Python 官方文档:入门教程 => 点击学习
目录1. 列表1.1 列表的定义1.2 列表常用操作1.3 循环遍历1.4 应用场景2. 元组2.1 元组的定义2.2 元组常用操作2.3 循环遍历2.4 应用场景3. 字典3.1
List(列表) 是Python 中使用最频繁的数据类型,在其他语言中通常叫做数组[] 定义,数据之间使用, 分隔0 开始注意:从列表中取值时,如果 超出索引范围,程序会报错
name_list = ["zhangsan", "lisi", "wangwu"]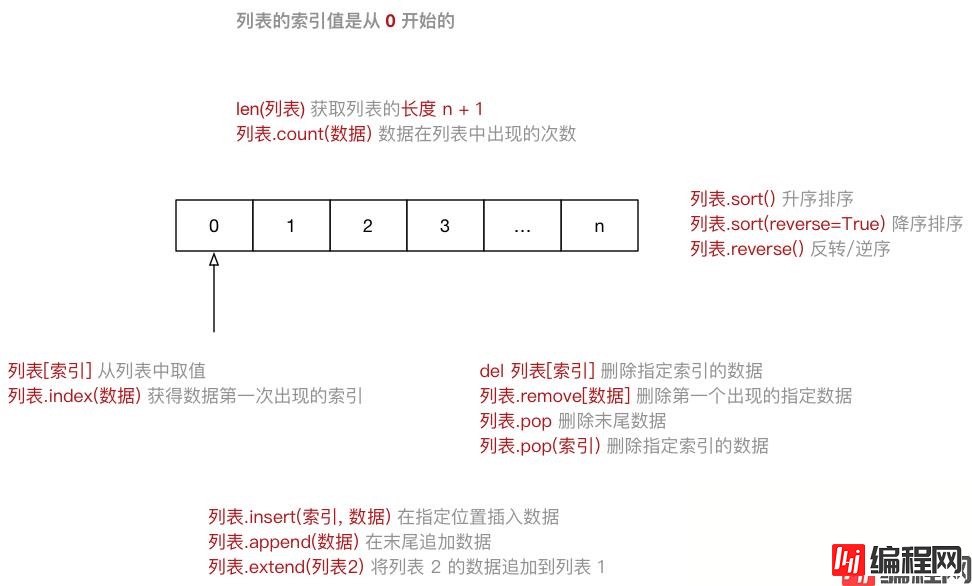
ipython3 中定义一个列表,例如:name_list = []name_list. 按下TAB 键,ipython 会提示列表能够使用的方法如下:In [1]: name_list.
name_list.append name_list.count name_list.insert name_list.reverse
name_list.clear name_list.extend name_list.pop name_list.sort
name_list.copy name_list.index name_list.remove序号 | 分类 | 关键字 / 函数 / 方法 | 说明 |
1 | 增加 | 列表.insert(索引, 数据) | 在指定位置插入数据 |
列表.append(数据) | 在末尾追加数据 | ||
列表.extend(列表2) | 将列表2 的数据追加到列表 | ||
2 | 修改 | 列表[索引] = 数据 | 修改指定索引的数据 |
3 | 删除 | del 列表[索引] | 删除指定索引的数据 |
列表.remove[数据] | 删除第一个出现的指定数据 | ||
列表.pop | 删除末尾数据 | ||
列表.pop(索引) | 删除指定索引数据 | ||
列表.clear | 清空列表 | ||
4 | 统计 | len(列表) | 列表长度 |
列表.count(数据) | 数据在列表中出现的次数 | ||
5 | 列表.sort() | 升序排序 | |
列表.sort(reverse=True) | 降序排序 | ||
列表.reverse() | 逆序、反转 |
del 关键字(科普):
del 关键字(delete) 同样可以删除列表中元素del 关键字本质上是用来将一个变量从内存中删除的del 关键字将变量从内存中删除,后续的代码就不能再使用这个变量了del name_list[1]在日常开发中,要从列表删除数据,建议 使用列表提供的方法
