目录什么是Titanium原理简述对于Http对于https为什么要爬取历史文章实现步骤大致思路核心代码测试结果GitHub:https://github.com/justcodin
GitHub:https://github.com/justcoding121/Titanium-WEB-Proxy
https://github.com/http-party/node-http-proxy
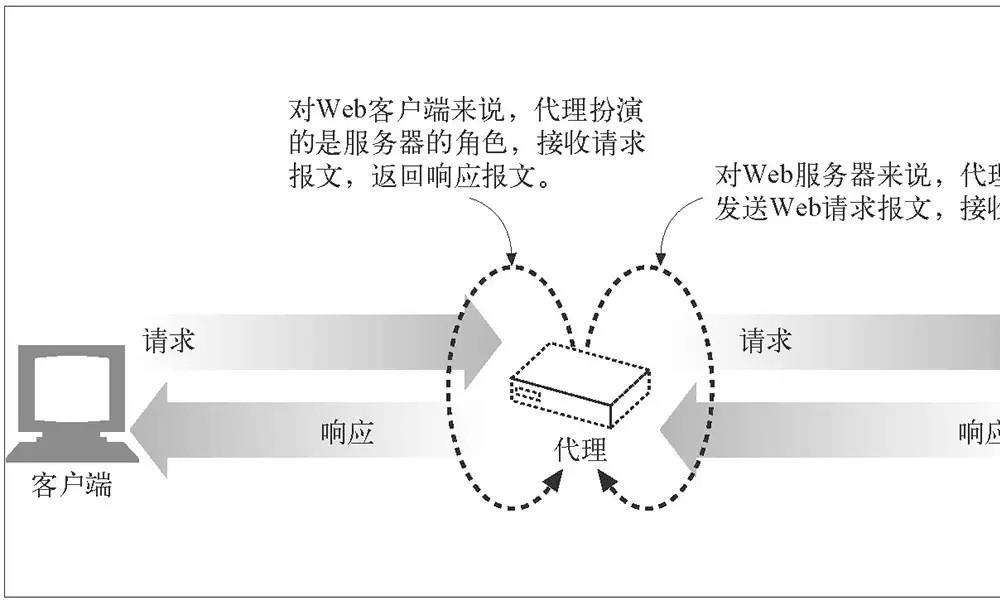
顾名思义,其实代理就是一个「中间人」角色,对于连接到它的客户端来说,它是服务端;对于要连接的服务端来说,它是客户端。它就负责在两端之间来回传送 HTTP 报文。
由于HTTPS加入了CA证书的校验,服务端可不验证客户端的证书,中间人可以伪装成客户端与服务端成功完成 TLS 握手;但是中间人没有服务端证书私钥,无论如何也无法伪装成服务端跟客户端建立 TLS 连接,所以我们需要换个方式代理HTTPS请求。
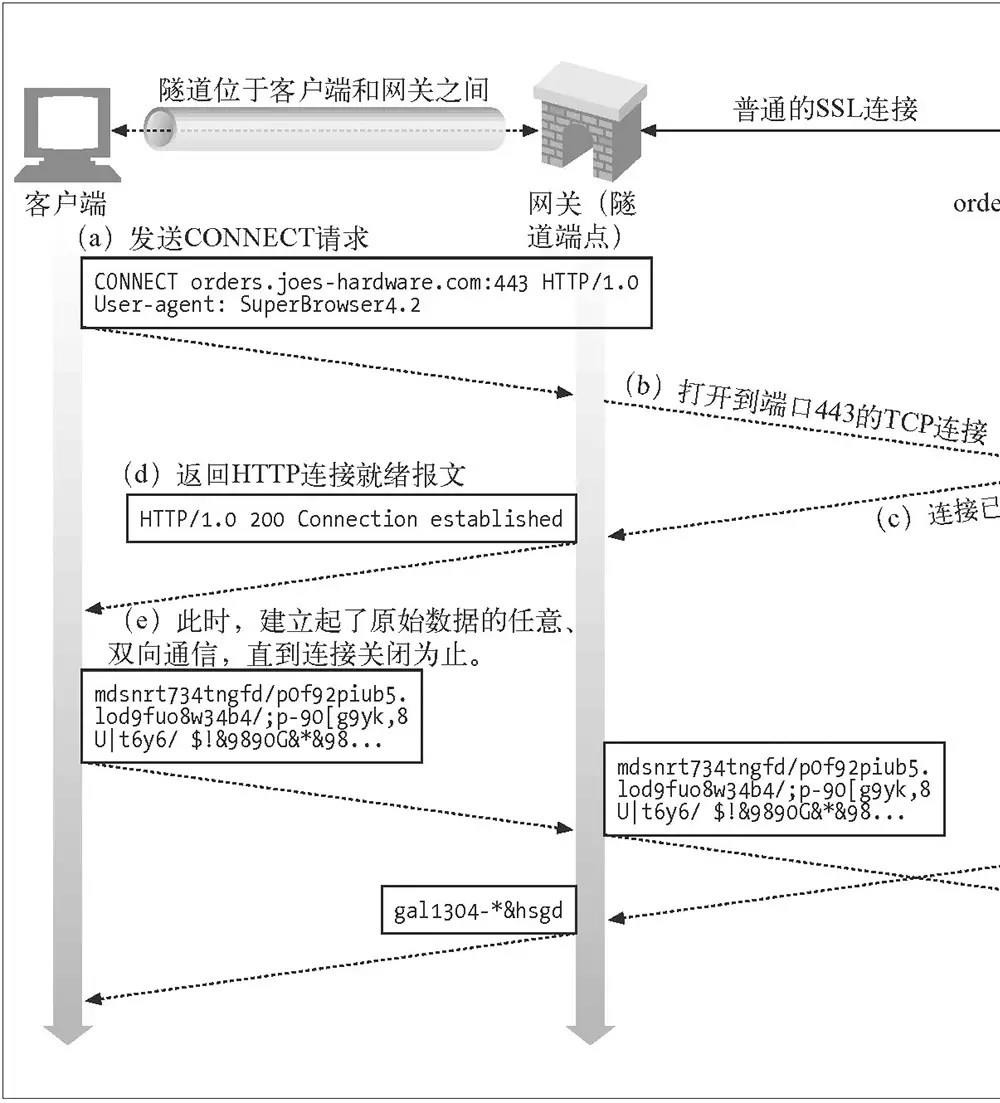
HTTPS在传输层之上建立了安全层,所有的HTTP请求都在安全层上传输。既然无法通过像代理一般HTTP请求的方式在应用层代理HTTPS请求,那么我们就退而求其次为在传输层为客户端和服务器建立起tcp连接。一旦 TCP 连接建好,代理无脑转发后续流量即可。所以这种代理,理论上适用于任意基于 TCP 的应用层协议,HTTPS 网站使用的 TLS 协议当然也可以。这也是这种代理为什么被称为隧道的原因。
但是这样子无脑转发我们就无法获取到他们交互的数据了,怎么办?
此时就需要代理变身为伪HTTPS服务器,然后让客户端信任我们自定义的根证书,从而在客户端和代理、代理和服务端之间都能成功建立 TLS 连接。对于代理来说,两端的TLS流量都是可以解密的。
最后如果这个代理我们可编程,那么我们就可以对传送的HTTP报文做控制。
相关的应用场景有访问控制、防火墙、内容过滤、Web缓存、内容路由等等。
微信官方其实已经提过了素材列表接口
https://developers.weixin.qq.com/doc/offiaccount/Asset_Management/Get_materials_list.html
但是接口获取的素材地址并不是真实在公众号上推送的地址,所以不存在阅读、评论、好看等功能。
这时候需要我们去公众号的历史文章页取数据。
开发环境:Visual Studio CommUnity 2019 for Mac Version 8.5.6 (build 11)
Frameworks:.net core 3.1.0
NuGet:Newtonsoft.JSON 12.0.3、Titanium.Web.Proxy 3.1.1301
1、先实现通过代理抓包HTTPS,拦截微信客户端数据交互。
2、过滤其他地址,只监测微信文章。
3、访问任意微信文章页,获取header和cookie。
4、模拟微信访问历史页、分析抓取历史文章列表。
SpiderProxy.cs
using System;
using System.Collections.Generic;
using System.Linq;
using System.net;
using System.Text.RegularExpressions;
using System.Threading;
using System.Threading.Tasks;
using System.Web;
using Newtonsoft.json.Linq;
using Titanium.Web.Proxy;
using Titanium.Web.Proxy.Http;
using Titanium.Web.Proxy.Models;
namespace WechatArticleSpider
{
public class SpiderProxy
{
private readonly SemaphoreSlim @lock = new SemaphoreSlim(1);
private readonly ProxyServer proxyServer;
private readonly ExplicitProxyEndPoint explicitEndPoint;
public SpiderProxy()
{
proxyServer = new ProxyServer();
//在响应之前事件
proxyServer.BeforeResponse += ProxyServer_BeforeResponse;
//绑定监听端口
