Python 官方文档:入门教程 => 点击学习
目录二进制数据结构Struct函数与Struct类打包解包字节序指示符缓冲区二进制数据结构Struct 在C/C++语言中,struct被称为结构体。而在python中,struct是一个专门的库,用于处理字节串与原
在C/C++语言中,struct被称为结构体。而在python中,struct是一个专门的库,用于处理字节串与原生Python数据结构类型之间的转换。
本篇,将详细介绍二进制数据结构struct的使用方式。
struct库包含了一组处理结构值得模块级函数,以及一个Struct类。格式指示符将由字符串格式转换为一种编译表示,这与处理正则表达式得方式类似。
这个转换会耗费一些资源,所以创建一个Struct实例并再这个实例上调用方法时,只完成一次转换,往往会更高效。
Struct支持使用格式指示符将数据打包为字符串,另外支持从字符串解包数据,格式指示符由表示数据类型的字符串和可选的数量及字节序指示符构成。
下面,我们来打包一个元组,将其转换为16进制字节序列,示例如下:
import struct
import binascii
values = (2, 'lyj'.encode('UTF-8'), 3.8)
s = struct.Struct('I 3s f')
packed_data = s.pack(*values)
print("原值:", values)
print("格式指示符:", s.fORMat)
print("大小:", s.size, 'bytes')
print("打包值:", binascii.hexlify(packed_data))
运行之后,效果如下:
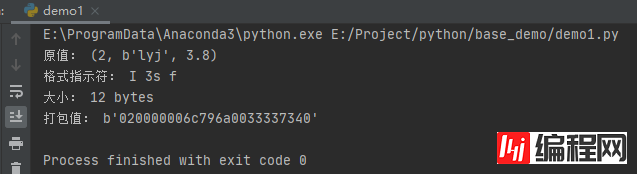
这里的格式指示符为“I 3s f”。前面介绍array数组时,我们已经列出过一个表格。其中I标识一个整型或长整型,3s表示3个字节字符串(lyj),f表示浮点数。
struct库使用unpack()可以从打包的表示数据中抽取数据,这里直接复制上面的打包值,进行测试。示例如下:
import struct
import binascii
packed_data = binascii.unhexlify(b'020000006c796a0033337340')
s = struct.Struct('I 3s f')
unpacked_data = s.unpack(packed_data)
print("解包值:", unpacked_data)
运行之后,效果如下:

虽然使用unpack()解包基本会得到相同值,但浮点数的值有微小的差别。
默认情况下,值会使用原生C库的字节序(endianness)来编码。Struct的字节序指示符如下表所示:
| 代码 | 含义 |
|---|---|
| @ | 原生顺序 |
| = | 原生标准 |
| < | 小端 |
| > | 大端 |
| ! | 网络顺序 |
示例如下:
import struct
import binascii
values = (2, 'lyj'.encode('UTF-8'), 3.8)
endianness = [
('@', '原生顺序'),
('=', '原生标准'),
('<', '小端'),
('>', '大端'),
('!', '网络顺序'),
]
for code, name in endianness:
s = struct.Struct(code + ' I 3s f')
packed_data = s.pack(*values)
print("格式化字符串:", s.format, ' for ', name)
print("大小:", s.size, 'bytes')
print("打包:", binascii.hexlify(packed_data))
print("解包:", s.unpack(packed_data))
运行之后,效果如下:
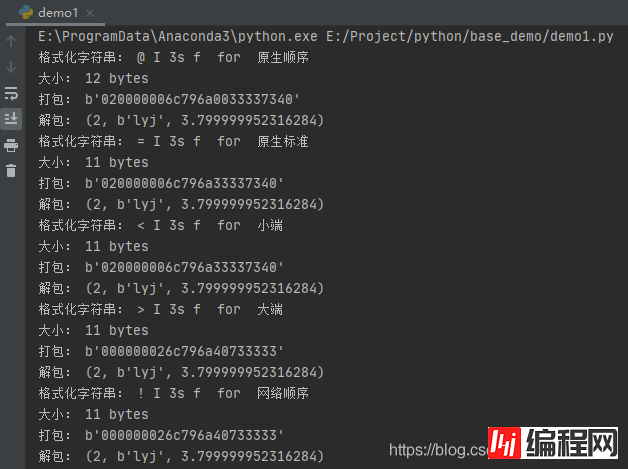
如果想改变字节序来编码,如上面代码所示,只需要改变格式串中提供一个显式的字节序指令,就可以很容易地覆盖这个默认选择。
通常在强调性能的情况下或者向扩展模块传入或传出数据时才会处理二进制打包数据。
为了避免为每个打包结构分配一个新缓冲区所带来的开销,通常情况下,我们使用pack_into()和unpack_from()方法支持直接写入预分配的缓冲区。
示例如下:
import struct
import binascii
import ctypes
import array
values = (2, 'lyj'.encode('UTF-8'), 3.8)
s = struct.Struct('I 3s f')
print("原始值:", values)
b = ctypes.create_string_buffer(s.size)
print("打包之前(缓冲区的值):", binascii.hexlify(b.raw))
s.pack_into(b, 0, *values)
print("打包之后(缓冲区的值):", binascii.hexlify(b.raw))
print("解包:", s.unpack_from(b, 0))
a = array.array('b', b'\0' * s.size)
print("打包之前(缓冲区的值):", binascii.hexlify(a))
s.pack_into(a, 0, *values)
print('打包之后(缓冲区的值):', binascii.hexlify(a))
print("解包:", s.unpack_from(a, 0))
运行之后,效果如下:
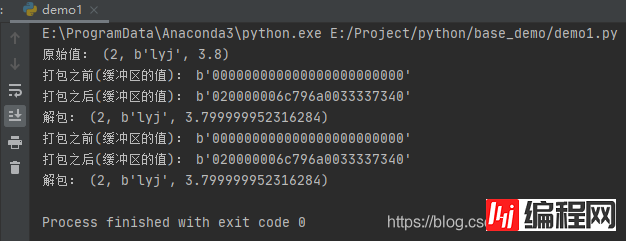
这里通过两种方式,创建缓冲区。其中size属性用于指出缓冲区需要的大小。
到此这篇关于Pytho 二进制数据结构Struct的具体使用的文章就介绍到这了,更多相关Pytho 二进制数据结构Struct内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: Python二进制数据结构Struct的具体使用
本文链接: https://lsjlt.com/news/10973.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0