Python 官方文档:入门教程 => 点击学习
目录前言创建索引pd.Indexpd.IntervalIndexpd.CateGoricalIndexpd.DatetimeIndexpd.PeriodIndexpd.Timedel
本文主要是介绍pandas中行和列索引的4个函数操作:
快速回顾下Pandas创建索引的常见方法:
In [1]:
import pandas as pd
import numpy as np
In [2]:
# 指定类型和名称
s1 = pd.Index([1,2,3,4,5,6,7],
dtype="int",
name="Peter")
s1
Out[2]:
Int64Index([1, 2, 3, 4, 5, 6, 7], dtype='int64', name='Peter')
新的间隔索引 IntervalIndex 通常使用 interval_range()函数来进行构造,它使用的是数据或者数值区间,基本用法:
In [3]:
s2 = pd.interval_range(start=0, end=6, closed="left")
s2
Out[3]:
IntervalIndex([[0, 1), [1, 2), [2, 3), [3, 4), [4, 5), [5, 6)],
closed='left',
dtype='interval[int64]')
In [4]:
s3 = pd.CategoricalIndex(
# 待排序的数据
["S","M","L","XS","M","L","S","M","L","XL"],
# 指定分类顺序
categories=["XS","S","M","L","XL"],
# 排需
ordered=True,
# 索引名字
name="category"
)
s3
Out[4]:
CategoricalIndex(['S', 'M', 'L', 'XS', 'M', 'L', 'S', 'M', 'L', 'XL'],
categories=['XS', 'S', 'M', 'L', 'XL'],
ordered=True,
name='category',
dtype='category')
以时间和日期作为索引,通过date_range函数来生成,具体例子为:
In [5]:
# 日期作为索引,D代表天
s4 = pd.date_range("2022-01-01",periods=6, freq="D")
s4
Out[5]:
DatetimeIndex(['2022-01-01', '2022-01-02', '2022-01-03',
'2022-01-04','2022-01-05', '2022-01-06'],
dtype='datetime64[ns]', freq='D')