关键字、函数和方法(科普):
关键字是 Python 内置的、具有特殊意义的标识符
关键字后面不需要使用括号
函数封装了独立功能,可以直接调用
函数名(参数)
函数需要死记硬背
对象.方法名(参数)
在变量后面输入
.,然后选择针对这个变量要执行的操作,记忆起来比函数要简单很多
Python 中为了提高列表的遍历效率,专门提供的 迭代 iteration 遍历for 就能够实现迭代遍历# for 循环内部使用的变量 in 列表
for name in name_list:
循环内部针对列表元素进行操作
print(name)
Python 的列表中可以存储不同类型的数据Tuple(元组)与列表类似,不同之处在于元组的元素不能修改
Python 开发中,有特定的应用场景, 分隔() 定义0 开始info_tuple = ("zhangsan", 18, 1.75)创建空元组:
info_tuple = ()元组中只包含一个元素时,需要在元素后面添加逗号:
info_tuple = (50, )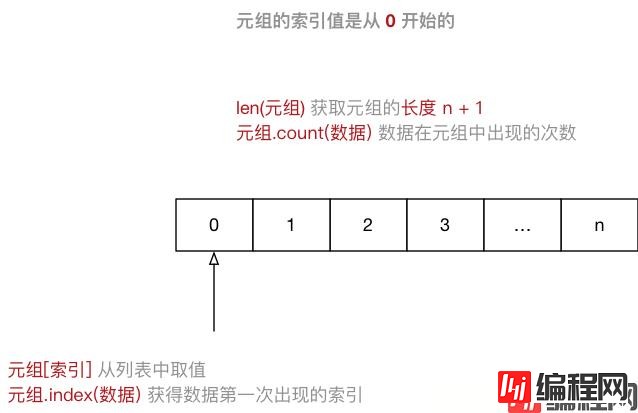
ipython3 中定义一个元组,例如:info = ()info. 按下TAB 键,ipython 会提示元组能够使用的函数如下:info.count info.index有关 元组 的 常用操作 可以参照上图练习
# for 循环内部使用的变量 in 元组
for item in info:
循环内部针对元组元素进行操作
print(item)Python 中,可以使用for 循环遍历所有非数字型类型的变量:列表、元组、字典以及字符串for in 遍历元组() 本质上就是一个元组info = ("zhangsan", 18)
print("%s 的年龄是 %d" % info)元组和列表之间的转换:
list 函数可以把元组转换成列表list(元组)tuple 函数可以把列表转换成元组tuple(列表)dictionary(字典) 是除列表以外Python 之中最灵活的数据类型物体 的相关信息{} 定义, 分隔key 是索引value 是数据: 分隔xiaoming = {"name": "小明",
"age": 18,
"gender": True,
"height": 1.75}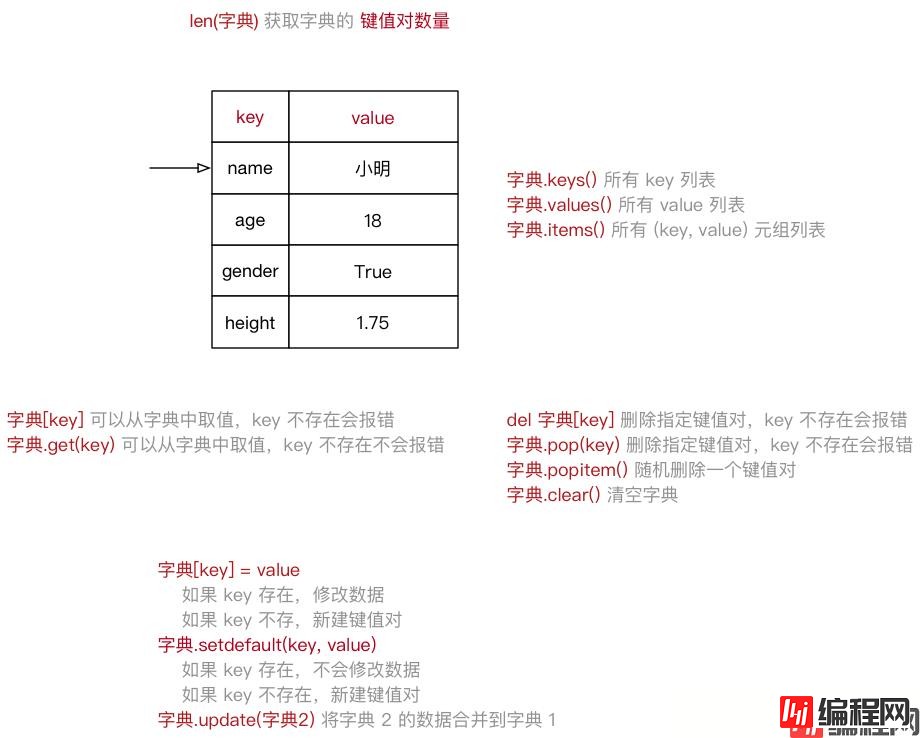
ipython3 中定义一个字典,例如:xiaoming = {}xiaoming. 按下TAB 键,ipython 会提示字典能够使用的函数如下:In [1]: xiaoming.
