Python 官方文档:入门教程 => 点击学习
前几天学习了Yolov5,当我想实际将Yolov5实际运用的时候却不知道怎么办了 然后我决定对Yolov5的detect.py修改为可以直接调用的函数 因为我只需要识别图片,所以我将
前几天学习了Yolov5,当我想实际将Yolov5实际运用的时候却不知道怎么办了
然后我决定对Yolov5的detect.py修改为可以直接调用的函数
因为我只需要识别图片,所以我将detect.py修改为只要传入一张图片他就可以返回坐标
ps:我这里用的是Yolov5(6.0版本)
# Copyright (c) 2022 guluC
#导入需要的库
import os
import sys
from pathlib import Path
import numpy as np
import cv2
import torch
import torch.backends.cudnn as cudnn
#初始化目录
FILE = Path(__file__).resolve()
ROOT = FILE.parents[0] # 定义YOLOv5的根目录
if str(ROOT) not in sys.path:
sys.path.append(str(ROOT)) # 将YOLOv5的根目录添加到环境变量中(程序结束后删除)
ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
from models.common import DetectMultiBackend
from utils.datasets import IMG_FORMATS, VID_FORMATS, LoadImages, LoadStreams
from utils.general import (LOGGER, check_file, check_img_size, check_imshow, check_requirements, colorstr,
increment_path, non_max_suppression, print_args, scale_coords, strip_optimizer, xyxy2xywh)
from utils.plots import Annotator, colors, save_one_box
from utils.torch_utils import select_device, time_sync
#导入letterbox
from utils.augmentations import Albumentations, augment_hsv, copy_paste, letterbox, mixup, random_perspective
weights=ROOT / 'yolov5s.pt' # 权重文件地址 .pt文件
source=ROOT / 'data/images' # 测试数据文件(图片或视频)的保存路径
data=ROOT / 'data/coco128.yaml' # 标签文件地址 .yaml文件
imgsz=(640, 640) # 输入图片的大小 默认640(pixels)
conf_thres=0.25 # object置信度阈值 默认0.25 用在nms中
iou_thres=0.45 # 做nms的iou阈值 默认0.45 用在nms中
max_det=1000 # 每张图片最多的目标数量 用在nms中
device='0' # 设置代码执行的设备 cuda device, i.e. 0 or 0,1,2,3 or cpu
classes=None # 在nms中是否是只保留某些特定的类 默认是None 就是所有类只要满足条件都可以保留 --class 0, or --class 0 2 3
agnostic_nms=False # 进行nms是否也除去不同类别之间的框 默认False
augment=False # 预测是否也要采用数据增强 TTA 默认False
visualize=False # 特征图可视化 默认FALSE
half=False # 是否使用半精度 Float16 推理 可以缩短推理时间 但是默认是False
dnn=False # 使用OpenCV DNN进行ONNX推理
# 获取设备
device = select_device(device)
# 载入模型
model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data)
stride, names, pt, jit, onnx, engine = model.stride, model.names, model.pt, model.jit, model.onnx, model.engine
imgsz = check_img_size(imgsz, s=stride) # 检查图片尺寸
# Half
# 使用半精度 Float16 推理
half &= (pt or jit or onnx or engine) and device.type != 'cpu' # FP16 supported on limited backends with CUDA
if pt or jit:
model.model.half() if half else model.model.float()
def detect(img):
# Dataloader
# 载入数据
dataset = LoadImages(source, img_size=imgsz, stride=stride, auto=pt)
# Run inference
# 开始预测
model.warmup(imgsz=(1, 3, *imgsz), half=half) # warmup
dt, seen = [0.0, 0.0, 0.0], 0
#对图片进行处理
im0 = img
# Padded resize
im = letterbox(im0, imgsz, stride, auto=pt)[0]
# Convert
im = im.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
im = np.ascontiguousarray(im)
t1 = time_sync()
im = torch.from_numpy(im).to(device)
im = im.half() if half else im.float() # uint8 to fp16/32
im /= 255 # 0 - 255 to 0.0 - 1.0
if len(im.shape) == 3:
im = im[None] # expand for batch dim
t2 = time_sync()
dt[0] += t2 - t1
# Inference
# 预测
pred = model(im, augment=augment, visualize=visualize)
t3 = time_sync()
dt[1] += t3 - t2
# NMS
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
dt[2] += time_sync() - t3
#用于存放结果
detections=[]
# Process predictions
for i, det in enumerate(pred): # per image 每张图片
seen += 1
# im0 = im0s.copy()
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(im.shape[2:], det[:, :4], im0.shape).round()
# Write results
# 写入结果
for *xyxy, conf, cls in reversed(det):
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4))).view(-1).tolist()
xywh = [round(x) for x in xywh]
xywh = [xywh[0] - xywh[2] // 2, xywh[1] - xywh[3] // 2, xywh[2],
xywh[3]] # 检测到目标位置,格式:(left,top,w,h)
cls = names[int(cls)]
conf = float(conf)
detections.append({'class': cls, 'conf': conf, 'position': xywh})
#输出结果
for i in detections:
print(i)
#推测的时间
LOGGER.info(f'({t3 - t2:.3f}s)')
return detections
path = 'C://Users//25096//Desktop//yoloV5//yolov5//yolov5-master//data//images//zidane.jpg'
img = cv2.imread(path)
#传入一张图片
detect(img)我这里用的是Yolov5自带的zidane.jpg

这是输出结果
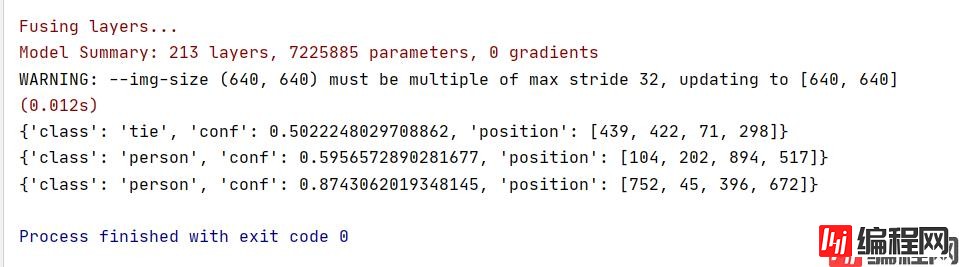
class:标签的名称
conf:置信度
position:xywh ( 左上角x,左上角y,宽,高 )
总结
到此这篇关于如何将Yolov5的detect.py修改为可以直接调用的函数的文章就介绍到这了,更多相关Yolov5的detect.py直接调用函数内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: 如何将Yolov5的detect.py修改为可以直接调用的函数详解
本文链接: https://lsjlt.com/news/117173.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0