Python 官方文档:入门教程 => 点击学习
目录pandas.melt()pandas.pivot()pandas.pivot_table()pandas.crosstab()大家好,我是丁小杰! 今天和大家分享Pandas中
大家好,我是丁小杰!
今天和大家分享Pandas中四种有关数据透视的通用函数,在数据处理中遇到这类需求时,能够很好地应对。
melt函数的主要作用是将DataFrame从宽格式转换成长格式。
“pandas.melt(frame,id_vars=None, value_vars=None, var_name=None, value_name='value', col_level=None, ignore_index=True)
”
参数含义
id_vars:tuple, list, or ndarray,可选,作为标识符变量的列value_vars:tuple, list, or ndarray, 可选,透视列,如果未指定,则使用未设置为id_vars的所有列。var_name:Scalar,默认为None,使用variable作为列名value_name:标量, default ‘value’,value列的名称col_level:int or str, 可选,如果列是多层索引,melt将应用于指定级别ignore_index:bool, 默认为True,相当于从0开始重新排序。如果为False,则保留原来的索引,索引标签将出现重复。看个例子先:
import pandas as pd
df = pd.DataFrame(
{'地区': ['A', 'B', 'C'],
'2020': [80, 60, 40],
'2021': [800, 600, 400],
'2022': [8000, 6000, 4000]})

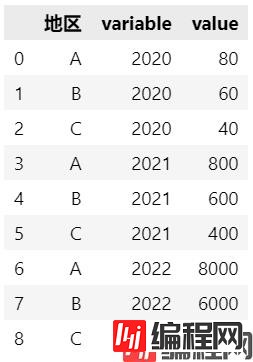
pd.melt(df,
id_vars=['地区'],
value_vars=['2020', '2021', '2022'])
设置var_name与value_name。
df = pd.melt(df,
id_vars=['地区'],
value_vars=['2020', '2021', '2022'],
var_name='年份',
value_name='销售额')

pivot函数主要用于通过索引及列值对DataFrame重构。
“pandas.pivot(data, index=None, columns=None, values=None)
”
参数含义
data:DataFrame对象index:可选,用于新DataFrame的索引columns:用于创建新DataFrame的列values:可选,用于填充新DataFrame的值用上面的结果举个例子:
df.pivot(index='年份',
columns='地区',
values='销售额')

也可以写成以下格式。
df.pivot(index='年份', columns='地区')['销售额']
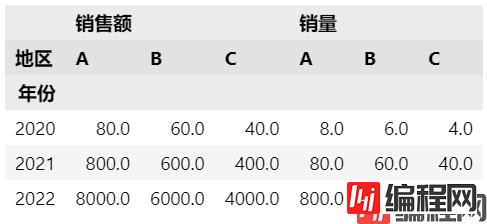
添加一个销量列,同时统计两个values,这样会使columns变成多层索引。
df['销量'] = df['销售额']/10
df.pivot(index='年份',
columns='地区',
values=['销售额', '销量'])
添加一个月份列,指定两个index。
df['月份'] = [f'{m}月' for m in range(1, 4)]*3
df.pivot(index=['年份', '月份'],
columns='地区',
values='销售额')

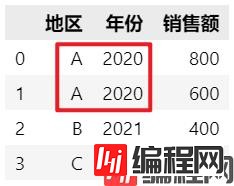
使用pivot时需要注意,当index,columns出现重复时,会导致ValueError。
df = pd.DataFrame(
{'地区': ['A', 'A', 'B', 'C'],
'年份': ['2020', '2020', '2021', '2022'],
'销售额': [800, 600, 400, 200]})
df.pivot(index='地区',
columns='年份',
values='销售额')
# ValueError
这个函数之前已经单独讲过了,详见Pandas玩转数据透视表,相比于pivot,pivot_table的灵活性更强。
crosstab函数计算两个(或多个)数组的简单交叉表。默认情况下计算元素的频率表。
“pandas.crosstab(index, columns, values=None, rownames=None, colnames=None, aggfunc=None, margins=False, margins_name='All', dropna=True, nORMalize=False)
”
看下例子:
这里默认计算频率。
import numpy as np
array_A = np.array(["one", "two", "two", "three", "three", "three"], dtype=object)
array_B = np.array(["python", "Python", "Python", "C", "C", "C"], dtype=object)
array_C = np.array(["Y", "Y", "Y", "N", "N", "N"])
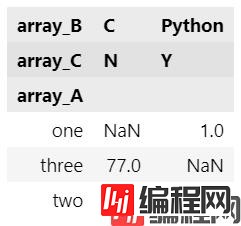
pd.crosstab(array_A,
[array_B, array_C],
rownames=['array_A'],
colnames=['array_B', 'array_C'])

新建一个values列,计算总和。
array_D = np.array([1, 4, 9, 16, 25, 36])
pd.crosstab(index=array_A,
columns=[array_B, array_C],
rownames=['array_A'],
colnames=['array_B', 'array_C'],
values=array_D,
aggfunc='sum')
到此这篇关于一文搞懂Pandas数据透视的4个函数的使用的文章就介绍到这了,更多相关Pandas数据透视内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: 一文搞懂Pandas数据透视的4个函数的使用
本文链接: https://lsjlt.com/news/118770.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0