explicitEndPoint = new ExplicitProxyEndPoint(IPAddress.Any, 8000, true);
Console.WriteLine("监听地址127.0.0.1:8000");
//隧道请求连接前事件,HTTPS用
explicitEndPoint.BeforeTunnelConnectRequest += ExplicitEndPoint_BeforeTunnelConnectRequest; ;
//代理服务器注册监听地址
proxyServer.AddEndPoint(explicitEndPoint);
}
public void Start()
{
Console.WriteLine("开始监听");
//Start方法会检测证书,若为空会调用CertificateManager.EnsureRootCertificate();为我们自动生成根证书。
proxyServer.Start();
}
public void Stop()
{
// Unsubscribe & Quit
explicitEndPoint.BeforeTunnelConnectRequest -= ExplicitEndPoint_BeforeTunnelConnectRequest;
proxyServer.BeforeResponse -= ProxyServer_BeforeResponse;
Console.WriteLine("结束监听");
proxyServer.Stop();
}
private async Task ExplicitEndPoint_BeforeTunnelConnectRequest(object sender, Titanium.Web.Proxy.EventArguments.TunnelConnectSessionEventArgs e)
{
string hostname = e.HttpClient.Request.RequestUri.Host;
await WriteToConsole("Tunnel to: " + hostname);
if (!hostname.StartsWith("mp.weixin.qq.com"))
{
//是否要解析SSL,不解析就直接转发
e.DecryptSsl = false;
}
}
private async Task ProxyServer_BeforeResponse(object sender, Titanium.Web.Proxy.EventArguments.SessionEventArgs e)
{
var request = e.HttpClient.Request;
//判断是否是微信文章页。
if (request.Host.Contains("mp.weixin.qq.com")&&(request.RequestUriString.StartsWith("/s?") || request.RequestUriString.StartsWith("/s/")))
{
byte[] bytes = await e.GetResponseBody();
string body = System.Text.Encoding.UTF8.GetString(bytes);
ThreadPool.QueueUserWorkItem((stateInfo) => { CrawlAsync(body, e.HttpClient.Request); });
}
}
private async Task CrawlAsync(string body,Request request)
{
//采用正则表达式匹配数据
Match match = Regex.Match(body, @"<strong class=""profile_nickname"">(.+)</strong>");
Match matchGhid = Regex.Match(body, @"var user_name = ""(.+)"";");
if (!match.Success || !matchGhid.Success)
{
return;
}
MatchCollection matches = Regex.Matches(body, @"<span class=""profile_meta_value"">(.+)</span>");
if (match.Groups.Count == 0)
{
return;
}
await WriteToConsole("检测到微信文章页: " + match.Groups[1].Value + " " + matches[0].Groups[1].Value + " " + matches[1].Groups[1].Value + " ");
