Python 官方文档:入门教程 => 点击学习
目录楔子同时导入多个 sheet覆盖一个 sheet楔子 估计有不少小伙伴在将 DataFrame 导入到 excel 的时候,都遇到过下面这种尴尬的情况: 想将多个 DataFra
估计有不少小伙伴在将 DataFrame 导入到 excel 的时候,都遇到过下面这种尴尬的情况:
那么下面就来看看如何解决这些问题。
如果想导入多个 sheet,那么肯定不能使用原来 to_excel("文件名") 的方式,那样只会保留最后一个 sheet。我们应该使用类 ExcelWriter 实现:
import pandas as pd
df1 = pd.DataFrame({"a": [1, 2], "b": [3, 4]})
df2 = pd.DataFrame({"a": [2, 3], "b": [4, 5]})
df3 = pd.DataFrame({"a": [3, 4], "b": [5, 6]})
# 调用pd.ExcelWriter, 需要指定mode="a", engine="openpyxl"
# 注意: 将mode设置为"a"表示追加, 但是它要求文件必须存在, 否则报错
"""
writer = pd.ExcelWriter("test.xlsx", mode="a", engine="openpyxl")
"""
# 因此我们需要生成这个文件,此时顺便将第一个 DataFrame 导进去
df1.to_excel("test.xlsx", index=False, sheet_name="a")
# 然后再实例化ExcelWriter
writer = pd.ExcelWriter("test.xlsx", mode="a", engine="openpyxl")
# 接下来还是调用to_excel, 但是第一个参数不再是文件名, 而是上面的writer
# 将剩下的两个DataFrame写进去
df2.to_excel(writer, index=False, sheet_name="b")
df3.to_excel(writer, index=False, sheet_name="c")
# 保存并关闭writer, 写入磁盘
writer.save()
writer.close()执行代码,然后打开文件看一下。
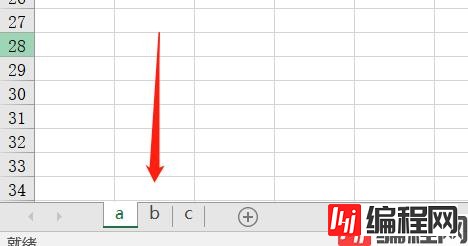
此时我们看到结果是没有问题的,当然向已存在的 Excel 文件追加 sheet 也是同理。
向 Excel 文件同时写入多个sheet,以及追加sheet,我们已经知道该怎么做了,然后是覆盖 sheet。首先我们覆盖 sheet 的时候还要保证其它 sheet 不受影响,所以 mode 仍然要设置为追加模式。
下面问题来了,我们上面的 Excel 文件有 "a"、"b"、"c" 三个 sheet,假设我们想将 "b" 这个 sheet 覆盖掉,应该怎么做呢?可能有人认为,在追加的时候还指定 sheet_name="b" 不就行了,然鹅答案是不行的。
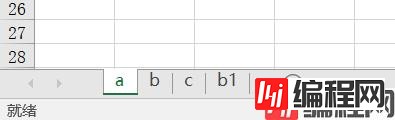
我们看到如果已有同名 sheet,那么不会覆盖,还是创建一个新的 sheet,并自动在结尾处加一个 1。如果我们在此基础上再写入 "b" 这个 sheet 的话,那么又会多出一个名为 "b2" 的sheet。所以最好的办法是,在导入之前先将 sheet 删除。
import pandas as pd
writer = pd.ExcelWriter("test.xlsx", mode="a",
engine="openpyxl")
wb = writer.book
# pandas操作Excel底层也是依赖于其它的模块, 比如xlrd、openpyxl
# 所以这里的 wb = writer.book 就相当于
"""
from openpyxl import load_workbook
wb = load_workbook("test.xlsx")
"""
# 查看已存在的所有的sheet, 总共是5个
# 其中 "b1"和"b2" 是自动创建的
print(wb.sheetnames) # ['a', 'b', 'c', 'b1', 'b2']
# 下面我们来删除sheet
wb.remove(wb["b1"])
wb.remove(wb["b2"])
wb.remove(wb["b"])
df = pd.DataFrame({"name": ["古明地觉", "古明地恋"]})
# 我们将 b 这个 sheet 给删除了
# 所以再导入 "b" 的时候就不会出现 "b3" 了
# 当然 "b1" 和 "b2" 也顺便被我们给删掉了
df.to_excel(writer, index=True, sheet_name="b")
writer.save()
writer.close()我们看到 "b1"、"b2" 两个 sheet 就没了,当然我们删除的还有 "b" 这个sheet,只不过又重新创建了,当然数据也是我们创建的新数据。
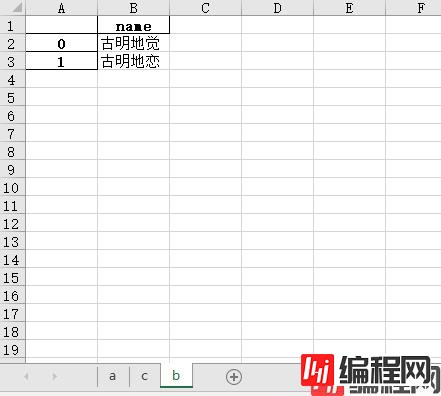
另外可能有人发现多个 sheet 的顺序不再是原来的 "a"、"b"、"c",这是因为在删除 "b" 之后,"a" 和 "c" 就靠在一起了,所以新写入 "b" 的时候就排在 "c" 的后面了,当然个人觉得这没有什么太大影响。
以上就是解决Pandas生成Excel时的sheet问题的方法总结的详细内容,更多关于Pandas生成Excel sheet问题的资料请关注编程网其它相关文章!
--结束END--
本文标题: 解决Pandas生成Excel时的sheet问题的方法总结
本文链接: https://lsjlt.com/news/119865.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0