观察table是一个装有2个元素的列表。
最后df1 = pd.DataFrame(table[1:],columns = table[0])这段代码的作用就是创建一个数据框,将内容放到对应的行列中。
本代码只是简单将数据存入到Excel,如果你需要进一步对样式进行调整,可以使用openpyxl等模块进行修改。
复杂型表格即表格样式不统一或一页中有多个表格,以PDF中的第五页为例:

可以看到本页中有两个大的表格,并且细看的话,其实是4个表格,按照简单型表格类型提取方法,得到的效果如下:
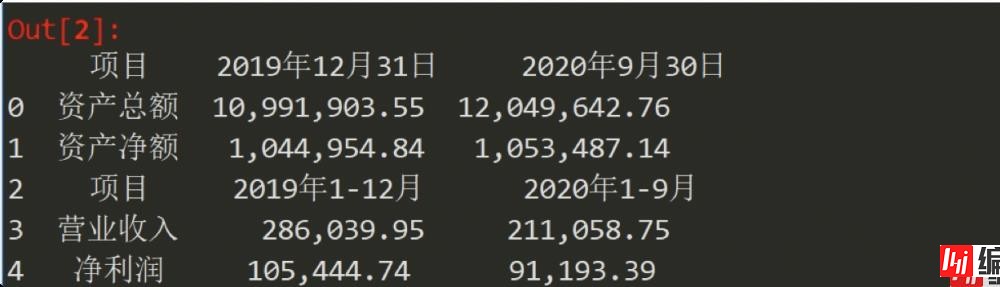
可以看到,只是将全部表格文本提取出来,但实际上第一个表格又细分为两个表,所以需要我们进一步修改,将这张表再次拆分!例如提取上半部分代码如下:
import pdfplumber as pr
import pandas as pd
pdf = pr.open('关于使用自有资金购买银行理财产品的进展公告.PDF')
ps = pdf.pages
pg = ps[4]
tables = pg.extract_tables()
table = tables[0]
print(table)
df = pd.DataFrame(table[1:],columns = table[0])
for i in range(len(table)):
for j in range(len(table[i])):
table[i][j] = table[i][j].replace('\n','')
df1 = pd.DataFrame(table[1:],columns = table[0])
df2 = df1.iloc[2:,:]
df2 = df2.rename(columns = {"2019年12月31日":"2019年1-12月","2020年9月30日":"2020年1-9月"})
df2 = df2.loc[3:,:]
df1 = df1.loc[:1,:]
with pd.ExcelWriter('公司影响.xlsx') as i:
df1.to_excel(i,sheet_name='资产', index=False, header=True) #放入资产数据
df2.to_excel(i,sheet_name='营业',index=False, header=True) #放入营业数据这段代码在简单型表格提取的基础上进行了修改,第十四行代码的作用就是提取另外一个表头的信息,并将他赋值给df2,而后对df2进行重命名操作(用到rename函数)。
打印df2可以看出columns列名和第一行信息重复了,因此我们需要重复刚刚的步骤,利用loc()函数切割数据框。
注意,我们这里用了罕见的pandas.Excelwriter函数套for循环,这个是为了避免直接写入导致的最后数据覆盖原数据,感兴趣可以尝试一下不用withopen这种方法后结果。最终得到的效果如下:


可以看到,现在这个表格就被放在两个sheet中单独展示,当然用于对比放在一张表中也是可以的

说到底复杂型表格的主观性是非常大的,需要根据不同情况进行不同处理,想写出一个一劳永逸的办法是比较困难的!
最后也是最难处理的就是图片型表格,经常有人会问如何提取图片型PDF中的表格/文本等信息。
其实本质上就是提取图片,之后如何对图片进一步处理提取信息就与Python提取PDF表格这个主题没有太大关系了!
这里我们也简单进行介绍,也就是先提取图片再进行OCR识别提取表格,在Python中可以使用Tesseract库,首先需要pip安装
pip install pytesseract在Python中安装完这个库之后我们需要安装exe文件以在后面代码用到。
Http://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-setup-4.00.00dev.exe下载安装完即可,注意目前如果按照正常步骤安装的话是不会识别中文的,所以需要安装简体中文语言包,下载地址为https://GitHub.com/tesseract-ocr/tessdata/find/master/chi_sim.traineddata,将其放到Tesseract-OCR的tessdata目录下即可。
接下来我们使用一个简单的图片型pdf如下:
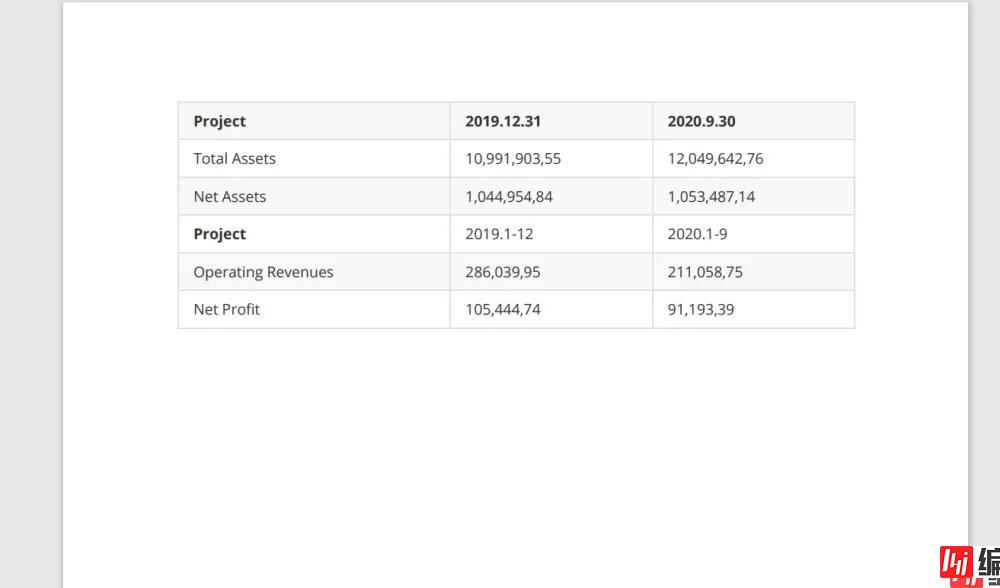
第一步,提取图片,这里使用在GUI办公自动化系列中的图片提取软件来提取PDF中的图片,得到如下图片:

接着执行下方代码识别图片内容
import pytesseract
from PIL import Image
import pandas as pd
pytesseract.pytesseract.tesseract_cmd = 'C://Program Files (x86)/Tesseract-OCR/tesseract.exe'
tiqu = pytesseract.image_to_string(Image.open('图片型.jpg'))
print(tiqu)
tiqu = tiqu.split('\n')
while '' in tiqu: #不能使用for
tiqu.remove('')
first = tiqu[:6]
second = tiqu[6:12]
third = tiqu[12:]
df = pd.DataFrame()
df[first[0]] = first[1:]
df[second[0]] = second[1:]
df[third[0]] = third[1:]
#df.to_excel('图片型表格.xlsx') #转为xlsx文件我们的思路是用Tesseract-OCR来解析图片,得到一个字符串,接着对字符串运用split函数,把字符串变成列表同时删除\n。
接着可以发现我们的列表里还存在空格,这时我们用while循环来删除这些空字符,注意,这里不能用for循环,因为每次删除一个,列表里的元素就会前进一个,这样会删不完全。最后就是用pandas把这些变成数据框形式。最终得到的效果如下:

可以看到,该图片型表格内容被完美解析与处理!当然能轻松搞定的原因也与这个表格足够简单有关,在真实场景中的图片可能会有更复杂的干扰因素,而这就需要大家在处理的同时自行找到一个最合适的办法!
以上就是用Python提取PDF表格的方法的详细内容,更多关于Python提取PDF表格的资料请关注编程网其它相关文章!
--结束END--
本文标题: 用Python提取PDF表格的方法
本文链接: https://lsjlt.com/news/123286.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0