var queryString = HttpUtility.ParseQueryString(request.RequestUriString.Substring(3));
var httpClient = new HttpClient(request.Headers);
await WriteToConsole("Client实例化,已获取header,cookie");
//获取历史页信息
string result = httpClient.Get(string.FORMat("https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz={0}&scene=124#wechat_redirect", queryString["__biz"]));
//封接口检测
if (result.Contains("操作频繁,请稍后再试"))
{
await WriteToConsole("操作频繁,请稍后再试 限制24小时 请更换微信");
await WriteToConsole("已停止爬虫任务,请更换之后重启助手。");
}
//是否抓取完
bool end = false;
//下标
int offset = 0;
do
{
//获取历史消息
string jsonResult = httpClient.Get(string.Format("https://mp.weixin.qq.com/mp/profile_ext?action=getmsg&__biz={0}&f=json&offset={1}&count=10&is_ok=1&scene=124&uin={2}&key={3}&pass_ticket={4}&wxtoken=&x5=0&f=json", queryString["__biz"], offset, queryString["uin"], queryString["key"], queryString["pass_ticket"]));
JObject jobject = JObject.Parse(jsonResult);
if (Convert.ToInt32(jobject["ret"]) == 0)
{
if (Convert.ToInt32(jobject["can_msg_continue"]) == 0)
{
end = true;
}
offset = Convert.ToInt32(jobject["next_offset"]);
string strList = jobject["general_msg_list"].ToString();
JObject temp = JObject.Parse(strList);
List<JToken> list = temp["list"].ToList();
foreach (var item in list)
{
JToken comm_msg_info = item["comm_msg_info"];
JToken app_msg_ext_info = item["app_msg_ext_info"];
if (app_msg_ext_info == null)
{
continue;
}
//发布时间
string publicTime = comm_msg_info["datetime"].ToString();
//文章标题
string title = app_msg_ext_info["title"].ToString();
//文章摘要
string digest = app_msg_ext_info["digest"].ToString();
//文章地址
string content_url = app_msg_ext_info["content_url"].ToString();
//文章封面
string cover = app_msg_ext_info["cover"].ToString();
//作者
string author = app_msg_ext_info["author"].ToString();
await WriteToConsole(String.Format("{0},{1},{2},{3},{4},{5}", publicTime, title, digest, content_url, cover, author));
//今天发布了多条消息
if (app_msg_ext_info["is_multi"].ToString() == "1")
{
