Python 官方文档:入门教程 => 点击学习
目录1.(本年)累计2.(上年)同期累计3. 上月(完成)4. 同比(增长率)5. 环比(增长率)6. 总结统计表中常常以本年累计、上年同期(累计)、当期(例如当月)完成、上月完成为
统计表中常常以本年累计、上年同期(累计)、当期(例如当月)完成、上月完成为统计数据,并进行同比、环比分析。
如下月报统计表所示样例,本文将使用python pandas工具进行统计。
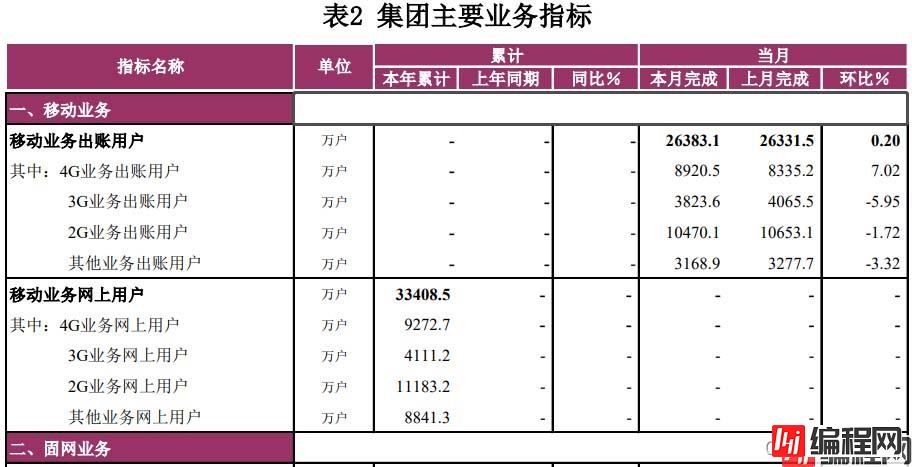
其中:
注:这里的本期是指本月完成或当月完成,上期数是指上月完成。
示例数据:
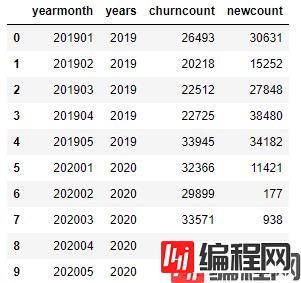
注:为了演示方便,本案例数据源仅使用2年,且每年5个月的数据。
在做统计分析开发中,按年度、按月累计某些统计数据,是比较常见的需求。对于数据来说,就是按规则逐行累加数据。
Pandas中的cumsum()函数可以实现按某时间维度累计需求。
# 取本年累计值
import pandas as pd
df = pd.read_csv('data2021.csv')
cum_columns_name = ['cum_churncount','cum_newcount']
df[cum_columns_name] = df[['years','churncount','newcount']].groupby(['years']).cumsum()注:其中分组‘years’是指年度时间维度累计。
计算结果如下:
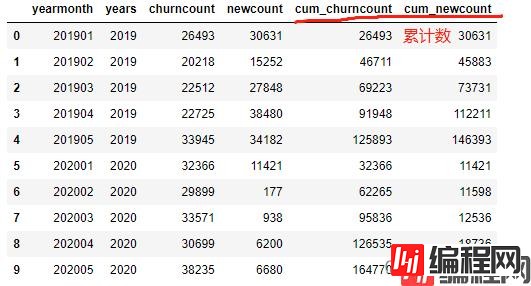
对于(上年)同期累计,将直接取上一年度累计值的同月份数据。pandas DataFrame.shift()函数可以把数据移动指定的行数。
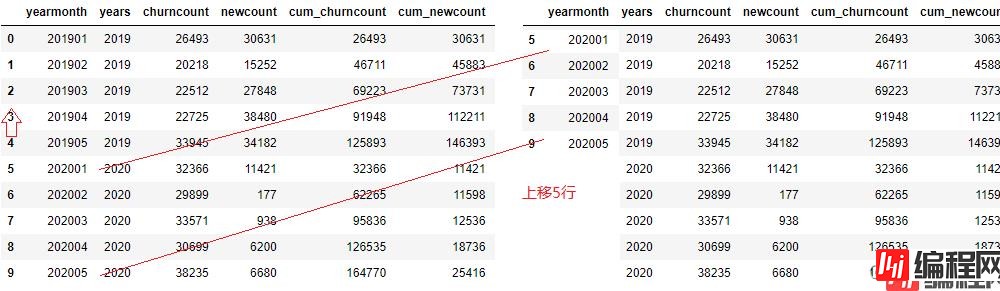
接续上列,读取同期数据。首先是把‘yearmonth’上移五行,如上图所示得到新的DataFrame,通过‘yearmonth’进行两表数据关联(左关联:左侧为原表,右侧为移动后的新表),实现去同期数据效果。
cum_columns_dict = {'cum_churncount':'cum_same_period_churncount',
'cum_newcount':'cum_same_period_newcount'}
df_cum_same_period = df[['cum_churncount','cum_newcount','yearmonth']].copy()
df_cum_same_period = df_cum_same_period.rename(columns=cum_columns_dict)
#df_cum_same_period.loc[:,'yearmonth'] = df_cum_same_period['yearmonth'].shift(-12) # 一年12个月
df_cum_same_period.loc[:,'yearmonth'] = df_cum_same_period['yearmonth'].shift(-5) # 由于只取5个月数据的原因
df = pd.merge(left=df,right=df_cum_same_period,on='yearmonth',how='left')
取上月的数据,使用pandas DataFrame.shift()函数把数据移动指定的行数。
接续上列,读取上期数据。(与取同期原理一样,略)
last_mnoth_columns_dict = {'churncount':'last_month_churncount',
