Python 官方文档:入门教程 => 点击学习
之前在一次跟“某Fish”客户进行交谈时,我在的需求下学习了多项贝叶斯(Multinomial Naive Bayes)这个模型。 在了解多项贝叶斯模型之前,
之前在一次跟“某Fish”客户进行交谈时,我在的需求下学习了多项贝叶斯(Multinomial Naive Bayes)这个模型。
在了解多项贝叶斯模型之前,我们首先来了解一下朴素贝叶斯(Naive Bayes)模型。
贝叶斯定理所描述的,即为一个抽象事件A在抽象事件B发生的前提下,有多大概率会发生抽象事件A,其概率记为:

其中`P(B)`记为抽象事件B本身发生的概率,因此贝叶斯定理正好计算的是`抽象事件AB同时发生`概率与抽象事件B单独发生的概率之比,这也能证明其抽象事件发生的先后顺序。
文字太过生涩难懂?我这里有一张图可以供大家参考:
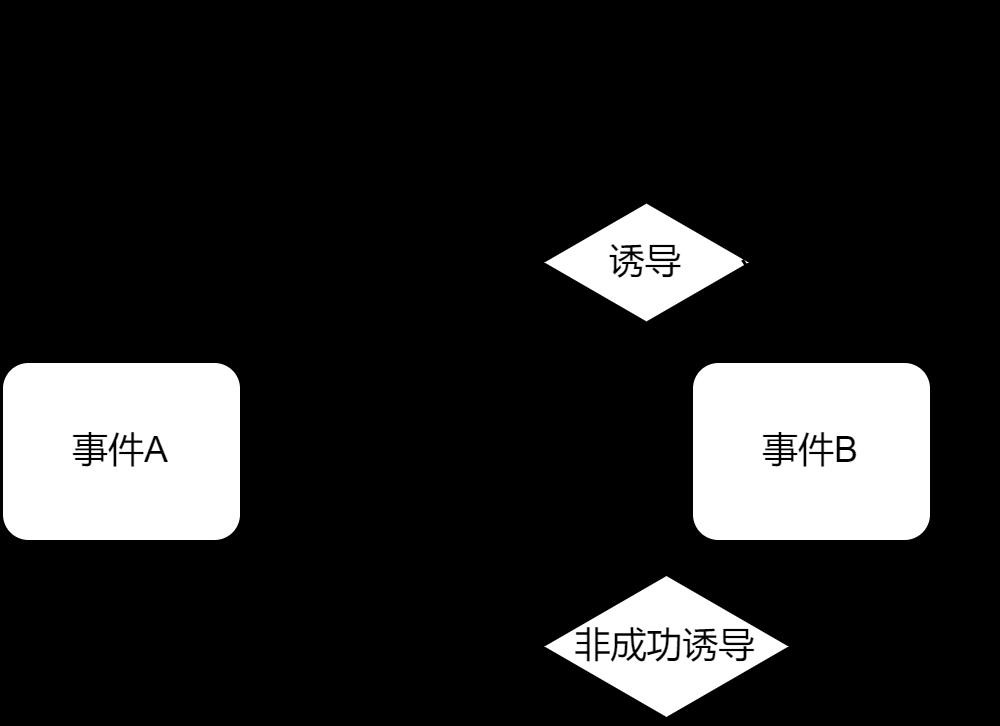
可以通过上述流程我们看到:事件A为确定发生的事件,在A事件发生后,其有可能诱导了事件B的发生,也可能诱导失败了。
抛开诱导失败的情况,我们只谈及诱导成功的情况。虽然我们这里说事件A成功诱导了事件B,但是作为一个独立的实体,事件B本身发生的概率也是一个不确定值,因此这里需要贝叶斯模型进行自动推理,去计算前置的因素是否有可能诱导了后一事件的发生。
我们来看例子,这里我有一个数据框,我们来展示一下的现有列
ModelData.columns
Index(['全局水平', '大气温度 [℃]', '风冷温度 [℃]', '露点温度 [℃]', '相对湿度 [%]', '平均十米内风速 [m/s]',
'站点压力 [mBar]', '降水量 [mm]', '定点角度 [°]', '方位角度 [°]', '气团大小', '气团变化'],
dtype='object')在这份模型数据。我们需要对气团变化进行研究,其中我使用cuDF内置的.to_pandas()函数将GPU数据框转换为Pandas数据框,并使用.apply()+lambda隐函数对气团大小的变化进行类分类,