pd.PeriodIndex是一个专门针对周期性数据的索引,方便针对具有一定周期的数据进行处理,具体用法如下:
In [6]:
s5 = pd.PeriodIndex(['2022-01-01', '2022-01-02',
'2022-01-03', '2022-01-04'],
freq = '2H')
s5
Out[6]:
PeriodIndex(['2022-01-01 00:00', '2022-01-02 00:00',
'2022-01-03 00:00','2022-01-04 00:00'],
dtype='period[2H]', freq='2H')
In [7]:
data = pd.timedelta_range(start='1 day', end='3 days', freq='6H')
data
Out[7]:
TimedeltaIndex(['1 days 00:00:00', '1 days 06:00:00', '1 days 12:00:00',
'1 days 18:00:00', '2 days 00:00:00', '2 days 06:00:00',
'2 days 12:00:00', '2 days 18:00:00', '3 days 00:00:00'],
dtype='timedelta64[ns]', freq='6H')
In [8]:
s6 = pd.TimedeltaIndex(data)
s6
Out[8]:
TimedeltaIndex(['1 days 00:00:00', '1 days 06:00:00', '1 days 12:00:00',
'1 days 18:00:00', '2 days 00:00:00', '2 days 06:00:00',
'2 days 12:00:00', '2 days 18:00:00', '3 days 00:00:00'],
dtype='timedelta64[ns]', freq='6H')
下面通过一份 简单的数据来讲解4个函数的使用。数据如下:
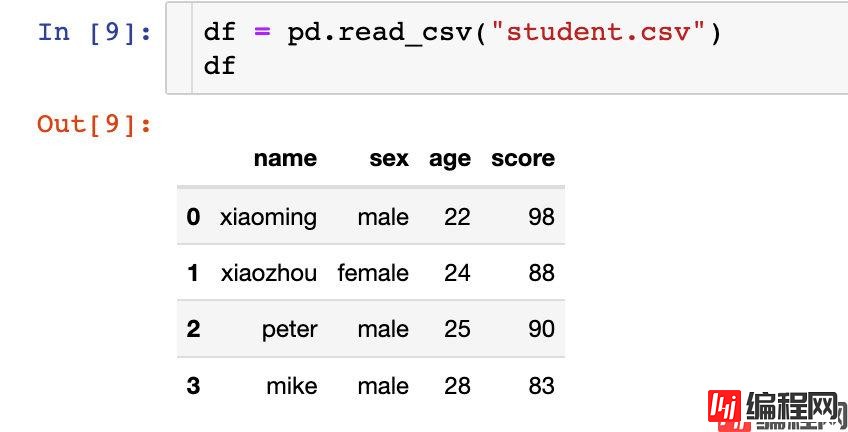
设置单层索引
In [10]:
# 设置单层索引
df1 = df.set_index("name")
df1
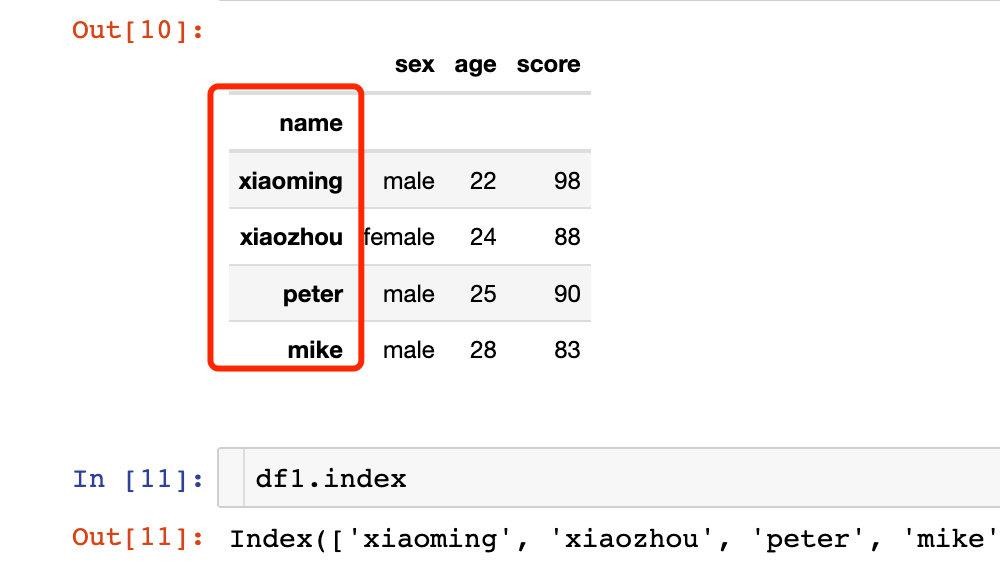
我们发现df1的索引已经变成了name字段的相关值。
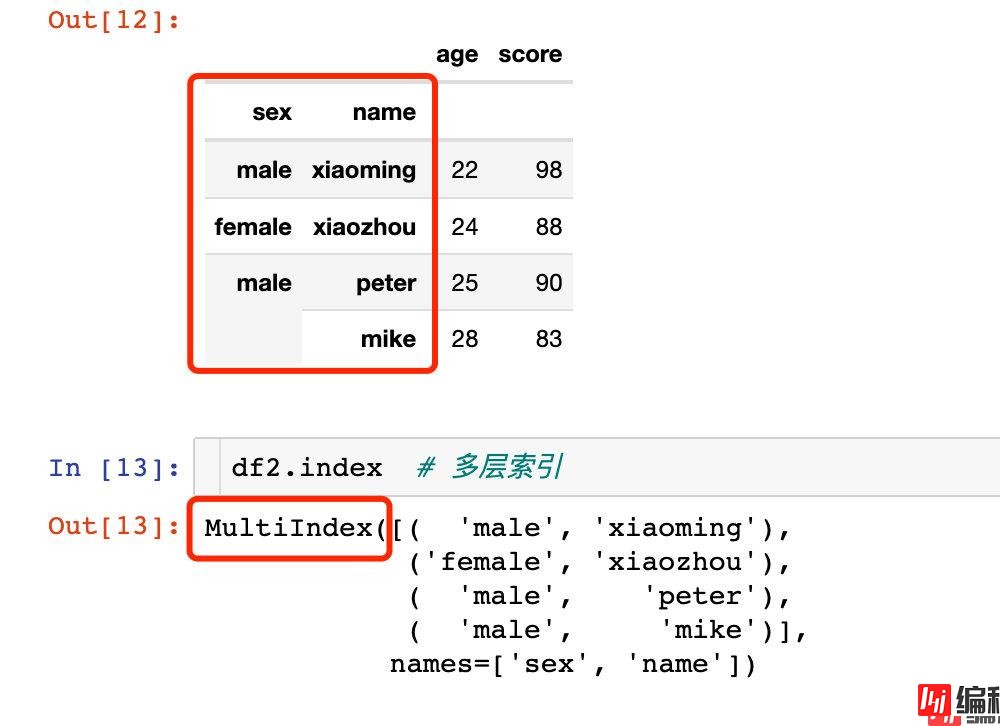
下面是设置多层索引:
# 设置两层索引
df2 = df.set_index(["sex","name"])
df2
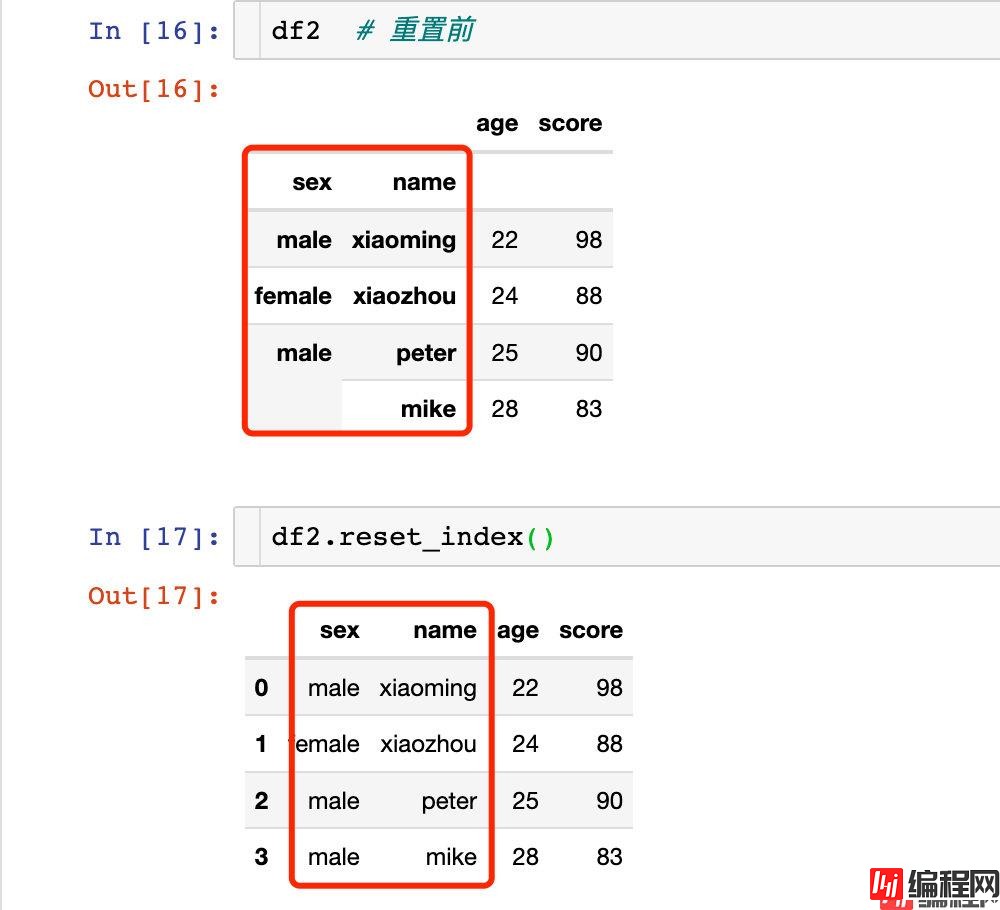
对索引的重置:

针对多层索引的重置:
多层索引直接原地修改:
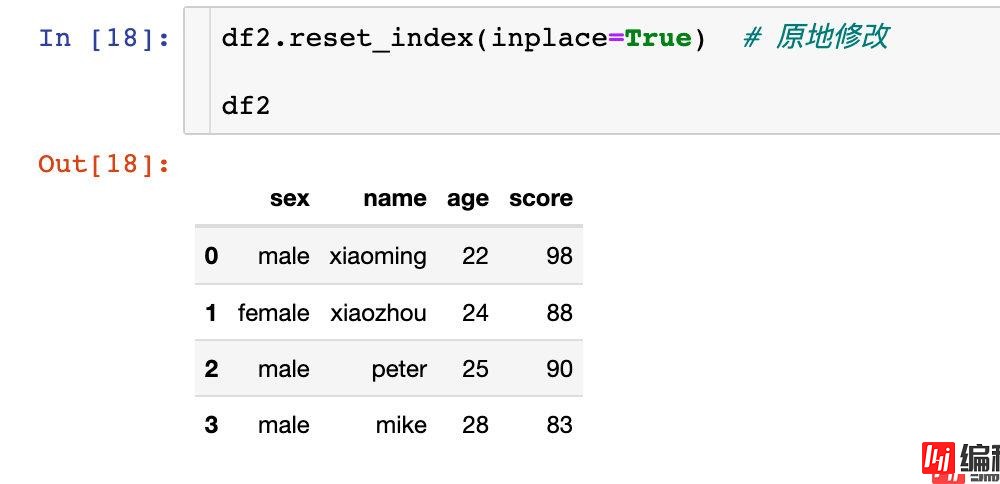
将指定的数据分配给所需要的轴axis。其中axis=0代表行方向,axis=1代表列方向。
两种不同的写法:
axis=0 等价于 axis="index"
axis=1 等价于 axis="columns"

使用 index 效果相同:
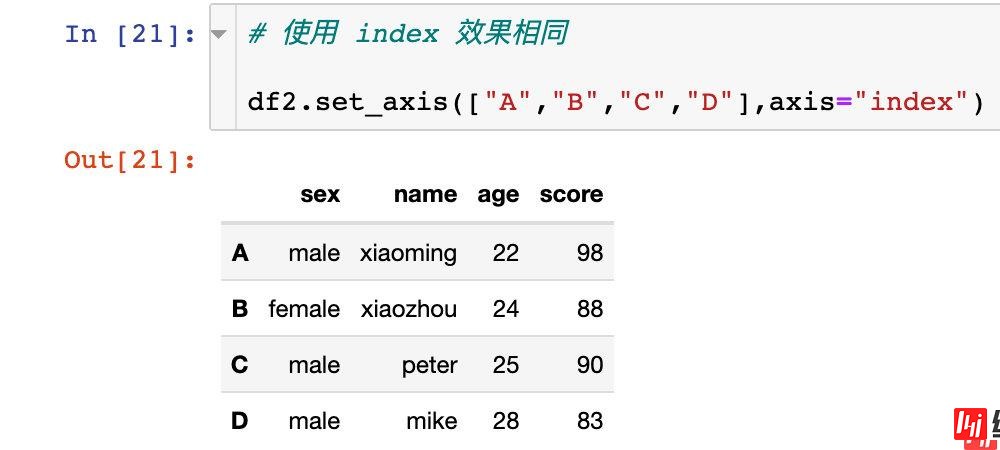
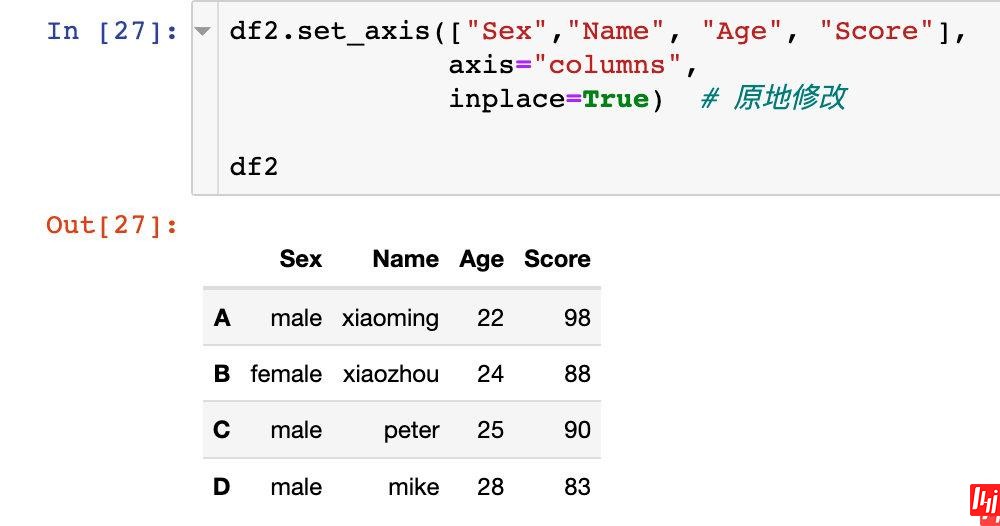
原来的df2是没有改变的。如果我们想改变生效,同样也可以直接原地修改:
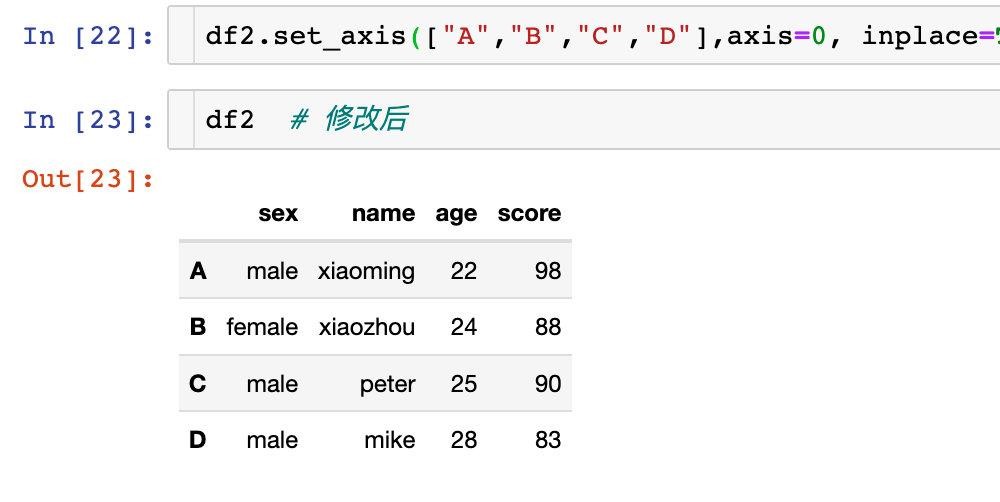
针对axis=1或者axis="columns"方向上的操作。
1、直接传入我们需要修改的新名称:
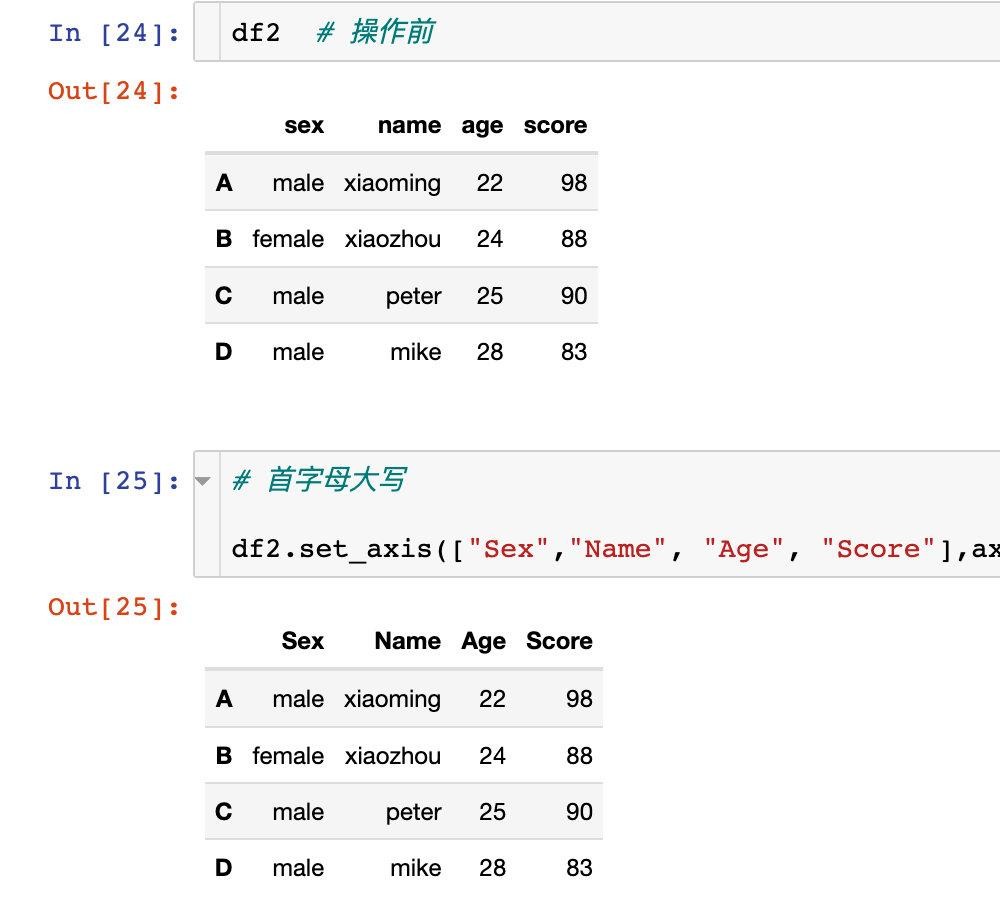
使用axis="columns"效果相同:
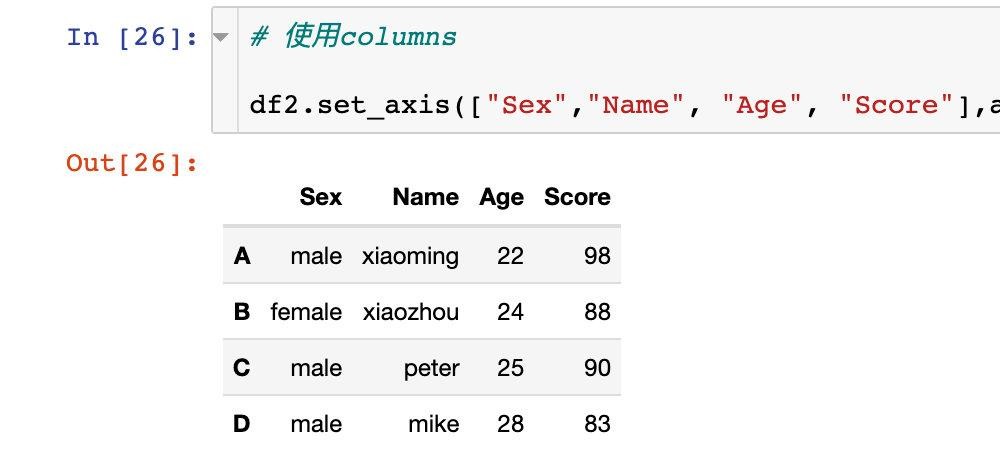
同样也可以直接原地修改:
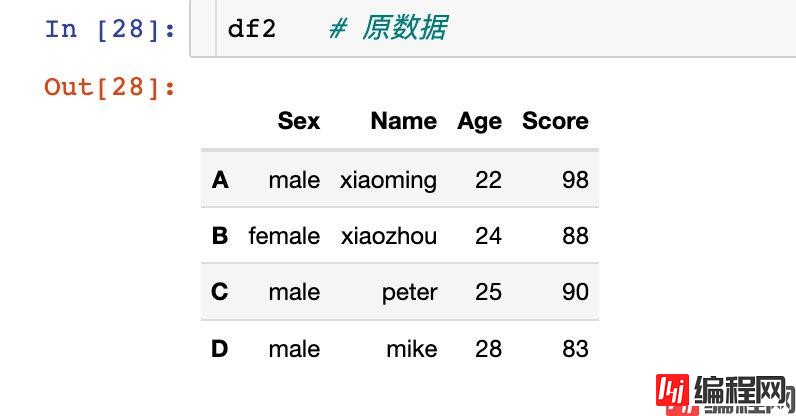
给行索引或者列索引进行重命名,假设我们的原始数据如下:
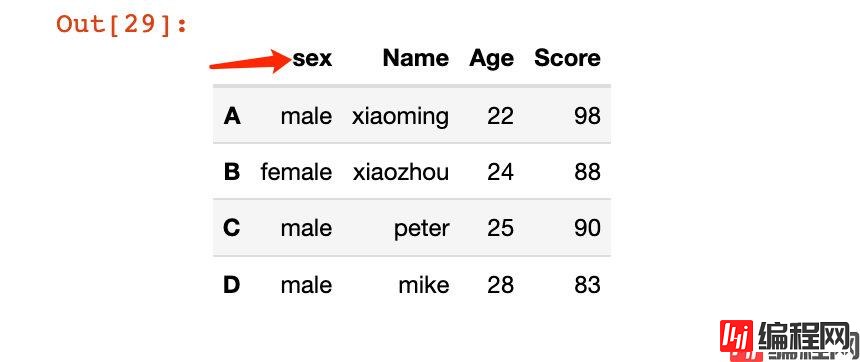
