Python 官方文档:入门教程 => 点击学习
目录匹配文本并在其上一行追加文本问题描述对比遇到的坑用正则表达式匹配文本(python经典编程案例)匹配文本并在其上一行追加文本 问题描述 Python匹配文本并在其上一行追加文本
Python匹配文本并在其上一行追加文本
test.txt
a
b
c
d
e1.读进列表后覆盖原文件
def match_then_insert(filename, match, content):
"""匹配后在该行追加
:param filename: 要操作的文件
:param match: 匹配内容
:param content: 追加内容
"""
lines = open(filename).read().splitlines()
index = lines.index(match)
lines.insert(index, content)
open(filename, mode='w').write('\n'.join(lines))
match_then_insert('test.txt', match='c', content='123')效果
a
b
123
c
d
e2.FileInput类
from fileinput import FileInput
def match_then_insert(filename, match, content):
"""匹配后在该行追加
:param filename: 要操作的文件
:param match: 匹配内容
:param content: 追加内容
"""
for line in FileInput(filename, inplace=True): # 原地过滤
if match in line:
line = content + '\n' + line
print(line, end='') # 输出重定向到原文件
match_then_insert('test.txt', match='c', content='123')3.seek
def match_then_insert(filename, match, content):
"""匹配后在该行追加
:param filename: 要操作的文件
:param match: 匹配内容
:param content: 追加内容
"""
with open(filename, mode='rb+') as f:
while True:
try:
line = f.readline() # 逐行读取
except IndexError: # 超出范围则退出
break
line_str = line.decode().splitlines()[0]
if line_str == match:
f.seek(-len(line), 1) # 光标移动到上一行
rest = f.read() # 读取余下内容
f.seek(-len(rest), 1) # 光标移动回原位置
f.truncate() # 删除余下内容
content = content + '\n'
f.write(content.encode()) # 插入指定内容
f.write(rest) # 还原余下内容
break
match_then_insert('test.txt', match='c', content='123')| 方案 | 耗时/s |
|---|---|
| 读进列表后覆盖原文件 | 54.42 |
| FileInput类 | 121.59 |
| seek | 3.53 |
from timeit import timeit
from fileinput import FileInput
def init_txt():
open('test.txt', mode='w').write('\n'.join(['a', 'b', 'c', 'd', 'e']))
def f1(filename='test.txt', match='c', content='123'):
lines = open(filename).read().splitlines()
index = lines.index(match)
lines.insert(index, content)
open(filename, mode='w').write('\n'.join(lines))
def f2(filename='test.txt', match='c', content='123'):
for line in FileInput(filename, inplace=True):
if match in line:
line = content + '\n' + line
print(line, end='')
def f3(filename='test.txt', match='c', content='123'):
with open(filename, mode='rb+') as f:
while True:
try:
line = f.readline()
except IndexError:
break
line_str = line.decode().splitlines()[0]
if line_str == match:
f.seek(-len(line), 1)
rest = f.read()
f.seek(-len(rest), 1)
f.truncate()
content = content + '\n'
f.write(content.encode())
f.write(rest)
break
init_txt()
print(timeit(f1, number=1000))
init_txt()
print(timeit(f2, number=1000))
init_txt()
print(timeit(f3, number=1000))
报错可试试在文件头部添加
# -*- coding: utf-8 -*-或指定 encoding='utf-8'
ceshi.txt文本如下:第一行为空行
爬虫任务报警
01:45:21
scrapyd==》爬虫任务异常死亡报警
hostname: scrapyd-chinabond-1
