Python 官方文档:入门教程 => 点击学习
目录代理ip原理输入网址后发生了什么呢?代理ip做了什么呢? 为什么要用代理呢?爬虫代码中使用代理ip检验代理ip是否生效 未生效问题排查1.请求协议不匹配2.代
主要内容:代理ip使用原理,怎么在自己的爬虫里设置代理ip,怎么知道代理ip是否生效,没生效的话哪里出了问题,个人使用的代理ip(付费)。
1.浏览器获取域名
2.通过DNS协议获取域名对应服务器的ip地址
3.浏览器和对应的服务器通过三次握手建立tcp连接
4.浏览器通过Http协议向服务器发送数据请求
5.服务器将查询结果返回给浏览器
6.四次挥手释放TCP连接
7.浏览器渲染结果
其中涉及到了:
应用层:HTTP和DNS
传输层:TCP UDP
网络层:IP ICMP ARP
简单来说,就是:
原本你的访问
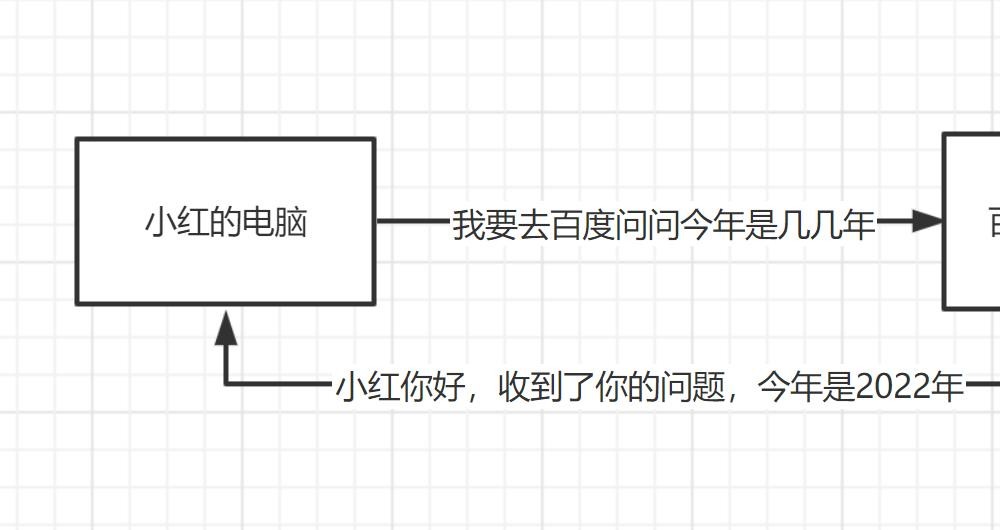
使用代理后你的访问
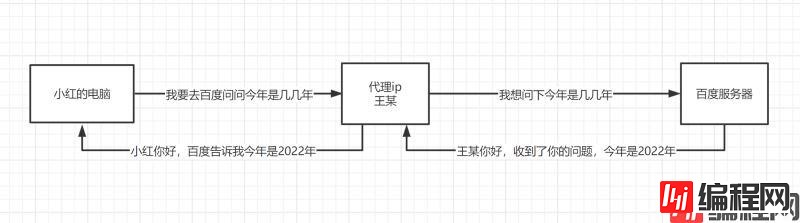
因为我们在做爬虫的过程中经常会遇到这样的情况,最初爬虫正常运行,正常抓取数据,一切看起来都是那么美好,然而一杯茶的功夫可能就会出现错误,比如403 Forbidden,这时候打开网页一看,可能会看到“您的IP访问频率太高”这样的提示。出现这种现象的原因是网站采取了一些反爬虫措施。比如,服务器会检测某个IP在单位时间内的请求次数,如果超过了这个阈值,就会直接拒绝服务,返回一些错误信息,这种情况可以称为封IP。而代理ip就避免了这个问题:

就像是请求时伪装头一样,伪装ip,注意是 { }
proxies = {
'https':'117.29.228.43:64257',
'http':'117.29.228.43:64257'
}
requests.get(url, headers=head, proxies=proxies, timeout=3) #proxies我们访问一个网站,这个网站会返回我们的ip地址:
print(requests.get('http://httpbin.org/ip', proxies=proxies, timeout=3).text)我们看一下我使用了四个不同的代理ip,全部生效了,

如果你返回的还是本机地址,99%试一下两种情况之一:
简单来说就是,如果你请求的是http,就要用http的协议,如果是https,就要用https的协议。
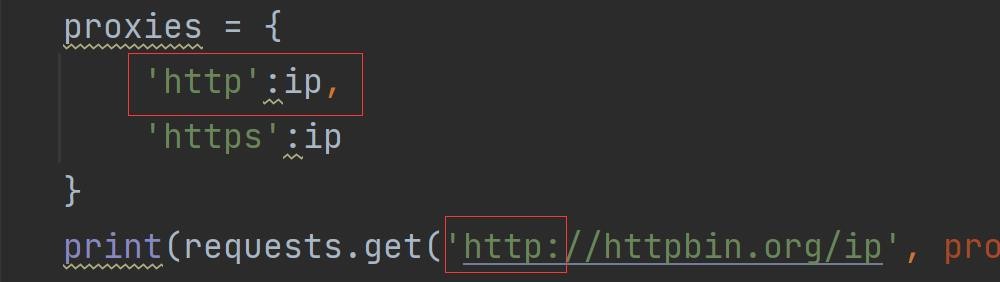
如果我请求是http ,但只有https,就会使用本机ip。
便宜没好货,好货不便宜。如果确实大规模爬虫是必须的话,还是买代理ip比较好,网上广告满天飞的某些代理实际性价比有些低了,自己常用的就不分享了,总是被当成广告,推荐一些其他的比如:
1、IPidea
2、StORMproxies
3、YourPrivateProxy
4、GeoSurf
当然还有大家熟知的快代理,西刺等等,都有一些免费代理可供使用。
到此这篇关于python爬虫之代理ip正确使用方法的文章就介绍到这了,更多相关python爬虫代理ip内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: python爬虫之代理ip正确使用方法实例
本文链接: https://lsjlt.com/news/119226.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0