Python 官方文档:入门教程 => 点击学习
对于多线程的使用,我们经常是用thread来创建,比较繁琐. 在python中,可以使用map函数简化代码。map可以实现多任务的并发 简单说明map()实现多线程原理: tas
对于多线程的使用,我们经常是用thread来创建,比较繁琐. 在python中,可以使用map函数简化代码。map可以实现多任务的并发
task = [‘任务1', ‘任务2', ‘任务3', …]map 函数一手包办了序列操作、参数传递和结果保存等一系列的操作,map函数负责将线程分给不同的CPU。
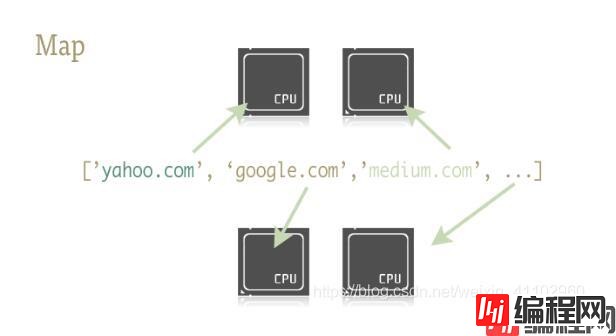
在 Python 中有个两个库包含了 map 函数: multiprocessing 和它鲜为人知的子库 multiprocessing.dummy.dummy 是 multiprocessing 模块的完整克隆,唯一的不同在于 multiprocessing 作用于进程,而 dummy 模块作用于线程。
代码如下:
from multiprocessing.dummy import Pool as ThreadPool
import os
import requests
import time
import numpy as np
# 文件夹位置
filepath = r'C:\Users\Administrator\Desktop\ceshi'
pool = ThreadPool(10)#开启线程数,即一次性抛出的请求数
time_list = []#用来计算时间
xml_list = []#数据集
pathDir = os.listdir(filepath)
for i, allDir in enumerate(pathDir):
filename = os.path.join('%s%s' % (filepath + '\\', allDir))
kk = open(filename, 'r', encoding='utf-8').read()
data = kk.encode('utf-8')
for k in range(10):
xml_list.append(data)
def res(data):
# 访问目标服务器地址
url_host = 'https://mp.csdn.net/mdeditor#'
start = time.clock()
s = requests.post(url_host, data=data)
end = time.clock()
if s.status_code == 200:
print(end-start)
time_list.append(end-start)
else:
print('请求失败')
# 传入的参数,1为函数, 2为参数
result = pool.map(res, xml_list)
all_arr = np.array(time_list)
aver = np.mean(all_arr)
variance = np.var(all_arr)
mid = np.median(all_arr)
min_num = np.min(all_arr)
max_num = np.max(all_arr)
print('平均值 : '+ str(aver))
print('方差 : ' + str(variance))
print('中值 : ' + str(mid))
print('最小值 : ' + str(min_num))
print('最大值 : ' + str(max_num))
个人做的小测试,如果有错误的地方希望留言提出意见及建议。
补充:python多进程(multiprocessing)(map)
map函数一手包办了序列操作,参数传递和结果保存等一系列的操作。
from multiprocessing.dummy import Pool
poop = Pool(4) # 4代表电脑是多少核的
results = pool.map(爬取函数,网址列表)
from multiprocessing.dummy import Pool as ThreadPool
import requests
import time
kv = {'user-agent':'Mozilla/5.0'}
def getsource(url):
html = requests.get(url,headers=kv)
urls = []
for i in range(0,41):
i = i*50
newpage = 'Https://tieba.baidu.com/f?kw=读书&ie=utf-8&pn=' + str(i)
urls.append(newpage)
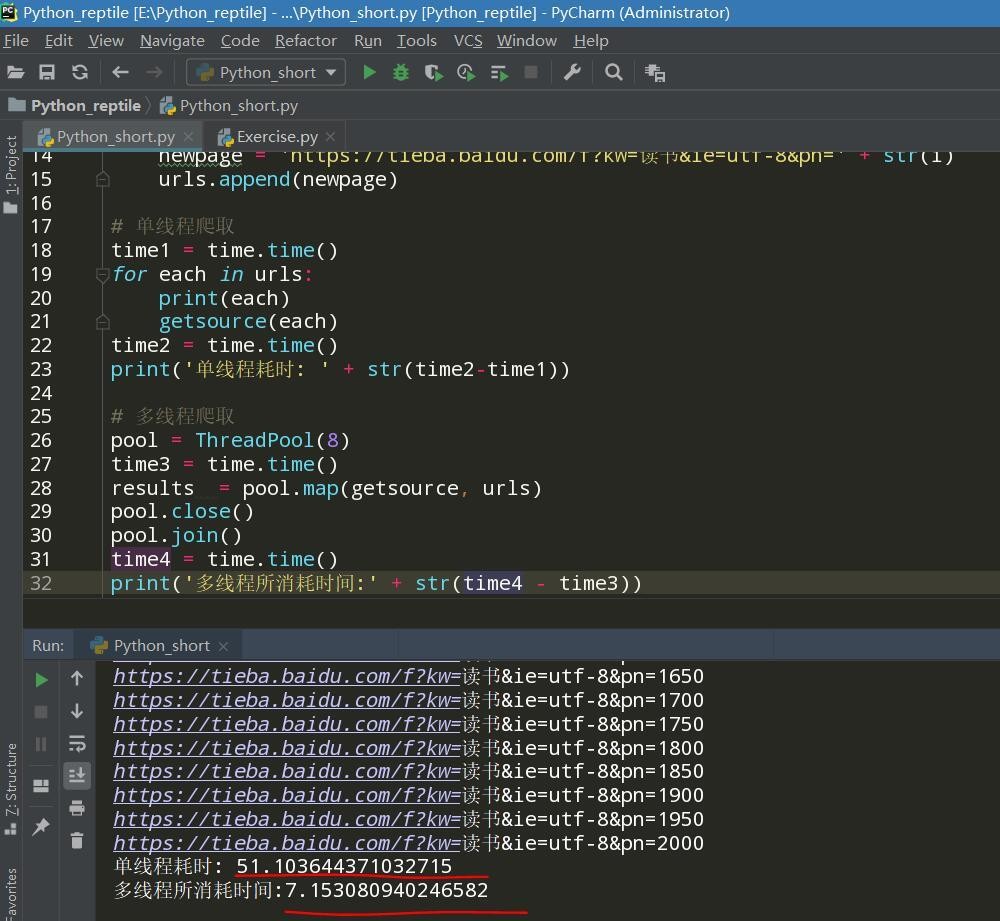
# 单线程爬取
time1 = time.time()
for each in urls:
print(each)
getsource(each)
time2 = time.time()
print('单线程耗时: ' + str(time2-time1))
# 多线程爬取
pool = ThreadPool(8)
time3 = time.time()
results = pool.map(getsource, urls)
pool.close()
pool.join()
time4 = time.time()
print('多线程所消耗时间:' + str(time4 - time3))
以上为个人经验,希望能给大家一个参考,也希望大家多多支持编程网。如有错误或未考虑完全的地方,望不吝赐教。
--结束END--
本文标题: python 如何用map()函数创建多线程任务
本文链接: https://lsjlt.com/news/123046.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0