这里因为使用了DecisionTree决策树来训练第二个模型,因此数据被命名为了df_train_Tree,最终模型仍然为多项贝叶斯模型。
# 使用.apply()函数来实现来为气团变化进行标签化处理
df_train_Tree['气团变化'] = df_train_Tree['气团大小'].to_pandas().apply(lambda x:0 if x == 0 else 1 if x < 0 else 2 if x > 0 else None)对数据进行处理,并使用cuML继承自sklearn的train_test_split()函数对数据进行分割
# 进行绝对值翻转处理,以防止存在负值无法训练模型
ModelData = df_train_Tree.iloc[:,2:].to_pandas().apply(lambda x: x.abs())
ModelData = cf.DataFrame(ModelData)
# 构建训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(ModelData,ModelData['气团变化'], test_size=0.2, random_state=42)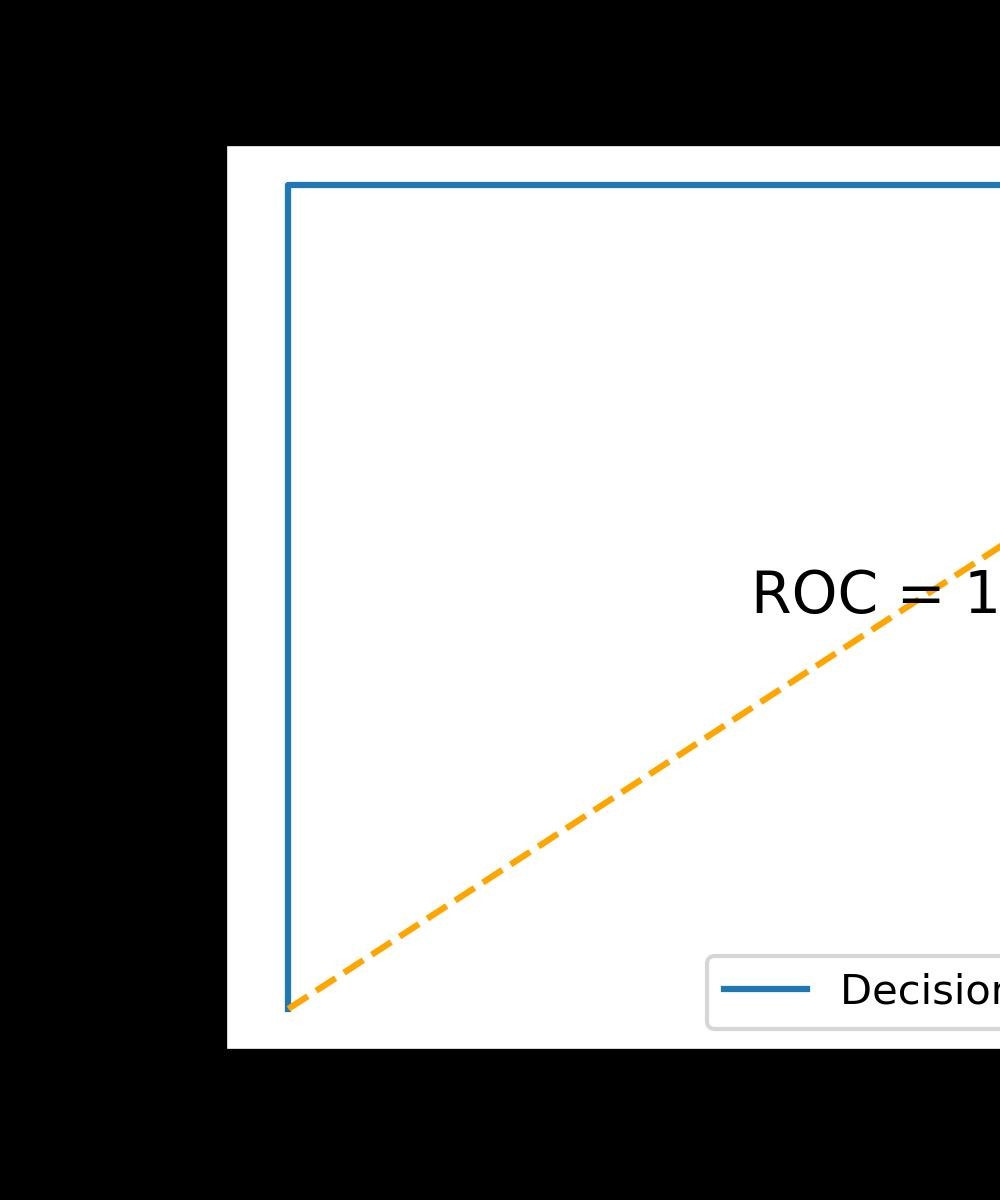
通过sklearn.metrics下的plot_roc_curve()函数绘制的ROC曲线和roc_auc_score()函数我们发现,此时的决策树模型处于了过拟合的情况,在树中我没有指定明确的二值化数据(即树判断需要的最基本的真和假),因此使得树在判断时全部当成了真的条件,所以树已经严重过拟合了。
通过之前的一些列的线性校验,我们也得知了:前置的一切属性均为`可能`诱导气团大小的`诱因`
因此在完全不确定的情况下,我们将使用全部属性进行模型的初步测试。
因此我们最终需要使用多项贝叶斯模型来进行模型构建,以下是多项贝叶斯在GPU环境上的实现