1、通过传入的一个或者多个属性的字典形式进行修改:
In [29]:
# 修改单个列索引;非原地修改
df2.rename(columns={"Sex":"sex"})
同时修改多个列属性的名称:

2、通过传入的函数进行修改:
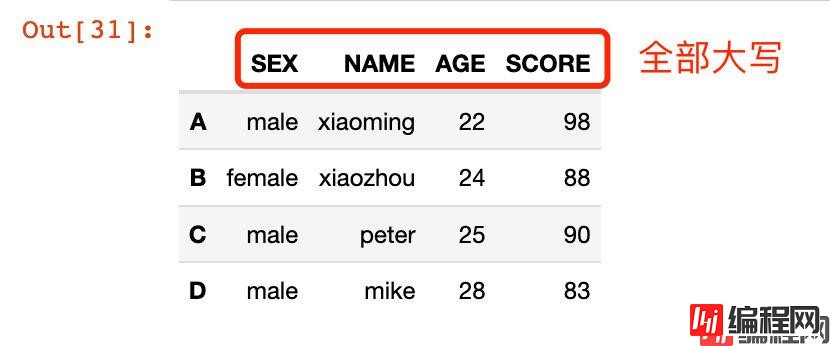
In [31]:
# 传入函数
df2.rename(str.upper, axis="columns")
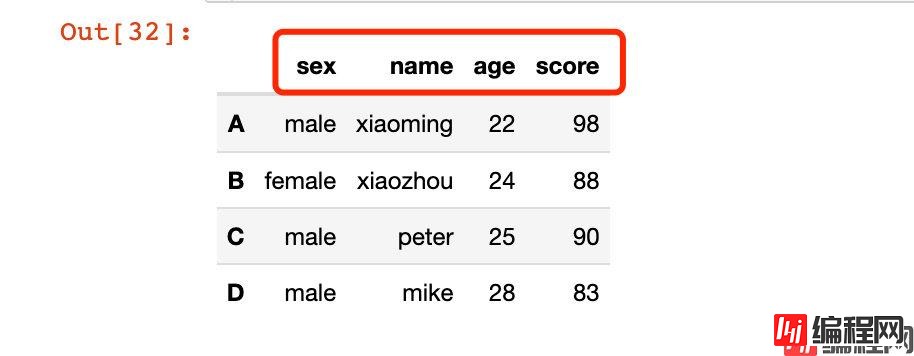
也可以使用匿名函数lambda:
# 全部变成小写
df2.rename(lambda x: x.lower(), axis="columns")
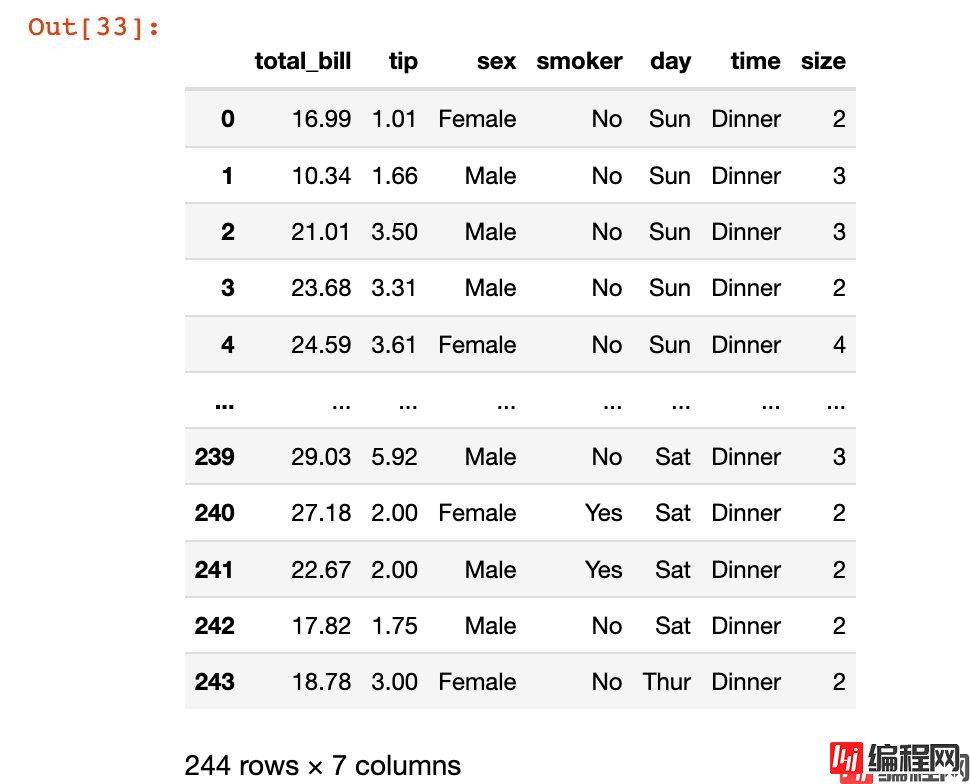
In [33]:
在这里我们使用的是可视化库plotly_express库中的自带数据集tips:
import plotly_express as px
tips = px.data.tips()
tips
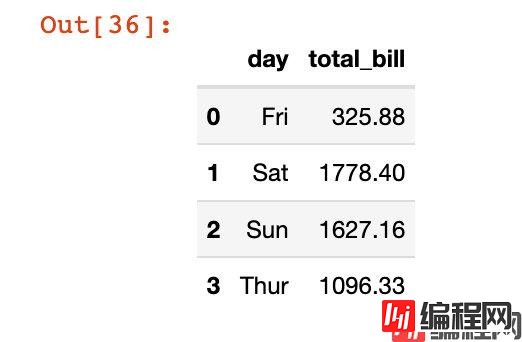
In [34]:
df3 = tips.groupby("day")["total_bill"].sum()
df3
Out[34]:
day
Fri 325.88