xiaoming.clear xiaoming.items xiaoming.setdefault
xiaoming.copy xiaoming.keys xiaoming.update
xiaoming.fromkeys xiaoming.pop xiaoming.values
xiaoming.get xiaoming.popitem有关 字典 的 常用操作 可以参照上图练习
# for 循环内部使用的 `key 的变量` in 字典
for k in xiaoming:
print("%s: %s" % (k, xiaoming[k]))提示:在实际开发中,由于字典中每一个键值对保存数据的类型是不同的,所以针对字典的循环遍历需求并不是很多
for in 遍历字典物体 的相关信息—— 描述更复杂的数据信息card_list = [{"name": "张三",
"qq": "12345",
"phone": "110"},
{"name": "李四",
"qq": "54321",
"phone": "10086"}
]" 或者一对单引号' 定义一个字符串\" 或者\' 做字符串的转义,但是在实际开发中:",可以使用' 定义字符串',可以使用" 定义字符串for循环遍历字符串中每一个字符大多数编程语言都是用
"来定义字符串
string = "Hello Python"
for c in string:
print(c)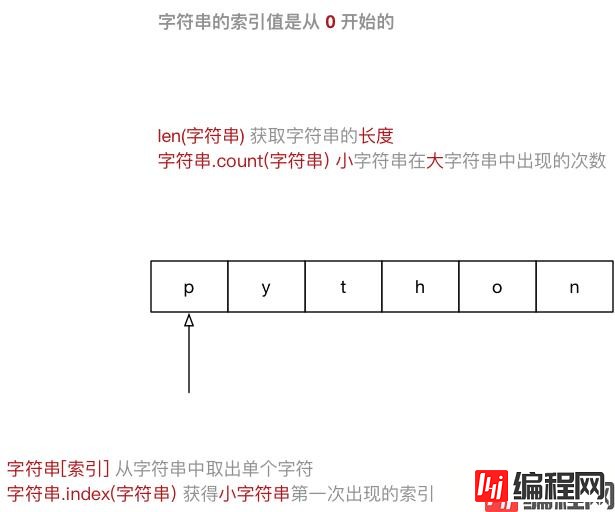
ipython3 中定义一个字符串,例如:hello_str = ""hello_str. 按下TAB 键,ipython 会提示字符串能够使用的方法如下:In [1]: hello_str.
hello_str.capitalize hello_str.isidentifier hello_str.rindex
hello_str.casefold hello_str.islower hello_str.rjust
hello_str.center hello_str.isnumeric hello_str.rpartition
hello_str.count hello_str.isprintable hello_str.rsplit
hello_str.encode hello_str.isspace hello_str.rstrip
hello_str.endswith hello_str.istitle hello_str.split
hello_str.expandtabs hello_str.isupper hello_str.splitlines
hello_str.find hello_str.join hello_str.startswith
hello_str.fORMat hello_str.ljust hello_str.strip
hello_str.format_map hello_str.lower hello_str.swapcase
hello_str.index hello_str.lstrip hello_str.title
hello_str.isalnum hello_str.maketrans hello_str.translate
hello_str.isalpha hello_str.partition hello_str.upper
hello_str.isdecimal hello_str.replace hello_str.zfill
hello_str.isdigit hello_str.rfind提示:正是因为 python 内置提供的方法足够多,才使得在开发时,能够针对字符串进行更加灵活的操作!应对更多的开发需求!