# 因为属性众多,因此我们需要引入多项分布朴素贝叶斯(Multinomial NB)
from sklearn.naive_bayes import MultinomialNB
clf = MultinomialNB()
# 将训练集进行训练
clf.fit(X_train.to_pandas(), y_train.to_numpy())
MultinomialNB()
# 绘制ROC曲线以验证预测结果
plot_roc_curve(clf, X_test.to_pandas(), y_test.to_numpy())
plt.title('ROC Curve')
plt.plot([0, 1], [0, 1], '--',color='orange')
plt.text(0.5, 0.5, 'ROC = %.2f' % roc_auc_score(y_test.to_pandas(),cp.asnumpy(y_pred)), ha='center', va='center', fontsize=14)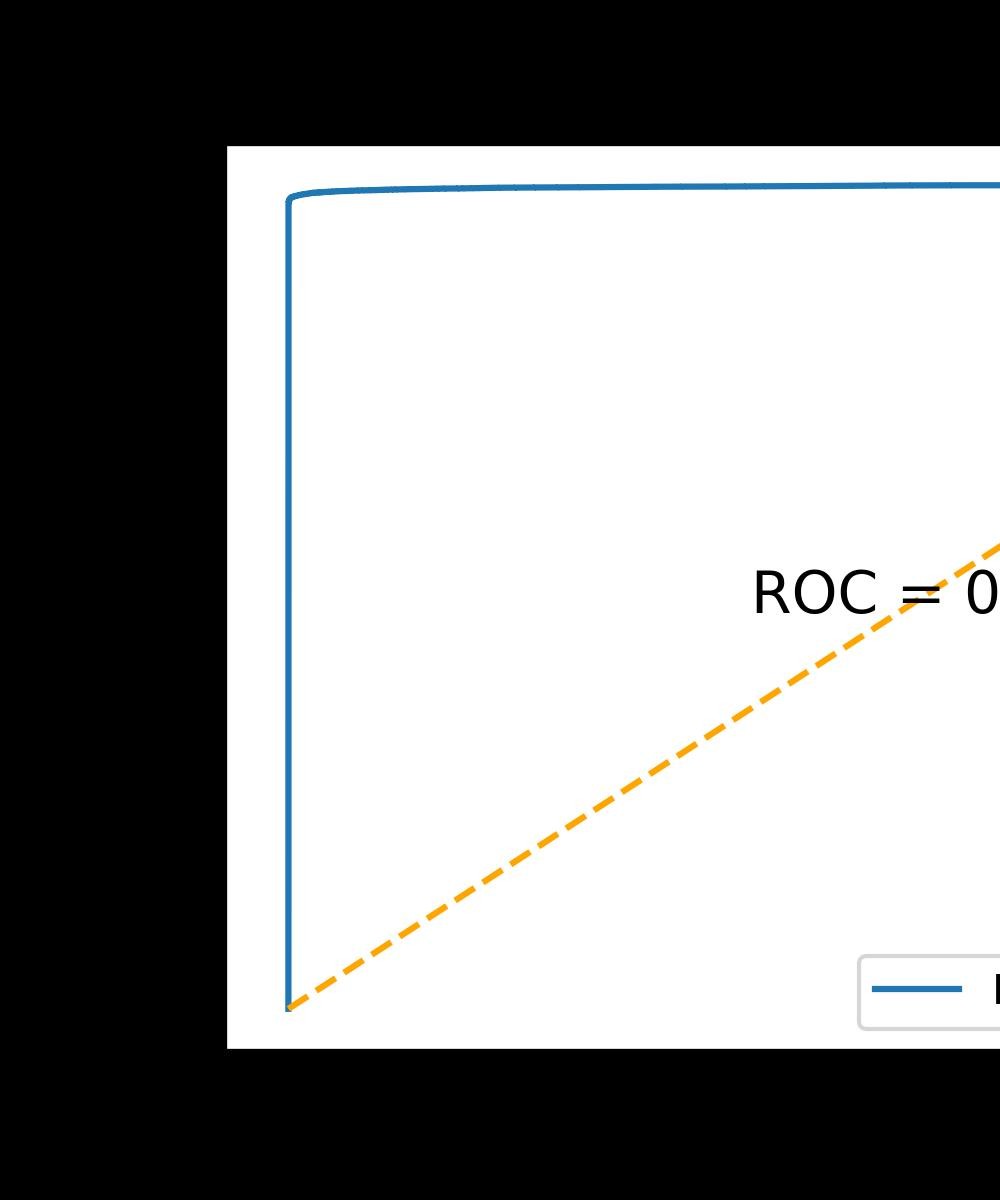
可以看到,在多项贝叶斯模型下,我们的成绩表现已经非常不错了,roc_auc_score分数表现为:0.92,这也得以证明我们之前训练过的模型它是一个显著过拟合的模型。
总结:
在皮尔森系数过低,但又存在微弱线性相关的分类问题,我们可以尝试使用推测的手段:即贝叶斯类模型,在我们能够肯定前置因素可能会诱导后一事件的这一前提下,我们就可以进行贝叶斯魔性的尝试了
到此这篇关于Multinomial Naive Bayes多项贝叶斯模型实现原理介绍的文章就介绍到这了,更多相关Multinomial Naive Bayes内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: PythonMultinomialNaiveBayes多项贝叶斯模型实现原理介绍
本文链接: https://lsjlt.com/news/120493.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0