Sat 1778.40
Sun 1627.16
Thur 1096.33
Name: total_bill, dtype: float64
In [35]:
我们发现df3其实是一个Series型的数据:
type(df3) # Series型的数据
Out[35]:
pandas.core.series.Series
In [36]:
下面我们通过reset_index函数将其变成了DataFrame数据:
df4 = df3.reset_index()
df4
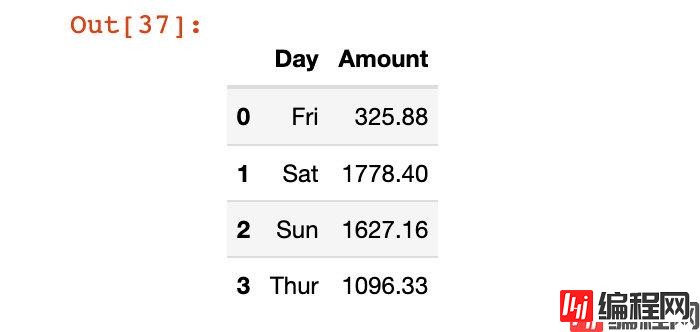
我们把列方向上的索引重新命名下:
In [37]:
# 直接原地修改
df4.rename(columns={"day":"Day", "total_bill":"Amount"},
inplace=True)
df4
In [38]:
df5 = tips.groupby(["day","sex"]).agg({"tip":"mean", "total_bill":"sum"})
df5
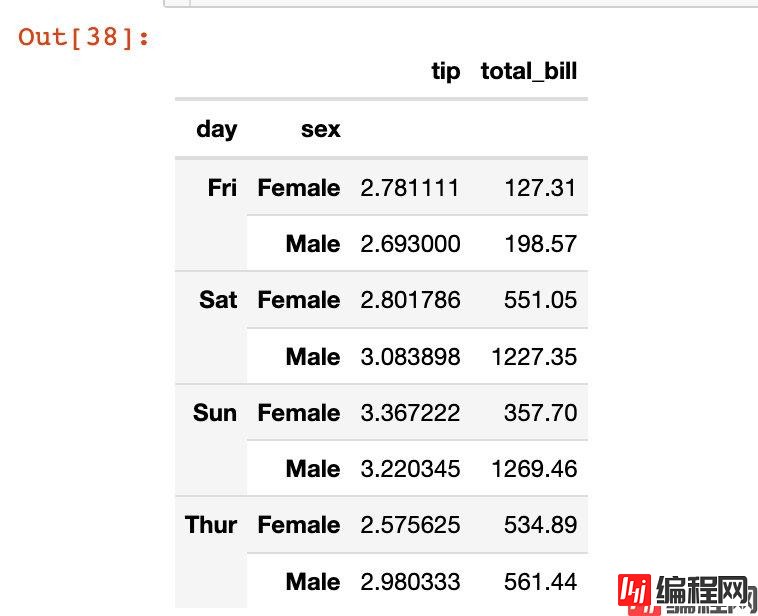
我们发现df5是df5是一个具有多层索引的数据框:
In [39]:
type(df5)
Out[39]:
pandas.core.frame.DataFrame