foreach (var multiItem in app_msg_ext_info["multi_app_msg_item_list"].ToList())
{
title = multiItem["title"].ToString();
digest = multiItem["digest"].ToString();
content_url = multiItem["content_url"].ToString();
cover = multiItem["cover"].ToString();
author = multiItem["author"].ToString();
await WriteToConsole(String.Format("{0},{1},{2},{3},{4},{5}", publicTime, title, digest, content_url, cover, author));
}
}
}
}
else
{
end = true;
}
//每5秒翻页一次
await Task.Delay(5000);
} while (!end);
await WriteToConsole("历史文章抓取完成");
}
private async Task WriteToConsole(string message, ConsoleColor? consoleColor = null)
{
await @lock.WaitAsync();
if (consoleColor.HasValue)
{
ConsoleColor existing = Console.ForegroundColor;
Console.ForegroundColor = consoleColor.Value;
Console.WriteLine(message);
Console.ForegroundColor = existing;
}
else
{
Console.WriteLine(message);
}
@lock.Release();
}
}
}HttpClient.cs
using System;
using System.IO;
using System.Net;
using System.Threading;
using Titanium.Web.Proxy.Http;
namespace WechatArticleSpider
{
class HttpClient
{
private readonly HeaderCollection headerCollection;
private readonly CookieContainer cookieContainer = new CookieContainer();
/// <summary>
/// 微信请求客户端
/// </summary>
/// <param name="headerCollection">拦截微信请求头集合</param>
public HttpClient(HeaderCollection headerCollection)
{
cookieContainer = new CookieContainer();
ServicePointManager.DefaultConnectionLimit = 512;
ServicePointManager.SecurityProtocol = SecurityProtocolType.Tls12 | SecurityProtocolType.Tls11;
this.headerCollection = headerCollection;
}
/// <summary>
/// 带微信参数的GET请求
/// </summary>
/// <param name="url">请求地址</param>
/// <returns>请求结果</returns>
public string Get(string url)
{
string ret = Retry<string>(() =>
{
HttpWebRequest webRequest = WebRequest.CreateHttp(url);
webRequest = PretendWechat(webRequest);
HttpWebResponse response = webRequest.GetResponse() as HttpWebResponse;
string result = new StreamReader(response.GetResponseStream()).ReadToEnd();
return result;
});
return ret;
}
