因为项目的原因采用了Redis Cluster,3主3从,每台主机1主1从,集群信息如下: 10.135.255.72:20011> cluster nodes 7b662b
因为项目的原因采用了Redis Cluster,3主3从,每台主机1主1从,集群信息如下:
10.135.255.72:20011> cluster nodes
7b662b36489a6240aa21d1cf7b04b84019254b63 10.135.255.74:20012 slave 85c78164a448fb9965e22447429a56cab226c68f 0 1537239581900 43 connected
61c3e1a640e71f4801d850c901dd33f0b4f6876d 10.135.255.73:20012 slave 8e3491125e105333958dd752ee0d0b0a41ed2d90 0 1537239582300 41 connected
85c78164a448fb9965e22447429a56cab226c68f 10.135.255.73:20011 master - 0 1537239581999 43 connected 5461-10922
8e3491125e105333958dd752ee0d0b0a41ed2d90 10.135.255.72:20011 myself,master - 0 0 41 connected 0-5460
92eadfb6acbd0db74a8b8860286a7f63abce140e 10.135.255.74:20011 master - 0 1537239581799 44 connected 10923-16383
7084c1d7950b83abc1e4419500e1c24a9fa108e7 10.135.255.72:20012 slave 92eadfb6acbd0db74a8b8860286a7f63abce140e 0 1537239581499 44 connected
Redis Cluster经过运行一段时间后,会经常发生主从关系的自动切换,比如:10.135.255.74:20012变成master,10.135.255.73:20011变成slave,这样就会导致10.135.255.74:20011和10.135.255.74:20012变成双master,这样假如10.135.255.74这台主机发生宕机,就会导致2个master不可用,导致cluster down(ps:redis cluster中一半以上的master故障会导致 cluster down)。此问题困扰项目组很久,一直未找到根本原因。
后来经过多次查阅资料,应该是redis.conf里的集群节点的超时时限参数cluster-node-timeout配置的是2000(2秒),这里简单讲解下该参数的作用:
1.集群中当一个节点向另一个节点发送PING命令,但是目标节点未在给定的时限内返回PING命令的回复时,那么发送命令的节点会将目标节点标记为PFaiL(possible failuer,可能已失效);
等待节点回复的时限称为节点超时时限(node timeout),是一个节点选项(node-wise setting);
每当集群发生配置变化时(可能是哈希槽更新,也可能是某个节点进入失效状态),集群中的每个节点都会对它所知道的节点进行扫描(scan);
一旦配置完毕,集群就会进入两种状态中的一种:
FAIL:集群不能正常工作,当集群中有某个节点进入失效状态时,集群不能处理任何命令请求,对于每个命令请求,集群节点都返回错误回复;
OK:集群可以正常工作,负责处理全部16384个槽节点中,没有一个被标记为FAIL状态;
一旦某个主节点进入了FAIL状态,如果这个主节点有一个或者多个从节点存在,那么其中一个从节点会被升级为主节点,而其它从节点会开始对这个新主节点进行复制;
在实际生产使用过程中,由于网络顺时延迟或者Cluster某些节点正在进行持久化,AOF重写、Master-slave同步数据这些耗时的操作,可能就会产生节点检测超时(>2000ms)从而失效,为了避免节点检测过于灵敏,经过多次调整实践,在该项目的实际生产环境中,将cluster-node-timeout调整为12000ms后,比较稳定,既不轻易发生主从自动切换,也在真正master节点主机宕机后,slave能迅速选举为主,保证redis cluster可用。
补充:记一次Redis主从切换故障解决
在虚拟机机上配置了一主二从三哨兵,主机宕机后其中一台从机自动切换为主机成功。重启之前的主机却连不上新的主机。
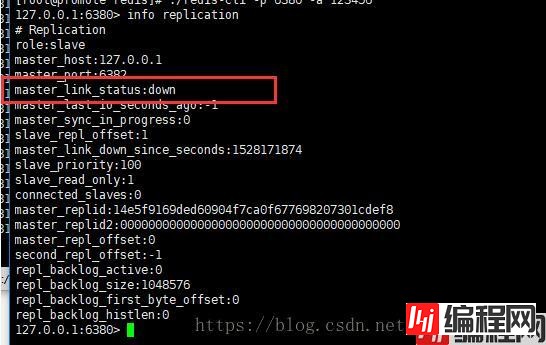
经过检查发现,旧的主机未配置连接新的从机的密码
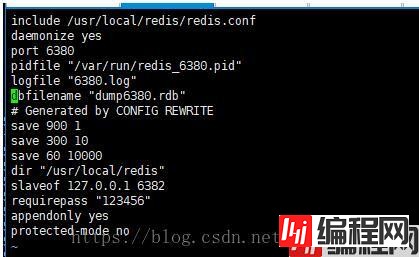
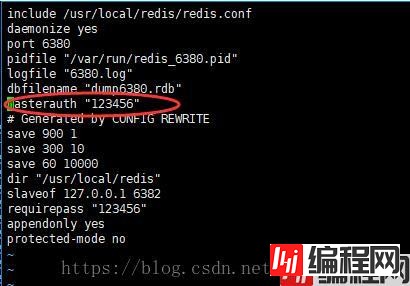
接下里配置好连接密码,再重启一下redis服务
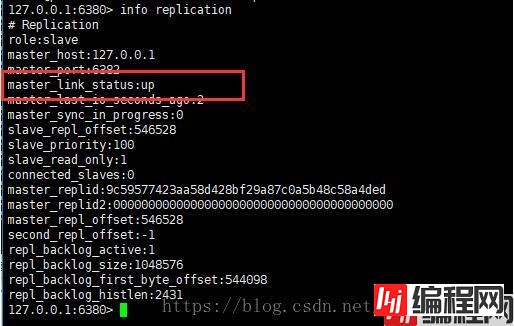
重启后主机连接状态显示正常,问题解决
以上为个人经验,希望能给大家一个参考,也希望大家多多支持编程网。如有错误或未考虑完全的地方,望不吝赐教。
--结束END--
本文标题: Redis Cluster集群主从切换的踩坑与填坑
本文链接: https://lsjlt.com/news/123090.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0