方法 | 说明 |
string.isspace() | 如果 string 中只包含空格,则返回 True |
string.isalnum() | 如果 string 至少有一个字符并且所有字符都是字母或数字则返回 True |
string.isalpha() | 如果 string 至少有一个字符并且所有字符都是字母则返回 True |
string.isdecimal() | 如果 string 只包含数字则返回 True, |
string.isdigit() | 如果 string 只包含数字则返回 True, |
string.isnumeric() | 如果 string 只包含数字则返回 True, |
string.istitle() | 如果 string 是标题化的(每个单词的首字母大写)则返回 True |
string.islower() | 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True |
string.isupper() | 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True |
方法 | 说明 |
string.startswith(str) | 检查字符串是否是以 str 开头,是则返回 True |
string.endswith(str) | 检查字符串是否是以 str 结束,是则返回 True |
string.find(str, start=0, end=len(string)) | 检测 str 是否包含在 string 中,如果 start 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回 |
string.rfind(str, start=0, end=len(string)) | 类似于 find(),不过是从右边开始查找 |
string.index(str, start=0, end=len(string)) | 跟 find() 方法类似,不过如果 str 不在 string 会报错 |
string.rindex(str, start=0, end=len(string)) | 类似于 index(),不过是从右边开始 |
string.replace(old_str, new_str, num=string.count(old)) | 把 string 中的 old_str 替换成 new_str,如果 num 指定,则替换不超过 num 次 |
方法 | 说明 |
string.capitalize() | 把字符串的第一个字符大写 |
string.title() | 把字符串的每个单词首字母大写 |
string.lower() | 转换 string 中所有大写字符为小写 |
string.upper() | 转换 string 中的小写字母为大写 |
string.swapcase() | 翻转 string 中的大小写 |
方法 | 说明 |
string.ljust(width) | 返回一个原字符串左对齐,并使用空格填充至长度 width 的新字符串 |
string.rjust(width) | 返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串 |
string.center(width) | 返回一个原字符串居中,并使用空格填充至长度 width 的新字符串 |
方法 | 说明 |
string.lstrip() | 截掉 string 左边(开始)的空白字符 |
string.rstrip() | 截掉 string 右边(末尾)的空白字符 |
string.strip() | 截掉 string 左右两边的空白字符 |
方法 | 说明 |
string.partition(str) | 把字符串 string 分成一个 3 元素的元组 (str前面, str, str后面) |
string.rpartition(str) | 类似于 partition() 方法,不过是从右边开始查找 |
string.split(str=“”, num) | 以 str 为分隔符拆分 string,如果 num 有指定值,则仅分隔 num + 1 个子字符串,str 默认包含 ‘\r’, ‘\t’, ‘\n’ 和空格 |
string.splitlines() | 按照行(‘\r’, ‘\n’, ‘\r\n’)分隔,返回一个包含各行作为元素的列表 |
string.join(seq) | 以 string 作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 |

字符串[开始索引:结束索引:步长]
注意:
[开始索引, 结束索引) =>开始索引 >= 范围 < 结束索引
起始 位开始,到 结束位的前一位结束(不包含结束位本身)1,如果连续切片,数字和冒号都可以省略索引的顺序和倒序:
演练需求:
末尾 的字符串开始 ~ 5 位置 的字符串末尾 - 1 的字符串答案:
num_str = "0123456789"
# 1. 截取从 2 ~ 5 位置 的字符串
print(num_str[2:6])
# 2. 截取从 2 ~ `末尾` 的字符串
print(num_str[2:])
# 3. 截取从 `开始` ~ 5 位置 的字符串
print(num_str[:6])
# 4. 截取完整的字符串
print(num_str[:])
# 5. 从开始位置,每隔一个字符截取字符串
print(num_str[::2])
# 6. 从索引 1 开始,每隔一个取一个
print(num_str[1::2])
# 倒序切片
# -1 表示倒数第一个字符
print(num_str[-1])
# 7. 截取从 2 ~ `末尾 - 1` 的字符串
print(num_str[2:-1])
# 8. 截取字符串末尾两个字符
print(num_str[-2:])
# 9. 字符串的逆序(面试题)
print(num_str[::-1])方法一:使用占位符