error_count: Process died: exitstatus=None ,project: chinabond_fast_spider,spider: ah_sina_com_cn,job: 28395818dbcb11e998a3f632d94e247c,pid: 88971,log: data/logs/chinabond_fast_spider/ah_sina_com_cn/28395818dbcb11e998a3f632d94e247c.log,items: None
error_data:
爬虫任务报警
01:45:21
scrapyd==》爬虫任务异常死亡报警
hostname: scrapyd-chinabond-6
error_count: Process died: exitstatus=None ,project: chinabond_fast_spider,spider: shupeidian_bjx_com_cn,job: 04738a5cdbcb11e9803172286b76aa73,pid: 34246,log: data/logs/chinabond_fast_spider/shupeidian_bjx_com_cn/04738a5cdbcb11e9803172286b76aa73.log,items: None
error_data:
爬虫任务报警
01:45:21
scrapyd==》爬虫任务异常死亡报警
hostname: scrapyd-chinabond-6
error_count: Process died: exitstatus=None ,project: chinabond_fast_spider,spider: news_sdchina_com,job: 28e8db4edbcb11e9803172286b76aa73,pid: 34324,log: data/logs/chinabond_fast_spider/news_sdchina_com/28e8db4edbcb11e9803172286b76aa73.log,items: None
error_data:
爬虫任务报警
01:47:20
scrapyd==》爬虫任务异常死亡报警
hostname: scrapyd-chinabond-0
error_count: Process died: exitstatus=None ,project: chinabond_fast_spider,spider: hq_smm_cn,job: 4bdc3af6dbcb11e9a45522b8c8b2a9e4,pid: 111593,log: data/logs/chinabond_fast_spider/hq_smm_cn/4bdc3af6dbcb11e9a45522b8c8b2a9e4.log,items: None
error_data:
爬虫任务报警
01:47:21
scrapyd==》爬虫任务异常死亡报警
hostname: scrapyd-chinabond-6
error_count: Process died: exitstatus=None ,project: chinabond_fast_spider,spider: sichuan_scol_com_cn,job: 71321c4edbcb11e9803172286b76aa73,pid: 34461,log: data/logs/chinabond_fast_spider/sichuan_scol_com_cn/71321c4edbcb11e9803172286b76aa73.log,items: None
error_data:
爬虫任务报警
01:47:21
scrapyd==》爬虫任务异常死亡报警
hostname: scrapyd-chinabond-2
error_count: Process died: exitstatus=None ,project: chinabond_fast_spider,spider: www_mof_Gov_cn,job: 7418dacedbcb11e9b15e02034af50b6e,pid: 65326,log: data/logs/chinabond_fast_spider/www_mof_gov_cn/7418dacedbcb11e9b15e02034af50b6e.log,items: None
error_data:
爬虫任务报警
01:47:21
scrapyd==》爬虫任务异常死亡报警
hostname: scrapyd-chinabond-5
error_count: Process died: exitstatus=None ,project: chinabond_fast_spider,spider: www_funxun_com,job: 4dcda7a0dbcb11e980a8862f09ca6d70,pid: 27785,log: data/logs/chinabond_fast_spider/www_funxun_com/4dcda7a0dbcb11e980a8862f09ca6d70.log,items: None
error_data:
爬虫任务报警
01:49:21
scrapyd==》爬虫任务异常死亡报警
hostname: scrapyd-chinabond-4
error_count: Process died: exitstatus=None ,project: chinabond_fast_spider,spider: shuidian_bjx_com_cn,job: 95090682dbcb11e9a0fade28e59e3773,pid: 106424,log: data/logs/chinabond_fast_spider/shuidian_bjx_com_cn/95090682dbcb11e9a0fade28e59e3773.log,items: None
error_data:
爬虫任务报警
01:51:20
scrapyd==》爬虫任务异常死亡报警
hostname: scrapyd-chinabond-0
error_count: Process died: exitstatus=None ,project: chinabond_fast_spider,spider: tech_sina_com_cn,job: de4bdf72dbcb11e9a45522b8c8b2a9e4,pid: 111685,log: data/logs/chinabond_fast_spider/tech_sina_com_cn/de4bdf72dbcb11e9a45522b8c8b2a9e4.log,items: None
