Python 官方文档:入门教程 => 点击学习
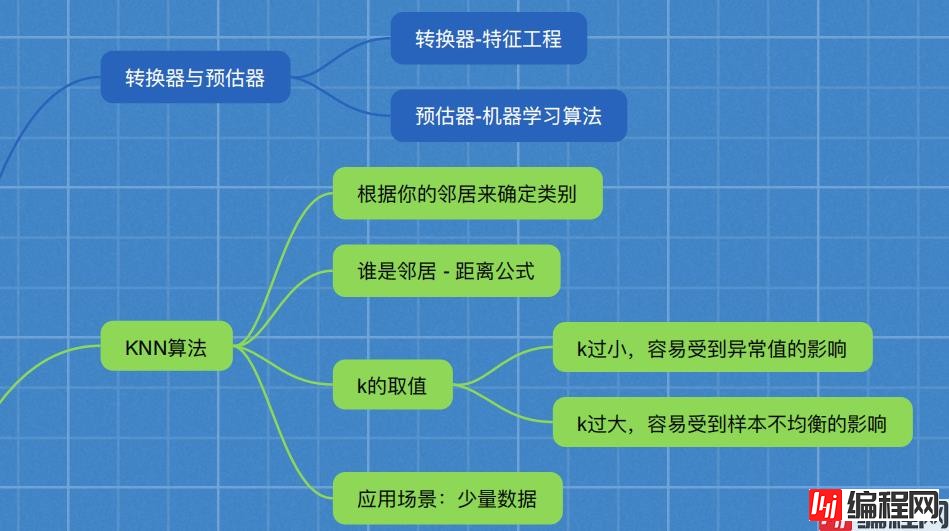
目录一、转换器和估计器1. 转换器2.估计器(sklearn机器学习算法的实现)3.估计器工作流程二、K-近邻算法1.K-近邻算法(KNN)2. 定义3. 距离公式三、电影类型分析1
想一下之前做的特征工程的步骤?
我们把特征工程的接口称之为转换器,其中转换器调用有这么几种形式:
这几个方法之间的区别是什么呢?我们看以下代码就清楚了
In [1]: from sklearn.preprocessing import StandardScaler
In [2]: std1 = StandardScaler()
In [3]: a = [[1,2,3], [4,5,6]]
In [4]: std1.fit_transform(a)
Out[4]:
array([[-1., -1., -1.],
[ 1., 1., 1.]])
In [5]: std2 = StandardScaler()
In [6]: std2.fit(a)
Out[6]: StandardScaler(copy=True, with_mean=True, with_std=True)
In [7]: std2.transform(a)
Out[7]:
array([[-1., -1., -1.],
[ 1., 1., 1.]])从中可以看出,fit_transform的作用相当于transform加上fit。