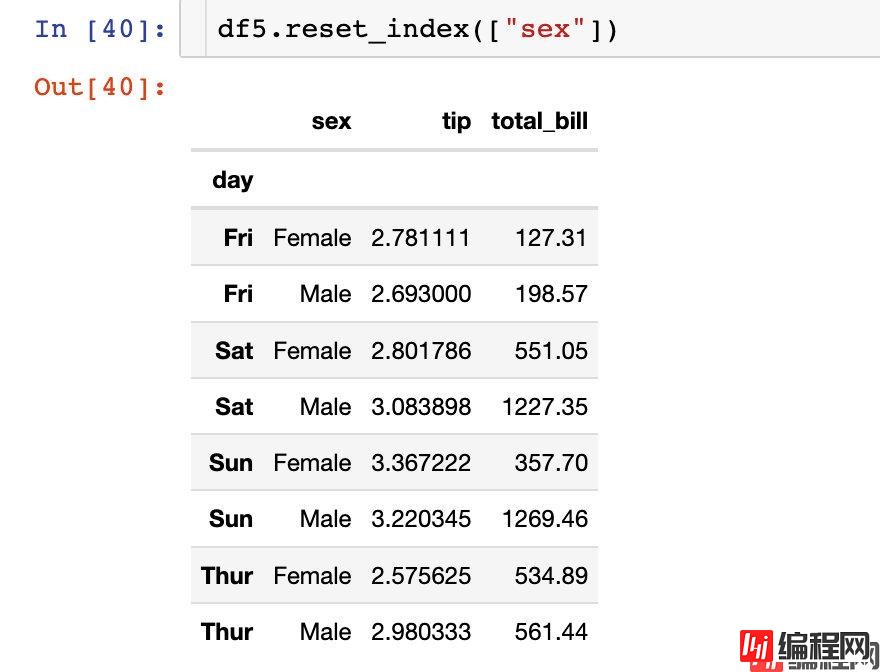
我们可以选择重置其中一个索引:
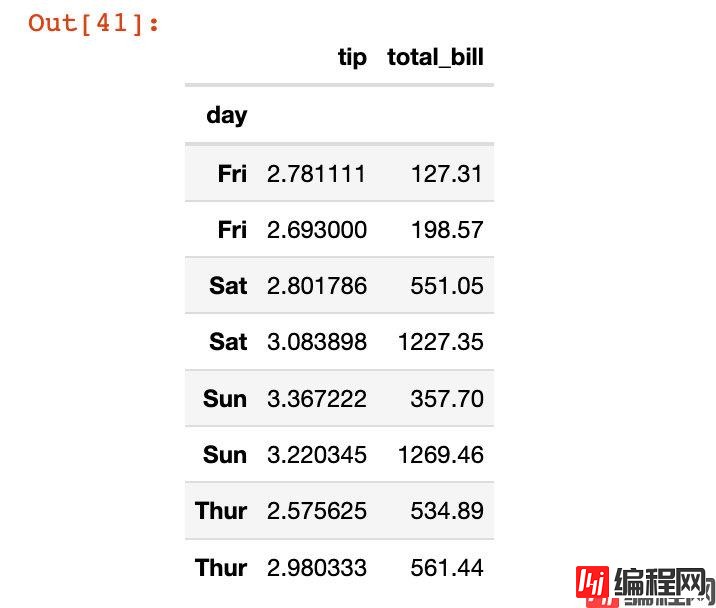
在重置索引的同时,直接丢弃原来的字段信息:下面的sex信息被删除
In [41]:
df5.reset_index(["sex"],drop=True) # 非原地修改
列方向上的索引直接原地修改:
df5.reset_index(inplace=True) # 原地修改
df5
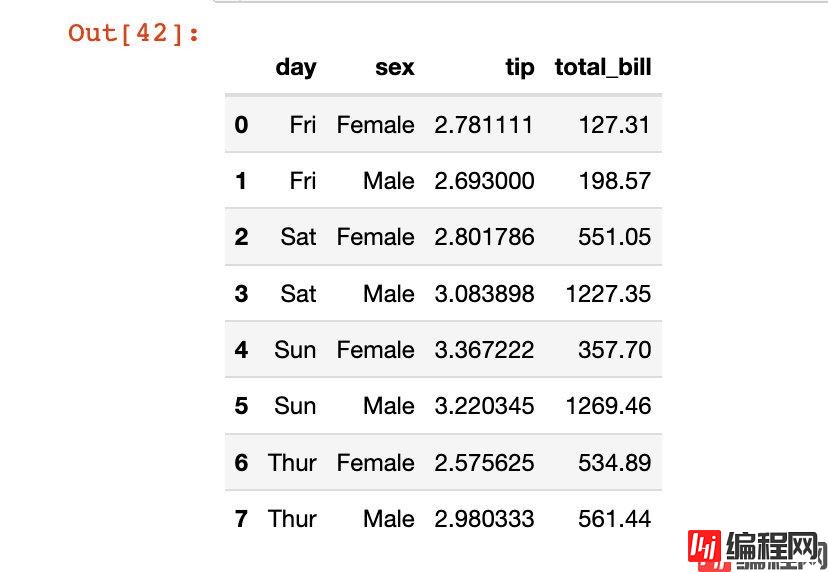
最后介绍一个笨方法来修改列索引的名称:就是将新的名称通过列表的形式全部赋值给数据框的columns属性
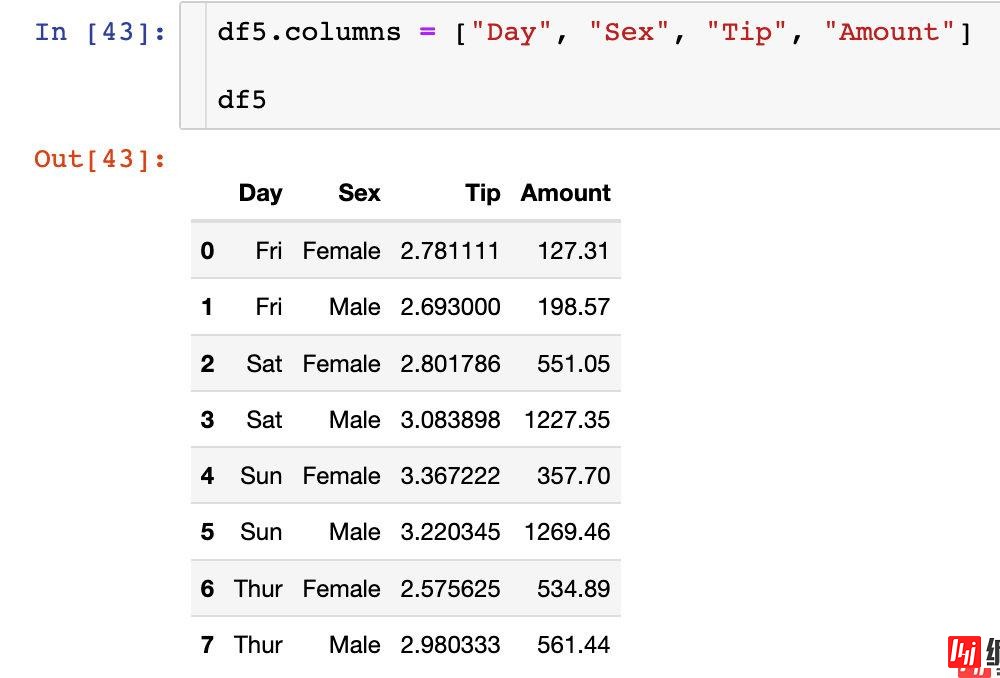
在列索引个数少的时候用起来挺方便的,如果多了不建议使用。
到此这篇关于python pandas索引的设置和修改的文章就介绍到这了,更多相关pandas索引设置和修改内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: Python pandas索引的设置和修改方法
本文链接: https://lsjlt.com/news/118841.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0