'newcount':'last_month_newcount'}
df_last_month = df[['churncount','newcount','yearmonth']].copy()
df_last_month = df_last_month.rename(columns=last_mnoth_columns_dict)
df_last_month.loc[:,'yearmonth'] = df_last_month['yearmonth'].shift(-1) # 移动一行
df = pd.merge(left=df,right=df_last_month,on='yearmonth',how='left')
计算同比涉及到除法,需要剔除除数为零的数据。
df.fillna(0,inplace=True) # 空值填充为0
# 计算同比
df.loc[df['cum_same_period_churncount']!=0,'cum_churncount_rat'] = (df['cum_churncount']-df['cum_same_period_churncount'])/df['cum_same_period_churncount'] # 除数不能为零
df.loc[df['cum_same_period_newcount']!=0,'cum_newcount_rat'] = (df['cum_newcount']-df['cum_same_period_newcount'])/df['cum_same_period_newcount'] # 除数不能为零
df[['yearmonth','cum_churncount','cum_newcount','cum_same_period_churncount','cum_same_period_newcount','cum_churncount_rat','cum_newcount_rat']]
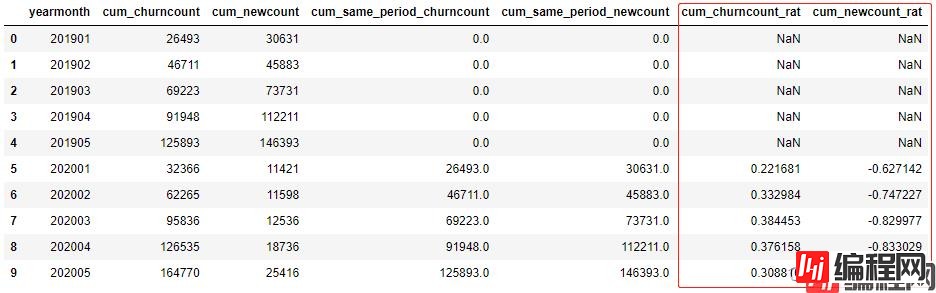
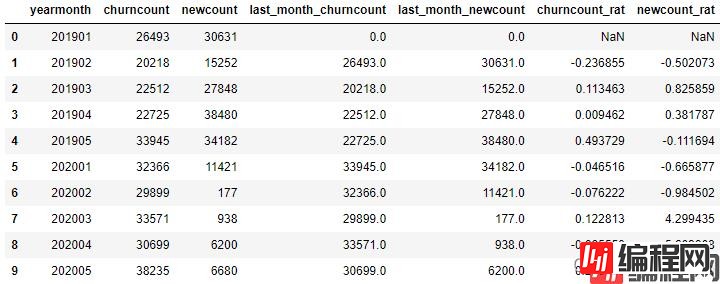
# 计算环比
df.loc[df['last_month_churncount']!=0,'churncount_rat'] = (df['churncount']-df['last_month_churncount'])/df['last_month_churncount'] # 除数不能为零
df.loc[df['last_month_newcount']!=0,'newcount_rat'] = (df['newcount']-df['last_month_newcount'])/df['last_month_newcount'] # 除数不能为零
df[['yearmonth','churncount','newcount','last_month_churncount','last_month_newcount','churncount_rat','newcount_rat']]
pandas做统计计算功能方法比较多,这里总结用到的技术有累计cumsum()函数、移动数据shift()函数、表合并关联merge()函数,以及通过loc条件修改数据。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持编程网。
--结束END--
本文标题: Pandas常用累计、同比、环比等统计方法实践过程
本文链接: https://lsjlt.com/news/118081.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0