但是为什么还要提供单独的fit呢, 我们还是使用原来的std2来进行标准化看看:
In [8]: b = [[7,8,9], [10, 11, 12]]
In [9]: std2.transform(b)
Out[9]:
array([[3., 3., 3.],
[5., 5., 5.]])
In [10]: std2.fit_transform(b)
Out[10]:
array([[-1., -1., -1.],
[ 1., 1., 1.]])在sklearn中,估计器(estimator)是一个重要的角色,是一类实现了算法的API
种类:1、用于分类的估计器:
2、用于回归的估计器:
3、用于无监督学习的估计器
你的“邻居”来推断出你的类别
如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
来源:KNN算法最早是由Cover和Hart提出的一种分类算法
两个样本的距离可以通过如下公式计算,又叫欧式距离
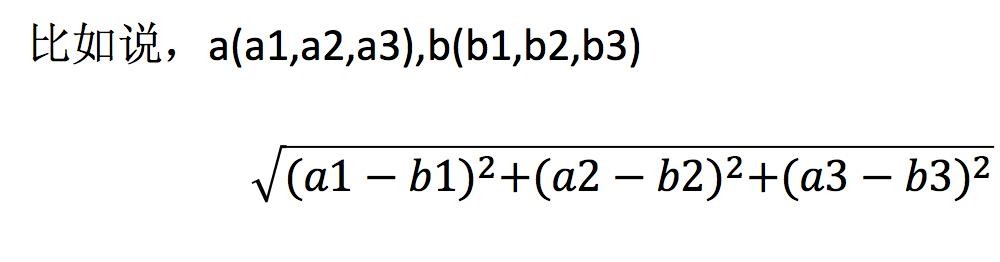
假设我们有现在几部电影:
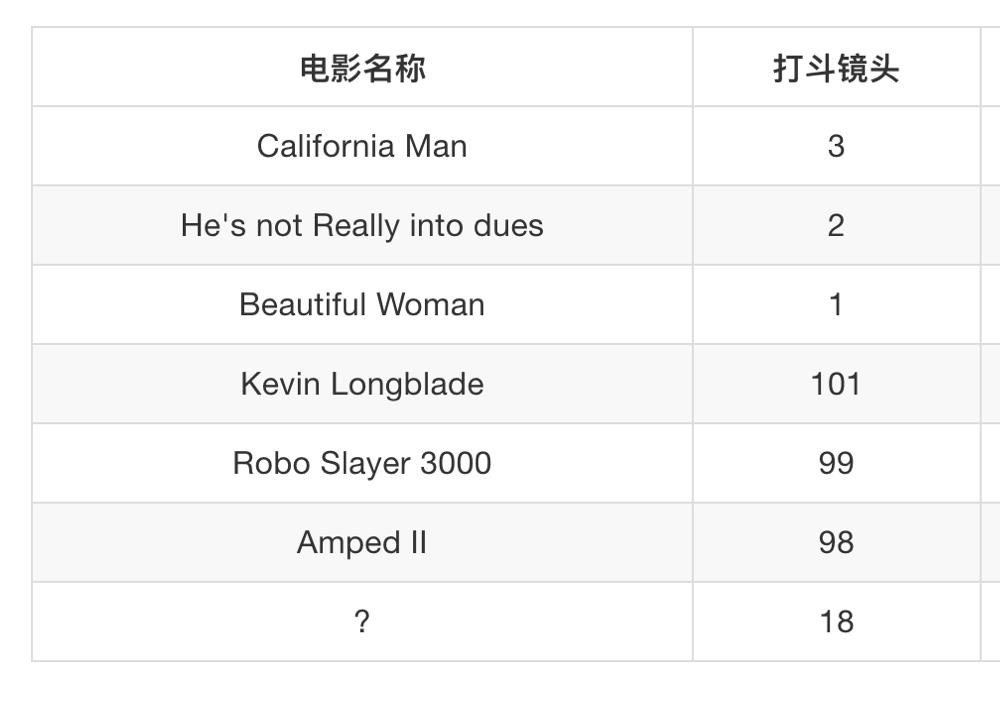
其中? 号电影不知道类别,如何去预测?我们可以利用K近邻算法的思想
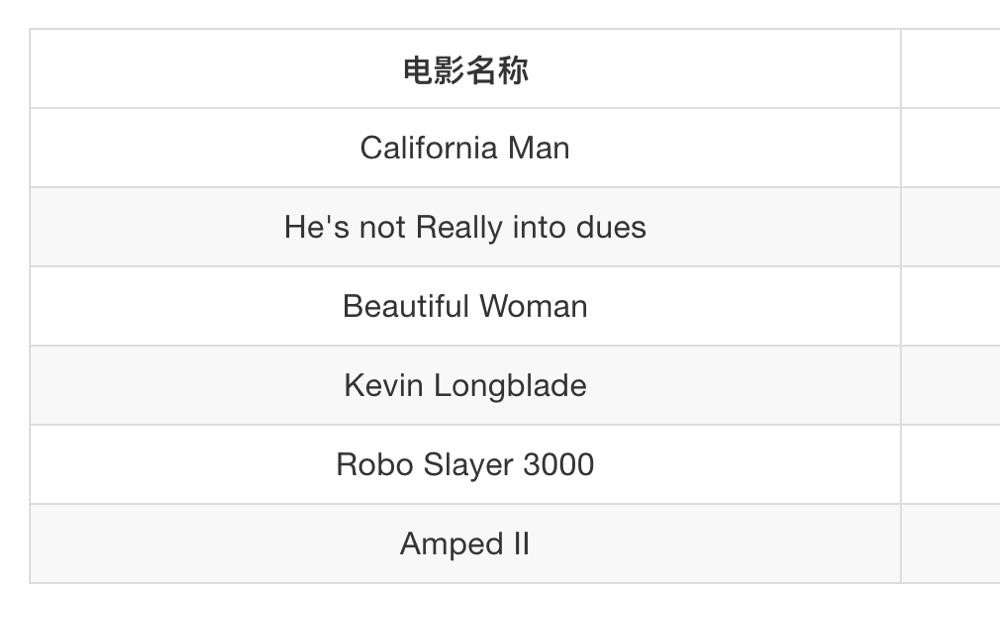
如果取的最近的电影数量不一样?会是什么结果?
k = 1 爱情片
k = 2 爱情片
……
k = 6 无法确定
k = 7 动作片
如果取的最近的电影数量不一样?会是什么结果?