error_data:
爬虫任务报警
01:51:21
scrapyd==》爬虫任务异常死亡报警
hostname: scrapyd-chinabond-6
error_count: Process died: exitstatus=None ,project: chinabond_fast_spider,spider: ee_ofweek_com,job: ff6bd5b8dbcb11e9803172286b76aa73,pid: 34626,log: data/logs/chinabond_fast_spider/ee_ofweek_com/ff6bd5b8dbcb11e9803172286b76aa73.log,items: None
error_data:
爬虫任务报警
01:51:21
scrapyd==》爬虫任务异常死亡报警
hostname: scrapyd-chinabond-6
error_count: Process died: exitstatus=None ,project: chinabond_fast_spider,spider: house_hexun_com,job: ff6dfdacdbcb11e9803172286b76aa73,pid: 34633,log: data/logs/chinabond_fast_spider/house_hexun_com/ff6dfdacdbcb11e9803172286b76aa73.log,items: None
error_data:
爬虫任务报警
01:51:21
scrapyd==》爬虫任务异常死亡报警
hostname: scrapyd-chinabond-2
error_count: Process died: exitstatus=None ,project: chinabond_fast_spider,spider: www_sjfzxm_com,job: 018e7d78dbcc11e9b15e02034af50b6e,pid: 65492,log: data/logs/chinabond_fast_spider/www_sjfzxm_com/018e7d78dbcc11e9b15e02034af50b6e.log,items: None
error_data:
爬虫任务报警
01:53:21
scrapyd==》爬虫任务异常死亡报警
hostname: scrapyd-chinabond-4
error_count: Process died: exitstatus=None ,project: chinabond_fast_spider,spider: news_xianzhaiwang_cn,job: 48d835e8dbcc11e9a0fade28e59e3773,pid: 106476,log: data/logs/chinabond_fast_spider/news_xianzhaiwang_cn/48d835e8dbcc11e9a0fade28e59e3773.log,items: None
error_data:
代码如下:
import os
import re
import JSON
from collections import namedtuple
alert = namedtuple('Spider_Alert', 'alert_time, alert_hostname, alert_project, alert_spider')
path = r'D:\data\ceshi.txt'
g_path = r'D:\data\\'
file_name = r'result.txt'
file_path = g_path + file_name
alerts_list = list()
with open(path, encoding="utf-8") as file:
lines = file.readlines() # 读取每一行
count = 0
time = None
hostname = None
project = None
for line in lines:
if re.search(r'^\d{2}:\d{2}:\d{2}\s*$', line):
time = re.search(r'^(\d{2}:\d{2}:\d{2})\s*$', line).group(1)
if re.search(r'^hostname:\s*(.+)', line):
hostname = re.search(r'^hostname:\s*(.+)', line).group(1)
if re.search(r'project:\s*([^,]+),', line):
project = re.search(r'project:\s*([^,]+),', line).group(1)
if re.search(r'spider:\s*([^,]+),', line):
spider = re.search(r'spider:\s*([^,]+),', line).group(1)
if re.search(r'^error_data', line):
spider_alert = None
spider_alert = alert(alert_time=time, alert_hostname=hostname, alert_project=project, alert_spider=spider)
alerts_list.append(spider_alert)
for element in alerts_list:
print(element[0], element[1], element[3])
with open(file_path, 'a', encoding="utf-8") as file:
file.write(element[0] + "\t" + element[1] + "\t" + element[3])
file.write(' \n')
执行结果如下图:
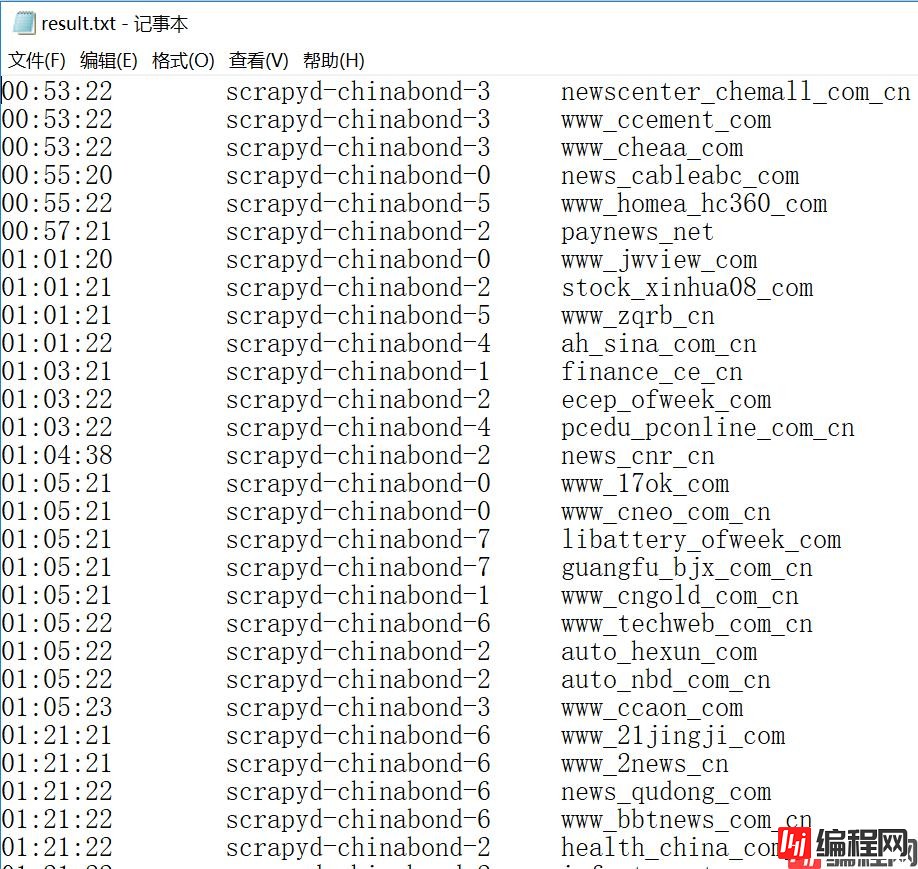
以上为个人经验,希望能给大家一个参考,也希望大家多多支持编程网。
--结束END--
本文标题: Python如何匹配文本并在其上一行追加文本
本文链接: https://lsjlt.com/news/117876.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0