大家好,这一期阿彬给大家分享scrapy爬虫框架与本地Mysql的使用。今天阿彬爬取的网页是虎扑体育网。 (1)打开虎扑体育网,分析一下网页的数据,使用xpath定位元素。 &nb
大家好,这一期阿彬给大家分享scrapy爬虫框架与本地Mysql的使用。今天阿彬爬取的网页是虎扑体育网。
(1)打开虎扑体育网,分析一下网页的数据,使用xpath定位元素。

(2)在第一部分析网页之后就开始创建一个scrapy爬虫工程,在终端执行以下命令:
“scrapy startproject huty(注:‘hpty’是爬虫项目名称)”,得到了下图所示的工程包:

(3)进入到“hpty/hpty/spiders”目录下创建一个爬虫文件叫‘“sww”,在终端执行以下命令: “scrapy genspider sww” (4)在前两步做好之后,对整个爬虫工程相关的爬虫文件进行编辑。 1、setting文件的编辑:
把君子协议原本是True改为False。
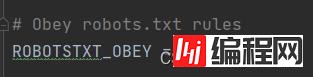
再把这行原本被注释掉的代码把它打开。

2、对item文件进行编辑,这个文件是用来定义数据类型,代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class HptyItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
球员 = scrapy.Field()
球队 = scrapy.Field()
排名 = scrapy.Field()
场均得分 = scrapy.Field()
命中率 = scrapy.Field()
三分命中率 = scrapy.Field()
罚球命中率 = scrapy.Field()3、对最重要的爬虫文件进行编辑(即“hpty”文件),代码如下:
import scrapy
from ..items import HptyItem
class SwwSpider(scrapy.Spider):
name = 'sww'
allowed_domains = ['Https://nba.hupu.com/stats/players']
start_urls = ['https://nba.hupu.com/stats/players']
def parse(self, response):
whh = response.xpath('//tbody/tr[not(@class)]')
for i in whh:
排名 = i.xpath(
'./td[1]/text()').extract()# 排名
球员 = i.xpath(
'./td[2]/a/text()').extract() # 球员
球队 = i.xpath(
'./td[3]/a/text()').extract() # 球队
场均得分 = i.xpath(
'./td[4]/text()').extract() # 得分
命中率 = i.xpath(
'./td[6]/text()').extract() # 命中率
三分命中率 = i.xpath(
'./td[8]/text()').extract() # 三分命中率
罚球命中率 = i.xpath(
'./td[10]/text()').extract() # 罚球命中率
data = HptyItem(球员=球员, 球队=球队, 排名=排名, 场均得分=场均得分, 命中率=命中率, 三分命中率=三分命中率, 罚球命中率=罚球命中率)
yield data4、对pipelines文件进行编辑,代码如下:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from cursor import cursor
from itemadapter import ItemAdapter
import pymysql
class HptyPipeline:
def process_item(self, item, spider):
db = pymysql.connect(host="Localhost", user="root", passwd="root", db="sww", charset="utf8")
cursor = db.cursor()
球员 = item["球员"][0]
球队 = item["球队"][0]
排名 = item["排名"][0]
场均得分 = item["场均得分"][0]
命中率 = item["命中率"]
三分命中率 = item["三分命中率"][0]
罚球命中率 = item["罚球命中率"][0]
# 三分命中率 = item["三分命中率"][0].strip('%')
# 罚球命中率 = item["罚球命中率"][0].strip('%')
cursor.execute(
'INSERT INTO nba(球员,球队,排名,场均得分,命中率,三分命中率,罚球命中率) VALUES (%s,%s,%s,%s,%s,%s,%s)',
(球员, 球队, 排名, 场均得分, 命中率, 三分命中率, 罚球命中率)
)
# 对事务操作进行提交
db.commit()
# 关闭游标
cursor.close()
db.close()
return item(5)在scrapy框架设计好了之后,先到mysql创建一个名为“sww”的数据库,在该数据库下创建名为“nba”的数据表,代码如下: 1、创建数据库
create database sww;2、创建数据表
create table nba (球员 char(20),球队 char(10),排名 char(10),场均得分 char(25),命中率 char(20),三分命中率 char(20),罚球命中率 char(20));3、通过创建数据库和数据表可以看到该表的结构:

(6)在mysql创建数据表之后,再次回到终端,输入如下命令:“scrapy crawl sww”,得到的结果
到此这篇关于使用Scrapy框架爬取网页并保存到Mysql的实现的文章就介绍到这了,更多相关Scrapy爬取网页并保存内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: 使用Scrapy框架爬取网页并保存到Mysql的实现
本文链接: https://lsjlt.com/news/119217.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0