- - k 值取得过小,容易受到异常点的影响
- - k 值取得过大,样本不均衡的影响
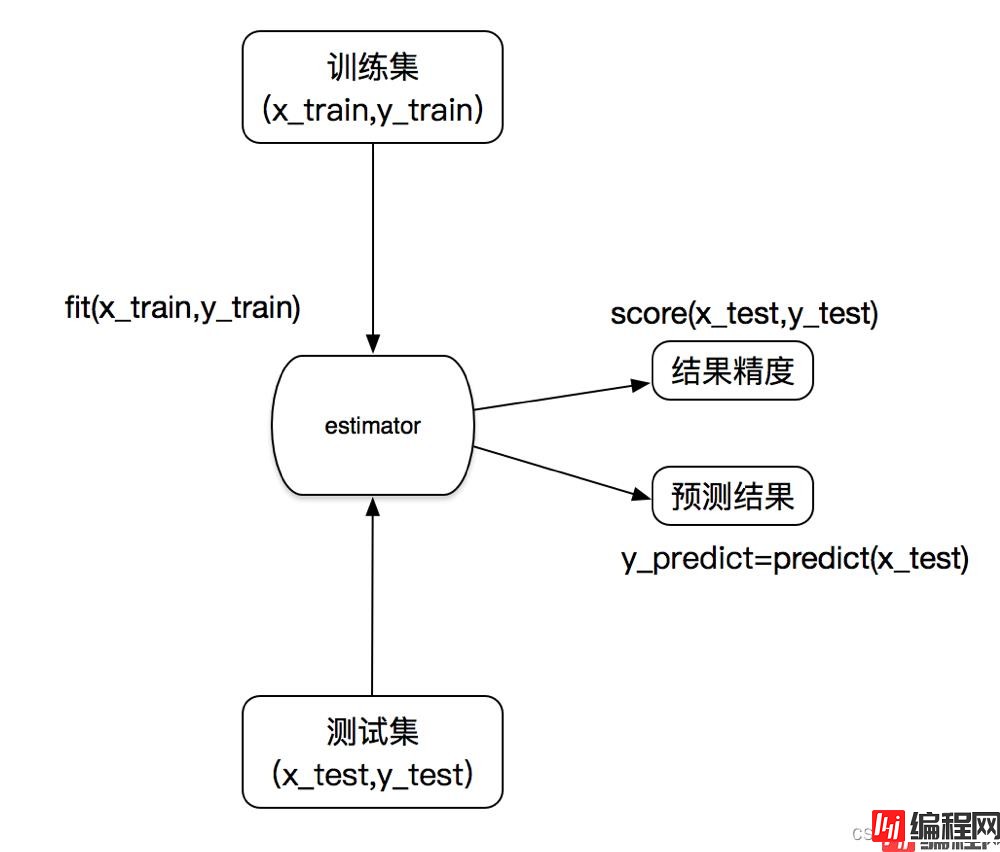
结合前面的约会对象数据,分析K-近邻算法需要做什么样的处理
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm=‘auto’)n_neighbors:k值
鸢尾花种类预测:数据,我们用的就是sklearn中自带的鸢尾花数据。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
def knn_iris():
"""
用KNN算法对鸢尾花进行分类
:return:
"""
# 1)获取数据
iris = load_iris()
# 2)划分数据集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)
# 3)特征工程:标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4)KNN算法预估器
estimator = KNeighborsClassifier(n_neighbors=3)
estimator.fit(x_train, y_train)
# 5)模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)
# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
return None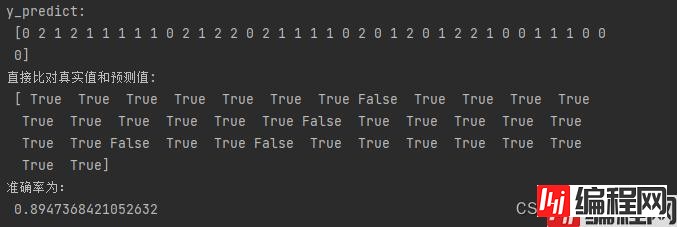
结果分析:准确率: 分类算法的评估之一
1、k值取多大?有什么影响?
k值取很小:容易受到异常点的影响k值取很大:受到样本均衡的问题
2、性能问题?
距离计算上面,时间复杂度高
优点:简单,易于理解,易于实现,无需训练
缺点:
使用场景: 小数据场景,几千~几万样本,具体场景具体业务去测试
到此这篇关于python sklearn转换器估计器和K-近邻算法的文章就介绍到这了,更多相关Python sklearn 内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: Python sklearn转换器估计器和K-近邻算法
本文链接: https://lsjlt.com/news/120244.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0