Python 官方文档:入门教程 => 点击学习
目录UnicodeDecodeError: 'utf-8' codec can't decodpython的编码声明UnicodeDecodeError: &
有一次报错如下:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb3 in position 0: invalid start byte
编码问题:
f = open(txtPath,'r',encoding='utf-8')改为:
f = open(txtPath,'r',encoding='gbk')即可print(f.read())又有一次读取CSV文件时报错:
import pandas as pd
content = pd.read_csv('news.csv',encoding='utf-8')
print(content.head())报错如下:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xba in position 0: invalid start byte
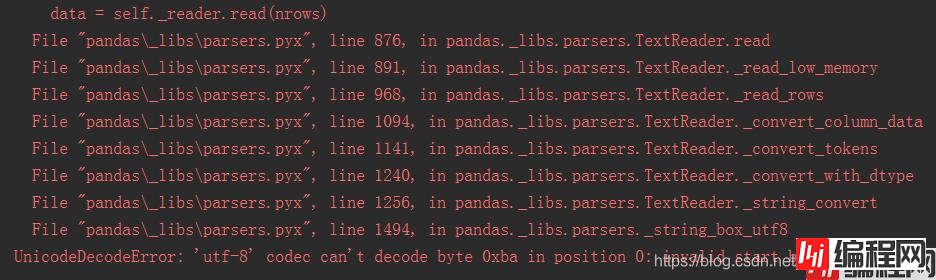
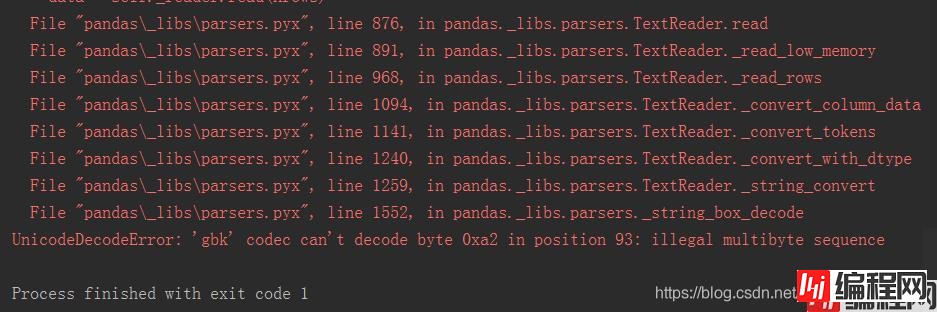
这里我将编码问题 utf-8 改为 gbk,还是报错。。。。报错如下:
UnicodeDecodeError: 'gbk' codec can't decode byte 0xa2 in position 93: illegal multibyte sequence
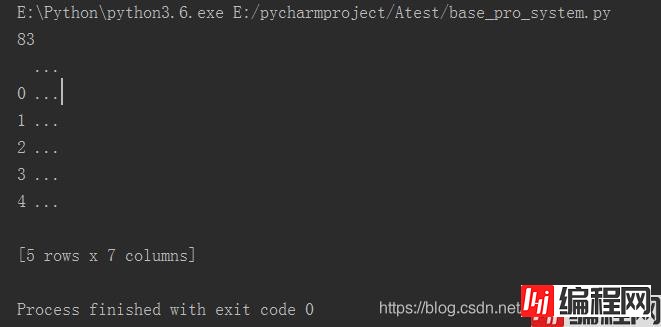
最后当我把程序改为:
import pandas as pd
content = pd.read_csv('news.csv',encoding='gb18030')
print(content.head())即读取成功:
这类问题都是文件编码问题,至于文件到底是什么类型的编码,谁都不知道,只能用最常用的编码格式一个去试一下。这里我将文件编码格式改为gb18030,是偶尔看到有这种格式试出来的。。。。不知道现在有没有软件能够检测文件是什么类型就好了。。
通常,在python 文件,尤其是包含中文的python文件中,需要说明你的Python源程序文件使用的编码;如果未声明,程序默认使用ascii码来写,此时,书写中文的话python解释器一般会报错。
常见的编码声明:
# coding=utf-8
# coding:utf-8
# -*-coding=utf-8-*-
# -*-coding:utf-8-*-注意:
①coding后面使用:或=都可以。
②:或=与coding之间不能有空格,而:或=与编码之间有没有空格均可。
③编码声明一般放在python文件开头(第一行或第二行)
以上为个人经验,希望能给大家一个参考,也希望大家多多支持编程网。
--结束END--
本文标题: 解决编码问题:UnicodeDecodeError:'utf-8'codeccan'tdecod
本文链接: https://lsjlt.com/news/117821.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0