/// <summary>
/// 伪造微信请求
/// </summary>
/// <param name="request">需要伪造的request</param>
/// <returns></returns>
public HttpWebRequest PretendWechat(HttpWebRequest request)
{
try
{
request.Host = headerCollection.Headers["Host"].Value;
request.UserAgent = headerCollection.Headers["User-Agent"].Value;
request.Headers.Set(headerCollection.Headers["Accept-Language"].Name, headerCollection.Headers["Accept-Language"].Value);
request.Headers.Set(headerCollection.Headers["Accept-Encoding"].Name, headerCollection.Headers["Accept-Encoding"].Value);
cookieContainer.SetCookies(new Uri("https://mp.weixin.qq.com"), headerCollection.Headers["Cookie"].Value.Replace(";", ","));
request.KeepAlive = true;
request.Accept = headerCollection.Headers["Accept"].Value;
request.AutomaticDecompression = DecompressionMethods.Deflate | DecompressionMethods.GZip;
request.CookieContainer = cookieContainer;
request.AllowAutoRedirect = true;
request.ServicePoint.Expect100Continue = false;
request.Timeout = 35000;
return request;
}
catch (Exception e)
{
Console.WriteLine(e.Message);
throw;
}
}
/// <summary>
/// 三次重试机制
/// </summary>
/// <typeparam name="T">参数类型</typeparam>
/// <param name="func">方法</param>
/// <returns></returns>
private static T Retry<T>(Func<T> func)
{
int err = 0;
while (err < 3)
{
try
{
return func();
}
catch (WebException webExp)
{
err++;
Thread.Sleep(5000);
if (err > 2)
{
throw webExp;
}
}
}
return func();
}
}
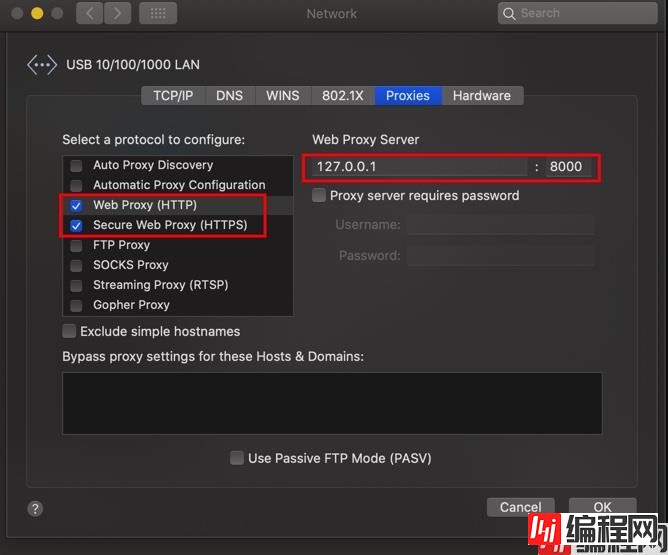
}首先我们主动设置一下系统代理。
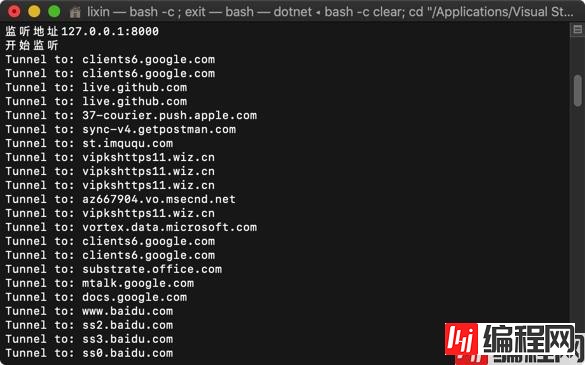
接着启动代理。
对于不是目标地址的https请求,一律过滤直接转发。
此时Titanium应该会为我们生成了根证书。
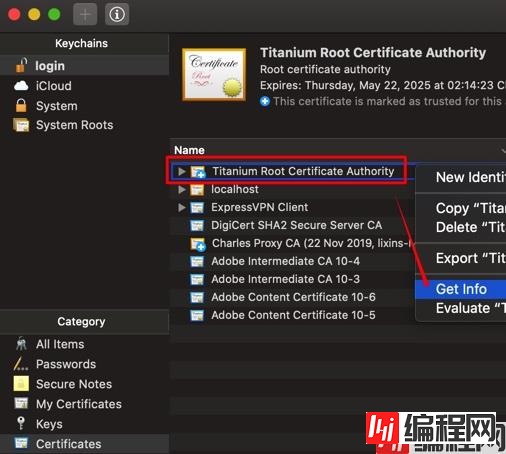
右键-》Get Info-》Trust-》选择Always Trust,如果不信任根证书,会发现ProxyServer_BeforeResponse不执行。
最后我们随意的访问一篇公众号文章,代理就会执行脚本去抓公众号的历史文章列表了。

demo:链接:https://pan.baidu.com/s/1ZafgBH1dEiDcdB9E77osFg 密码:tuuv
以上就是c# 基于Titanium爬取微信公众号历史文章列表的详细内容,更多关于c# 基于Titanium爬取公众号历史文章的资料请关注编程网其它相关文章!
--结束END--
本文标题: c# 基于Titanium爬取微信公众号历史文章列表
本文链接: https://lsjlt.com/news/121430.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0