字符串格式化输出 是按照一种既定格式给字符串填空的方式,以便我们更加方便地写入字符串。
例如:
def print_intro(name, age, city):
intro = '我叫%s,今年 %d 岁,来自%s。' % (name, age, city)
print(intro)
print_intro('小贝', 18, '南京')
# 输出:我叫小贝,今年 18 岁,来自南京。字符串格式化输出的语法规则:

% 运算符左边是要格式化的字符串,右边是一个元组。如果只有一个占位符,可以将元组里的元素拿出来,如:‘我叫%s’ % ‘小贝’。我们通过 %s、%d 这样的占位符在字符串中“占位”,Python 会将 % 右边的内容会按顺序替换掉对应的占位符,一一填空。每个占位符都有特定的含义,我们来看一下常见的占位符:
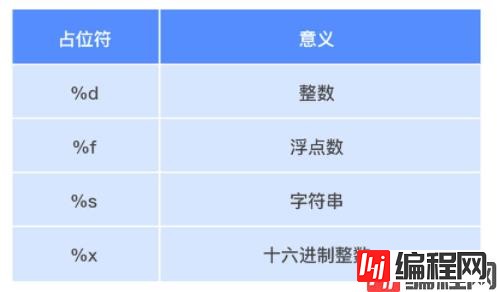
提示:如果你不太确定应该用什么占位符,%s 是万能的,它会把任何数据类型转换为字符串。
方法二:format()
例如:
'我叫{},今年 {} 岁,来自{}'.format('小贝', 18, '南京')
# 我叫小贝,今年 18 岁,来自南京
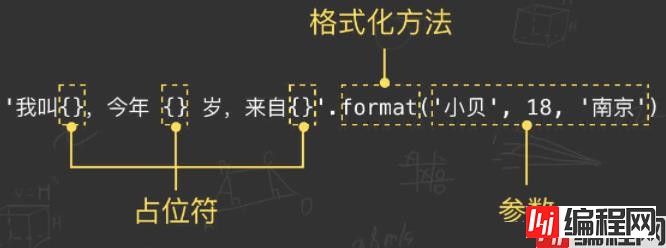
从上面的例子可以看到,format() 方法使用 {} 作为占位符,然后按照参数顺序替换对应的占位符。
我们还可以给占位符编号:
'我叫{0},今年 {1} 岁,来自{2}'.format('小贝', 18, '南京')
# 我叫小贝,今年 18 岁,来自南京
# 调整编号顺序
'我叫{2},今年 {1} 岁,来自{0}'.format('南京', 18, '小贝')
# 我叫小贝,今年 18 岁,来自南京
# 重复编号
'我叫{0},{0}今年 {1} 岁,来自{2}'.format('小贝', 18, '南京')
# 我叫小贝,小贝今年 18 岁,来自南京我们还可以给占位符命名:
'我叫{name},今年 {age} 岁,来自{city}'.format(name = '小贝', age = 18, city = '南京')
# 我叫小贝,今年 18 岁,来自南京
# 命名后参数顺序不再重要
'我叫{name},今年 {age} 岁,来自{city}'.format(age = 18, city = '南京', name = '小贝')
# 我叫小贝,今年 18 岁,来自南京Python 包含了以下内置函数:
函数 | 描述 | 备注 |
len(item) | 计算容器中元素个数 | |
del(item) | 删除变量 | del 有两种方式 |
max(item) | 返回容器中元素最大值 | 如果是字典,只针对 key 比较 |
min(item) | 返回容器中元素最小值 | 如果是字典,只针对 key 比较 |
cmp(item1, item2) | 比较两个值,-1 小于/0 相等/1 大于 | Python 3.x 取消了 cmp 函数 |
注意:字符串比较符合以下规则: “0” < “A” < “a”
| 描述 | Python 表达式 | 结果 | 支持的数据类型 |
| :—: | — | — | — | — |
| 切片 | “0123456789”[::-2] | “97531” | 字符串、列表、元组 |
运算符 | Python 表达式 | 结果 | 描述 | 支持的数据类型 |
+ | [1, 2] + [3, 4] | [1, 2, 3, 4] | 合并 | 字符串、列表、元组 |
* | [“Hi!”] * 4 | [‘Hi!’, ‘Hi!’, ‘Hi!’, ‘Hi!’] | 重复 | 字符串、列表、元组 |
in | 3 in (1, 2, 3) | True | 元素是否存在 | 字符串、列表、元组、字典 |
not in | 4 not in (1, 2, 3) | True | 元素是否不存在 | 字符串、列表、元组、字典 |
> >= == < <= | (1, 2, 3) < (2, 2, 3) | True | 元素比较 | 字符串、列表、元组 |
注意:
in 在对字典操作时,判断的是字典的键in 和not in 被称为成员运算符成员运算符:
成员运算符用于 测试 序列中是否包含指定的 成员
运算符 | 描述 | 实例 |
in | 如果在指定的序列中找到值返回 True,否则返回 False |
|
not in | 如果在指定的序列中没有找到值返回 True,否则返回 False |
|
注意:在对 字典 操作时,判断的是 字典的键
在Python 中完整的for 循环 的语法如下:
for 变量 in 集合:
循环体代码
else:
没有通过 break应用场景:
students = [
{"name": "阿土",
"age": 20,
"gender": True,
"height": 1.7,
"weight": 75.0},
{"name": "小美",
"age": 19,
"gender": False,
"height": 1.6,
"weight": 45.0},
]
find_name = "阿土"
for stu_dict in students:
print(stu_dict)
# 判断当前遍历的字典中姓名是否为find_name
if stu_dict["name"] == find_name:
print("找到了")
# 如果已经找到,直接退出循环,就不需要再对后续的数据进行比较
break
else:
print("没有找到")
print("循环结束")到此这篇关于Python常用数据结构和公共方法技巧总结的文章就介绍到这了,更多相关Python数据结构内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: Python常用数据结构和公共方法技巧总结
本文链接: https://lsjlt.com/news/119929.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0